
最近,一篇名为《Using Deep Learning and Google Street View to Estimate the Demographic Makeup of the US》的论文发布到了 arxiv.org 上,作为这篇论文的联合作者之一,李飞飞在她的推特上向公众推荐了这篇论文。这篇论文主要论述了如何将谷歌街景车搜集来的机动车辆数据,结合机器学习算法,从而估算出本地区人口的特征和组成,甚至这一地区居民的政治倾向。
下面是这篇论文的一些节选内容,原文地址为:https://arxiv.org/abs/1702.06683。由雷锋网编译。
几千年来,统治者和政策制定者进行全国人口调查,用来搜集人口数据。在美国,最细致的人口调查工作就是“美国社区调差”(ACS),由美国普查局执行,每年花费 10 亿美元和 6500 人以上的人力。这是一个劳动密集型数据搜集过程。
最近几年,计算方法崛起成为解决社会科学领域问题的有效方法。比如用 Twitter 上的数据预测失业率、使用书里的大量文本分析文化等等。这些例子表明,计算方法可以促进社会经济领域的研究发展,最终可以详细、实时地分析人口趋势,并且成本很便宜。
我们的研究表明,结合公共数据和机器学习方法,可以得到社会经济数据和美国人的政治倾向。我们的流程里,针对几个城市耗费少量人力来搜集数据,然后用来预测全美的状况。
具体而言,我们分析了由谷歌街景汽车在 200 个城市里搜集来的 5000 万张图片。我们的数据主要是关于机动车辆,因为 90% 的美国家庭都拥有至少一辆汽车,而且人们对汽车的选择受到多种人口因素的影响,包括家庭需求、个人偏好和资金等。
基于深度学习的 CNN 计算机视觉框架,不仅能够在复杂的街景下识别出汽车,还能鉴定出一系列汽车特征,包括材料、型号和年份。对于一个未经训练的人来说,汽车之间的不同是难以发觉的。比如,同一型号的汽车,不同年份的在尾灯有微小变化(比如 2007 产的 Honda Accord 和 2008 年产 Honda Accord)。然而,我们的系统就能够将汽车分成 2657 类,每张图片的分析时间只需 0.2 秒。该系统可以在 2 周时间里对 5000 万张图片分类,而一个专业的人类分类员,假设他每张需要 10 秒时间,将会花费 15 年的时间完成这个任务。
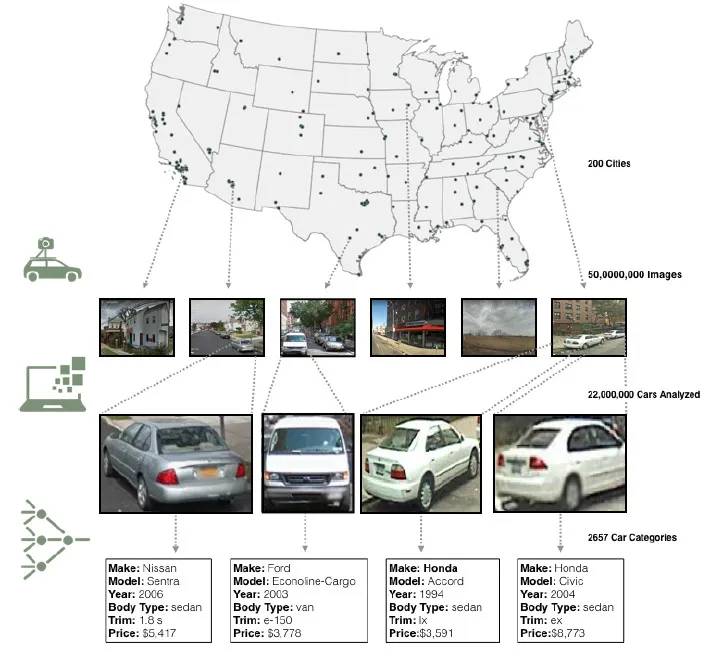
利用谷歌街景汽车搜集来 5000 万张图片,我们使用图像识别算法(Deformable Part Model)来学习自动搜集汽车图片。搜集每一辆汽车图片后,我们部署 CNN 模型,用来进行物体分类,来判定每一辆车的材料、型号、车型和年份。然后,我们根据城镇名字分类数据库,划分到两个数据库里。第一个是"训练库",包含了所有名字以A、B、 C 开头的地区,这个数据库包括了 35 个城市,训练产生模型;第二个是“测试库”,包括所有名字以D、Z为开头的地区,这个数据库用来提升模型。
我们总共搜集了 2200 万辆(占全美汽车总数8%)汽车的数据,用来准确估算这个地区的收入、种族、教育和投票程式(voting pattern)。结果显示出的关系出人意料的简单和有力。比如,如果在一个城市里 15 分钟的车程中,遇到的轿车数量高于卡车数量,那么这个城市倾向于在下届大选中投票给民主党(88% 几率);反之则倾向于投票给共和党(82%)。我们的结果表明,自动系统监测使用良好的空间分辨率,能够接近实时地监测人口趋势,可以有效地辅助劳动密集型的调查方法。