
4 月 13 日,中国科学院科技战略咨询研究院与腾讯研究院在北京联合举办了“2017 人工智能:技术、伦理与法律研讨会”,会议邀请了中国科学院科技战略咨询研究院院长潘教峰、腾讯研究院院长司晓、中国科学院学部科学规范与伦理研究与支撑中心李真真、复旦大学计算机学院肖仰华等数十位人工智能领域专家和学者,共同探讨当前人工智能技术发展中面临的和带来的伦理、法律、社会经济影响等问题。
期间,肖仰华教授做了主题为“未来人机区分——基于语言认知的智能验证码”的分享,雷锋网根据现场录音、PPT、以及采访内容整理成文。

雷锋网按:肖仰华,复旦大学计算机科学技术学院,副教授,博士生导师,上海市互联网大数据工程技术中心副主任。主要从事大数据管理与挖掘、知识库等方向的研究工作。
为什么需要验证码?
首先,非常高兴有机会跟大家来分享我在人机区分方面一些思考和工作。我主要从事计算机研究,近几年关注的比较多的是人工智能领域的相关研究。在研究不断开展的过程中我们越来越强烈地意识到一个问题,那就是我们现在已经很难区分计算机背后到底是人还是机器,这就很容易造成一个非常尴尬的局面,我们到底是在跟人交互还是在跟机器交互?我最近听到一个笑话,有一个人在婚恋网站上谈朋友,最后发现是一个机器人在跟他聊天。所以人机区已经成了非常重要的一个议题。
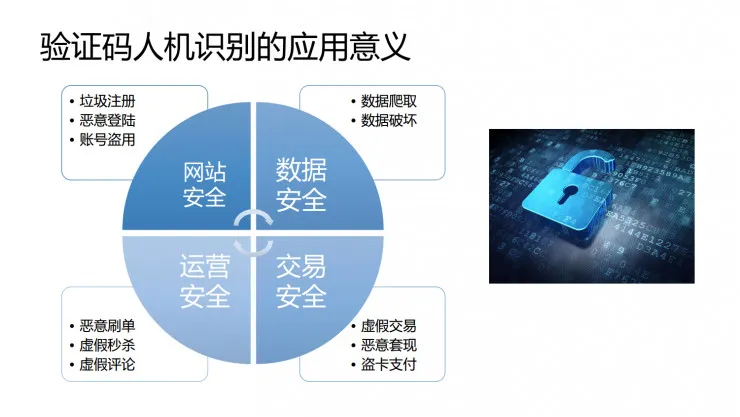
到底怎样才能有效地区分互联网的另一端是机器还是人呢?我们计算机领域给出的方案就是验证码。这个小小的验证码是所有人最熟悉却又最为陌生的事物,几乎所有人都使用过验证码,但是验证码背后的机制与原理却并不为人所熟知。为什么在登录系统的时候需要输入验证码?事实上就是为了做人机区分,系统需要知道是真实的人还是机器在获取我们的数据,是真实的人在购买还是机器在刷单,是真实的人在购票还是机器在抢票。所以验证不单单是一件事关乎整个人类身份和尊严的事情,同时也是具有重大安全意义的问题,而且已经在保证网站安全、数据安全、运营安全和交易安全等方面发挥了巨大的作用。
网站安全:垃圾注册、恶意登录、账号盗用
数据安全:数据爬取、数据破坏
运营安全:恶意刷单、虚假秒杀、虚假评论
交易安全:虚假交易、恶意套现、盗卡支付
为什么传统的验证码已经不安全了?
但是最近几年人工智能技术的发展,特别是大数据推动下的人工智能技术的发展,已经使得机器的感知能力达到甚至超越了人类的水平,这个技术趋势的直接结果是什么呢?就是基于感知能力的人机验证的方式已然失效。
先简单回顾一下近几年人工智能发展的趋势。如果想寻求一个简单原因来解释为什么最近几年人工智能风风火火,或者人工智能为何这么兴旺,那么这个原因应该是大数据时代的到来,没有大数据不可能有人工智能如今的发展。我们现在有着越来越庞大的数据规模,越来越完整的数据生态,这是人工智能跨越式发展的前提和基础。此外,大数据时代我们的硬件水平呈现出指数级增长的趋势。现在我们拥有前所未有的计算能力,而这个计算能力仍然在飞速增长。正是计算能力的飞速增长以及大数据的迅速积累为人工智能的跨越式发展奠定了基础。大数据时代为人工智能的发展可以说带来前所未有的数据红利。
人工智能近期的发展,尤其体现在以深度学习为代表的机器学习方面,近几年我们看到深度学习在很多领域取得了前所未有的突破。深度学习之所以能够迅猛发展,其实就是因为有了海量的标注数据,所以大家看到最近很多深度学习方面突破大都来自像 Google、Facebook 这样的大公司,为什么?因为他们有海量的数据。
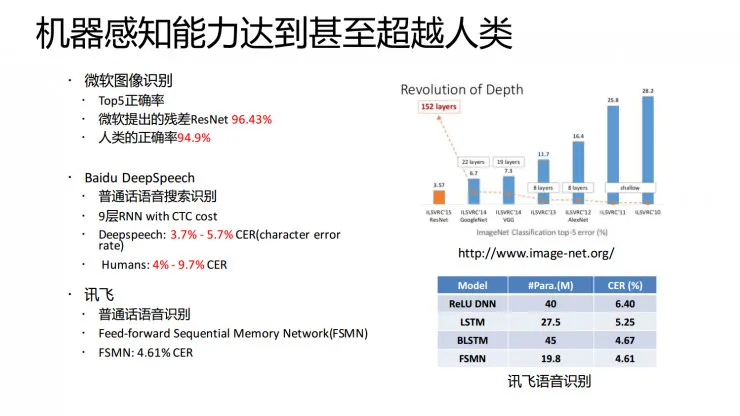
以深度学习为代表的人工智能技术快速发展的一个直接结果就是:机器在某些方面的感知能力方面已经达到甚至超越了人类水平。比如微软在图像识别方面的准确率达到 96.43%,人类只有 94.9%。也就是说人去看一个图像都不一定有机器看得准。百度的 DeepSpeech 平台的语音识别错误率已经降到 3.7%-5.7% 之间,而人类的错误率仍有4%-9.7%,所以在语音识别方面机器已经超越人类。以深度学习为代表的人工智能技术已经让机器在视觉、听觉方面的感知能力大幅进步,在视听这些基本的感知能力层面人类已经没有什么好值得骄傲的。现在我们身边的机器,其感知能力事实上比我们强。

这个技术趋势的直接结果是什么呢?就是大家最为熟悉的图片验证方式已经彻彻底底失效。这些结果不是来自什么顶尖的实验室,而是来自某大学的硕士生课程作业。对于 Complex Image 这种相对复杂的验证码,机器识别的准确率高达 98%-99.8%。在人机对比实验里,人大概 10 个里面要错 3 个,机器 10 个里面只错了 1 个,基本上是机器完败人类。互联网上的很多平台目前还严重依赖这类验证码,以为能够防止刷单、刷票等等,但是事实上并不安全。
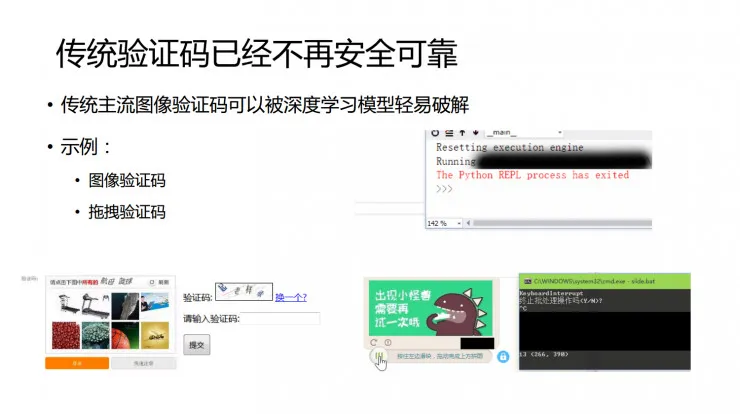
传统验证码可以说已经十分不安全。比如上图中拖拽验证码,已经可以通过自动化程序来破解。而且这样的破解程序也不需要什么高手才能做出来的,这里演示的是我实验室同学用来练手的破解项目。先通过图像处理算法找出方块的目标位置,由于方块区位特征明显,很容易找到。之后设计一个带参数刚体运动的轨迹模拟模型,参数随机化之后模拟真人的轨迹拖动,从而实现破解。
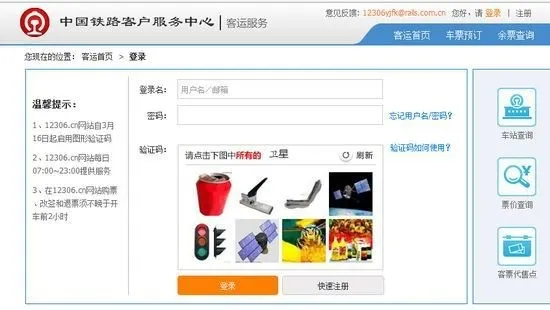
12306 图形验证码
除了拖拽验证码,据说难倒了很多购票者的 12306 的验证码其实也可以被破解。12306 的验证码本质上在做图片中的对象识别,因此可以利用已经相当成熟的 ImageNet 相关算法,而 ImageNet 相关算法对图片中的实体识别已经到达很高的准确率。

谷歌图形验证码
此外,就连谷歌图片验证码也可以通过类似的方法被破解。谷歌图片验证码识别的主要难度在其类型多样:有时是选择图片中招牌部分,有时是框出图上的汽车。但是对于每一类验证都是有相应的破解方法,特别是对于基于图片中物体识别的验证码,可以用类似 ImageNet 的相关算法破解。
如今,几乎所有的主流的传统验证码都已经被破解,传统的验证方式早已不安全。
未来属于基于语言认知的智能验证码
出路何在?我的观点很明确,那就是基于语言认知的人机区分,也就是考验机器语言认知能力的智能验证码,这将会是未来一段时间内的重要选择。

这类验证码的基本思路是,让机器去读一段文本,然后回答问题。有点类似语文里面的阅读理解。比如说让人或机器读这么一段文本:“某人从复旦大学哲学系毕业,现在是郑州大学公共学院的导师”,然后问“这个人的在职单位是什么?”人或机器需要点击包含答案的文本片段才能通过验证。这类验证本质上是在考验人或机器的文本理解能力。对于人而言极为简单,但是对于机器而言,这是很有难度的。比如刚才的例子,机器有可能回答复旦大学,也有可能回答郑州大学,但是我们都知道只有郑州大学是他的在职单位。机器要回答这个问题必须理解这段话讲的是什么,必须能够区分郑州大学和复旦大学一个是学习单位,一个是在职单位。换言之,机器必须具备像我们人一样的认知能力,才能破解这样的验证码。但是很遗憾,机器毕竟没有像人一样受过十几年的教育,也就无从具备这样的文本理解能力。当前机器在认知能力方面,尤其在语言认知方面,至少在未来一段时间窗口内还难以企及人类水平,可能再过二十年、三十年或许能达到这个水平,但是这是二、三十年之后的事情了。
我们来看看当前人工智能到底有什么问题。当前人工智能的问题集中表现在理解常识的能力和推理能力非常有限。什么叫常识?几乎所有人都知道,以至于大家都不说的知识,叫常识。比如说太阳是从东边升起的,人是会走但是不会飞的,鱼是会游但是不会走的,鸡是有两条腿,兔子是有四条腿的,类似于这样的知识,就叫常识。机器普遍缺乏这种常识,因为机器现在所学到的知识都是从文本里面学习来的,但是常识是人人都知道的,所以文本里不会被提及,那就意味着数据里不会存在,因此机器就无从学习。所以机器现在是普遍缺乏常识的。
我们再想想人为什么具有这种常识?人的常识是通过自身与世界的交互而产生的,我们从胚胎开始就在积累常识,就在感受时间的流逝,感受空间的存在。当你是一个很小的小朋友时你就知道调皮会挨打,所以你就在体验有因必有果。时间感、空间感、因果感,都是通过身体经年累月的体验而形成的。人类要想在短短几十年时间内,把这种通过体验而得到的知识以一种填鸭式地方式灌输给机器是很困难的。
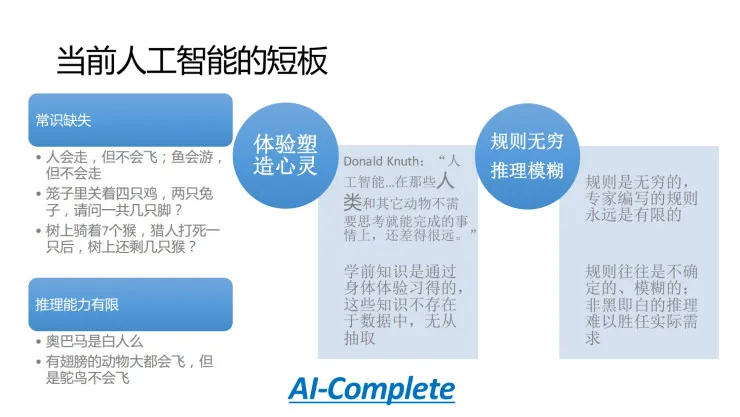
另外一方面是推理能力有限。我曾经问过很多在线机器人:“奥巴马是白人吗?”,很多机器的回答都不准确。事实上,这些机器背后的知乎库中都存有“奥巴马是黑人”这样的事实,但是从“奥巴马是黑人”推理出“奥巴马不是白人”,对机器来说就非常困难。另一方面人类的推理是能够容忍很多异常的。比如说“有翅膀的鸟会飞”,大部分情况下是这样的,但是你也会发现一些特例,比如企鹅有翅膀不会飞,鸵鸟有翅膀也不会飞。机器只能胜任非黑即白的推理,异常容忍的推理对于机器而言仍很困难,但对于人而言确极为简单。这里提及的难题目前有一个不成熟的说法,被统称为 AI-Complete 问题,也就是说这些问题要等到机器智能达到人类水平的时候才能解决。这明显是个悖论,但从这一说法可以看出这类问题有多难。
基于这些认识,我们提出并实现了一种基于知识图谱的验证码。我们有一个目前世界上最大的中文百科知识库 CN-DBpedia。利用自有的知识库,自动生成自然语言问题,自动判定答案。所有的问题全是自动生成的,理论上可以生成数以亿计的问题。同时我们平台可以自动判定答案,但是机器是不知道答案的,机器必须通过理解才能知道答案。我们的验证码还具有交互友好的特性,只要轻轻一点就能通过验证。
那么我们的系统是如何知道答案的呢?其实在 CN-DBpedia 里存储的是 2 亿多的结构化事实,比如(复旦大学,所在地,上海),基于这些结构化事实,我们通过深度学习模型自动生成自然语言问题,也就是说我们的系统在提问时是已经知道答案的。
如果要破解我们的验证码需要以下几个技术储备:
识别图片里面的文字以获取问题
理解文本以及问题,进而生成答案
使用一个成熟的涵盖数亿关系知识库的 QA 系统
因此,破解这个验证码至少比破解目前流行的图片验证码要难(上述第 1 步)。文本理解以及知识库上的 QA (雷锋网(公众号:雷锋网)注:特别是能回答数以亿计知识的 QA),是目前正在研究和探索的问题,还没有成熟的解决方案。因此,至少目前,在机器语言认知能力尚未达到人类水平之前,我们的验证码是难以破解的。
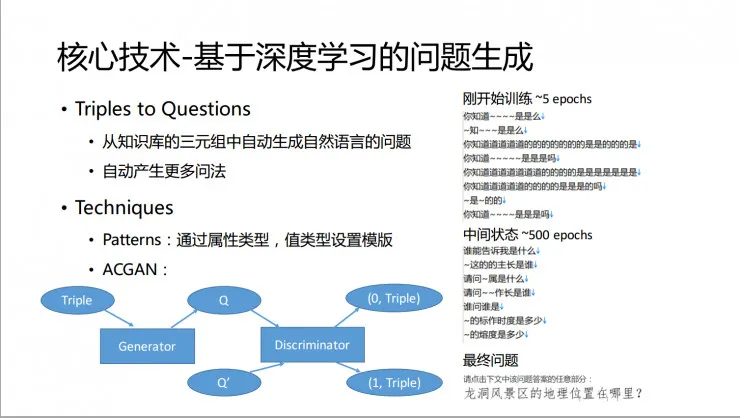
我们的核心技术是从知识库里面结构化知识自动生成自然语言问题。我们提出了基于生成对抗网络(GAN)的从结构化三元组生成自然语言问题的模型,从而实现问题的自动随机生成。理论上有数以亿计的候选问题空间,一个真实的用户是不会两次碰到相同的问题的,从而保证了验证的安全可靠。

同时,为了进一步提高验证的安全性,降低对于真实用户的验证门槛,提高对于机器验证的门槛,我们也考虑到了分级验证。如果是首次登录的普通用户,就采用简单的验证,如果是高频访问的账号就用复杂验证,比如说像淘宝的刷单,我们就可以通过组合验证的方式,将机器拒绝于门外。

组合验证实际上就是通过组合文本理解、图片识别、轨迹识别等不同验证码方式来增加机器破解的难度,从而实现更强的安全验证。

我们的验证码终极形式是常识验证。比如说:“上海 GDP 仅次于日本东京,问 GDP 第一的城市是谁?”答案应该是“东京”,回答这类问题本质上是在考验机器的常识理解能力。常识理解问题可以说是人工智能皇冠上的问题。
基于语言认知的智能验证码具有非常多的应用场景,包括电商平台防抢单、用户注册防僵尸、航旅春运防刷票、发表评论防水军、信息检索防爬取、论坛博客防撞库等等。不仅如此,这种验证码还有很多超越人机区分的未来商业应用价值:
阈下知觉广告(subliminal advertising):阈下知觉是低于阈限的刺激所引起的行为反应。虽我们感觉不到,但却能在潜意识中形成记忆,引导之后决策。
众包数据标注: 验证码是用户登陆的必经之路,谷歌已经对接了图片分类问题实现图片样本的自动标注、物体识别等。
访问权限控制:类似于门卫,在加入某些小众群体的时候,能起到区分作用,只有知道特定群体知识的人才能回答验证进入系统。