
对于经常使用PC聆听音乐的发烧友来说,使用音乐播放软件的时间一定不会少,虽然现在是在线播放软件大行其道的时代,但作为发烧友硬盘里收藏的高品质无损音乐肯定很多,各位烧友有没有注意过音频播放软件设置界面当中的输出设置部分,不知各位烧友平时是否会自定义设置输出参数,这些看似无关紧要的参数事实上对音频系统的影响还是有的,尤其是各位烧友用PC连接HiFi系统的时候,这些细节就更应该注意了。
合理的设置这些输出参数可以获得更加纯净、低延迟的声音,当然在聆听音乐时对于延迟的需求还是很低的,但纯净度就很重要。
在Windows系统下,目前主流的音频输出方案主要是DirectSound、MME、Kernel Streaming、WASAPI和ASIO这几种,大多数的播放软件都采用了DirectSound方案进行音频处理输出,DirectSound也是Windows下目前最为成熟的API,它为程序员提供许多功能以及出色的兼容性,使用它开发程序的音频部分相当便捷,但也正因为这点也使得它变成了回放高品质音频时的一个缺陷,所以就有不少专业录音软件和定位发烧的播放软件使用了其它方案输出。至于这些平时不被用户关注的方面有什么奥秘,小编就将在本文当中与各位烧友介绍、分享一下关于这些输出方案之间的事。
为何需要 对音频重采样的缘由
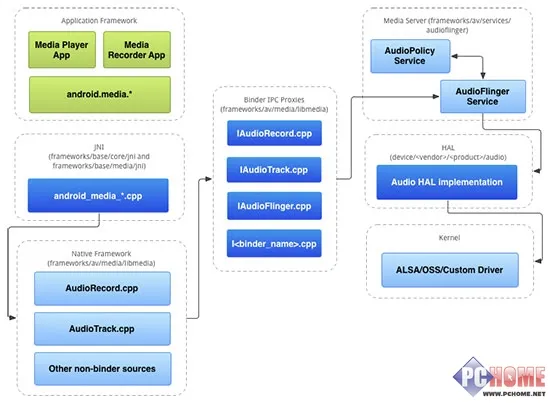
Android系统音频架构,AudioFlinger Service当中可对音频进行重采样
在正式开始介绍之前我们不妨先来回顾一下盛传的Android系统下48KHz音频的重采样问题,这个问题可以说是前两年Android音质最令人诟病的一个方面,使得Android音质成为了短板,众所周知Android是基于Linux开发的,Android绝大部分的架构都是基于Linux的,但也有相当多的部分进行了修改,可能是Google出于开发者的角度考虑,为了能有出色的兼容性才强制48KHz的音频重采样到44.1KHz,这个问题直到12年开始才被各大厂商着手解决。
要说重采用问题真的有那么严重吗?实际上对听感的影响还真不是太大,完全是在可接受的范围内,但如果将这个题摆到高品质的无损音乐上,就是一个颇为严重的问题了,一旦经过重采样引入了失真后,无损音频就完全失去了意义。那么Android系统下的重采样问题Windows下是否也会发生?毫无疑问Windows下当然是有这个问题的,只是我们不需要等待厂商介入解决,只需要通过自己的手动设置即可解决。事实上,重采样并不能算是问题,如果这真的是个BUG的话那厂商早就该着手处理了,重采样更多的是为了硬件的兼容性考虑的,可以极大的方便开发者和用户的日常使用,声卡硬件通常支持的规格是有限的,例如一些高端声卡硬件可以支持24bit位深和96KHz采样率的PCM,但低端的集成声卡就不行了,所以就选择了通过重采样来对音频进行规格化,使任何硬件都可以播放,通常来说一般的用户是很少熟悉这些规格的,所以重采样就选择了后台默默的进行,而不会告知用户。
3颇有讲究 Windows下音频输出方式
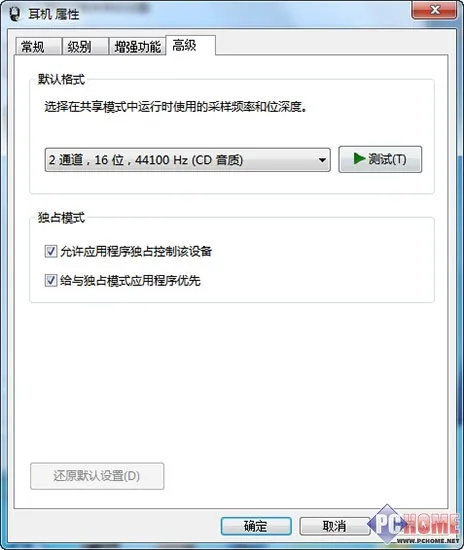
耳机属性高级选卡
在Windows系统控制面板的声音设置当中的高级选卡我们就可以看到声音默认格式的下拉列表,系统默认会将可以支持的规格显示在这里,如果用户选择了其中某一个规格后,系统会将所有不是该规格的音频在播放时自动重采样转换到这个规格。此外,现在有很多声卡还支持许多音效,Dolby Home Theater、THX、SRS等层出不穷,这些音效都可以为用户带来出色的影音和游戏体验,但如果是无损音频的话,这东西就变成了添加剂,影响了原汁原味的聆听体验。所以,通过合理的设置避开重采样和音效还是很有必要的。可能有网友会说在控制面板里设置一下不就可以了,但这样是指标不治本的,还会带来不少麻烦。
支持各种音效的声卡越来越多
抛开专业的录音软件不说,Windows下专注音频播放的软件还是有的,目前,知名度比较高的要属foobar2000、AIMP3和大难不死的Winamp,发烧友用的最多的应该是foobar2000了,小编这里就拿foobar2000来举个栗子吧。foobar2000虽然在烧友中知名度很高,但小编还是来简单介绍一下吧,该软件可以简称FB2K,最大的特色是采用了模块化的开发理念,软件虽然没有开源但却开放了API,第三方开发者可以为其开发插件来增加FB2K的功能,也正是因为这些插件使得FB2K默认简陋的界面可以变的华丽无比,也可以为其添加无数功能,可玩性相当大。而下图FB2K支持如此多的输出方式正是通过插件来实现的。
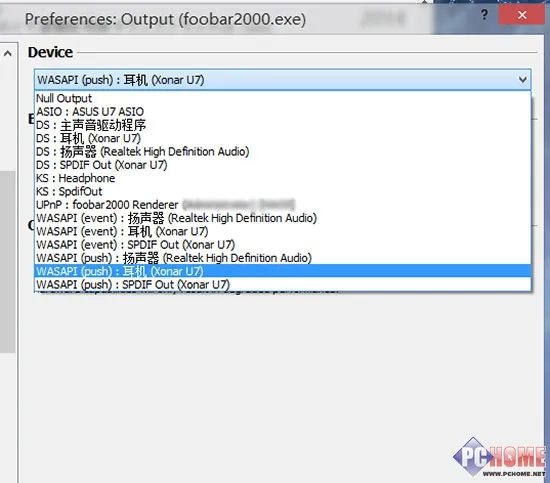
foobar2000支持的输出方式颇多
4哪有不同 DS输出和ASIO区别差异
FB2K的默认输出方式是DS,DS就是DirectSound的首字母缩写,DirectSound是DirectX的一部分,而DirectX则是被很多游戏玩家所熟知,DirectX是由微软创建的多媒体编程接口,由C 编程语言实现,遵循COM。DirectX是Windows平台下最通用最成熟的接口,多媒体软件大多采用了DirectX API。通过DS输出可为开发者和用户带来许多便利,FB2K下使用DS输出则是可以实现渐响、淡出等功能,还能支持声卡所带的音效,所以小编并不是推荐各位网友使用DS输出来播放无损音乐。

ASIO标准的LOGO
ASIO同样是一个比较熟悉的名词,相信很多人肯定有听说过。ASIO全称Audio stream input output,是德国Steinberg公司所提出的,主要目的是为了解决PC音频方面的输入输出的延迟问题,由于系统自带的音频输出方式一般延迟都大于10ms,虽然10ms并不算长,但仍旧是无法满足专业领域的严苛需求的,于是ASIO便针对延迟问题进行了深度设计,使其输出输入延迟能够低于10ms,甚至还能低于1ms,完全能够满足专业音乐制作的需求,聆听音乐选择该方法输出,主要目的肯定不是降低延迟了,而是为了能避开系统重采样、音效以及规格化处理,由于ASIO低延迟设计,所以在输出过程当中不会引入任何处理,但ASIO缺点也是很明显的,ASIO是需要驱动层面的支持,并不是所有声卡都带有ASIO驱动,虽然有第三方驱动,但效果可能不尽如人意。
5目的相同 WASAPI和KS输出新旧两代
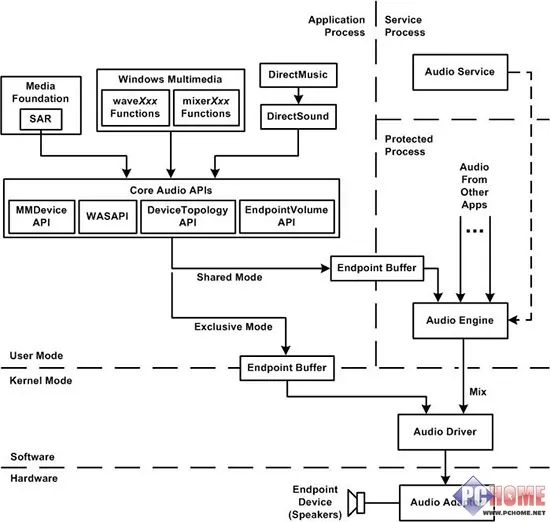
Windows音频输出架构
WASAPI全称Windows Audio Session API,是微软Vista之后所引入的,Vista当中微软重写了音频架构,提出了一套新的通用架构,Universal Audio Architechture(UAA),并增加了全新的WASAPI,WASAPI为程序开发者提供了两种模式,共享模式(Shared Mode)和独占模式(Exclusive Mode),使用独占模式时可以和ASIO输出达到相似的效果,此时声卡被某一程序独占,只有该程序能使用声卡,其他程序均不能占用声卡,而且独占模式时,系统不也会干涉音频流,直接将其交给声卡驱动进行输出,声卡自带的音效以及系统重采样均不会起到作用,可输出纯净的声音,但FB2K使用WASAPI输出的缺点也是有的,由于声音不经过系统规格化,因此设定时必须符合硬件规格才能播放,超出规格的音频是无法播放的,使用时还需有一定的音频相关知识。
专业的录音软件当中也可见到WASAPI的身影
KS(Kernel Streaming)输出是一种比较老旧的输出方式,主要使用在没有WASAPI的XP以及之前版本的Windows系统当中,KS最早出现在Windows 98当中,它允许程序员能够为多媒体设备实时的处理音频流,效果和ASIO、WASAPI类似,都可以避开系统对音频的音效处理或是规格化,从Vista开始KS已经逐渐被WASAPI所取代了,目前支持的软件并不多。
6原汁原味 音频输出方式总结

HiFi系统细节很重要
其实为何要花费大量时间去研究和设置音频播放软件的输出方式目的相当简单,就是要避开系统对音频流的干涉,使播放软件可以输出最为纯净的声音,还原无损音频真正的本质,说实话无损音频和高码率有损音频在实际的听感表现差别很少,往往只有在使用顶级的音频系统时才会在细节处有所体现,但对于HiFi来说这可能正是需要去追求的地方,不能因为这样一点点的忽视而在无损音频当中引入了失真,所以在软件层面做好功课这是很有必要的。
多媒体在 PC 上向来都不是个 EASY 的事情。
如何将声音输送到声卡,也是一个不 EASY 的事情。让我们来 8 一 8 声音输出 API 的那些事。
第一个出现的声音 API 是 OSS。UNIX 系统的发明,被 BSD 和 Linux 发扬广大,当然,也是 Linux 让它死翘翘的。
OSS 借用了 UNIX 里 “一切都是文件” 的概念,把声卡模拟成一个 /dev/dsp 设备,多块声卡就是 dsp0 dsp1 ...
要播放声音? 打开 dsp 设备。往里面 write 数据就可以了。 设置 比特率? 用 ioctl 设置即可。
最简单的接口,也是最没用的接口。因为应用程序完全没法对声音的播放进行控制。OSS 是个阻塞的接口, write 后,要声音播放完毕才返回。显然很糟糕,因为在 write 和下一次 write 的微小时间间隔内,声音出现了不连续。 解决办法就是使用异步的 write 。 write 完了,用 ioctl 轮询,看还剩下多少数据。注意,是轮询。 轮询到还剩下不到 1ms 就播放玩了,马上再 write 一个 buffer 过去。 这就是 OSS 接口下的播放。
同 OSS 同时期出现的 Windows 上的接口就是 WaveOut 了。 同 OSS 没有啥本质区别。 WaveOutWrite 也是阻塞的 。。。。。 同直写 /dev/dsp 设备有区别么? 基本没有。
Linux 那群开发者很活跃,也是最早把 UNIX 玩成 PC OS 的。当然 OSS 这个声音接口实在是太简单了,于是他们搞了一个 ALSA 接口。
ALSA 先进了一些,有了 PLL 接口。除了可以向声卡发送数据,还可以为数据附带时钟信息。注意,可以为数据附带时钟信息。意味着你可以不用精确的等待到一个时间再送出数据,而是指定一块数据在指定的时间播放。还可以设定播放到某个 byte 的时候,产生时钟信号通知程序,好让程序能继续准备下一块 buffer 继续播放。
然后 asla 又提供了一个高级的接口, libasound.so , libasound.so 可以读取 /etc/asound.conf /usr/share/alsa/alsa.conf ~/.asound.conf 配置文件,还可以加载各种插件,插件又可以通过配置文件配置。相当的高级。可以说, alsa 是为专业的音频应用准备的。
不论是 OSS 还是 ALSA , 在民用声卡上都有一个致命的缺点: 他们不支持混音。OSS 和 ALSA 都只是声卡的接口。如果声卡本身不支持硬件混音,那么程序就只能独占声卡。表现为只能有一个程序出声。
好在 alsa 有一个补救措施,那就是 libasound.so 。 alsa 不推荐直接使用 alsa 的内核接口编程,而是使用 libasound.so 的接口。 如果使用了 libasound.so 的接口,用户可以配置一个 叫 “dmix” 的插件。然后把 dmix 模拟出来的声卡作为默认声卡。 大家都输出到 dmix , dmix 再收集多个程序的声音,一起混音然后输出给硬件。
这个问题看似解决了。实际上没有解决。 受限于alsa的接口, dmix 的实现质量相当的糟糕。首先,dmix 为了混音,强制重采样。重采样导致了音质的劣化。其次, dmix 没有 C/S 结构。通过共享内存协作完成混音和共享声卡,一个程序的 dmix 出问题,会导致所有正在发声的程序崩溃。
同期, Windows 折腾出了一个 DirectX ,这个接口集里,有一个叫 DirectSound 的子集。
那么 Windows 怎么解决声卡独占问题? 答案是 Windows Audio 这个服务。OSS 是个驱动,应用程序通过 /dev/dsp 直接使用这个驱动。 alsa 也是驱动,应用程序被鼓励使用 libasound.so 间接使用这个驱动。
Windows 也有一个驱动,叫 Kernel Stream 。但是,应用程序不被鼓励使用。反而使用 DirectSound 和 WaveOut 这样的高级接口。通过 DirectSound 和 WaveOut ,将数据输出到 Windows Audio 这个服务,这个服务完成声音混音,再通过 Kernel Stream 输出给声卡。DirectSound 同时还有个独占模式,可以绕过混音,直接输出给声卡。但就多数程序而言,都需要经过系统混音。
在 Vista 及以上的系统里, M$ 又搞了一个 WASAPI 这个接口。。。并让 DirectSound 通过 WASAPI 间接出声。这直接劣化了 DS 的音质。并在API文档里宣布 DS 过时 。。。 M$ 变脸可真快啊。。。
除非直接使用 kernel stream ,否则其他 API 下,声音都经过系统混音。如果你的声音不是系统混音所使用的那个采样率,重采样是不可避免的。 在 Windows 里,声音属性里可以设置系统混音所使用的采样率。默认设置是 16bit/44100hz。也就是说,非 44100hz 的声音都被系统重采样了。
同 Windows 一样, alsa 的 dmix 插件也是默认 16bit/44100hz 的采样率,非这个采样率就被重采样后再混音。
不可避免的带来音质的劣化。
ALSA 的另一个缺点,在使用了多个声卡后(蓝牙和 HDMI 普及了啊),也开始暴露。那就是不能动态切换输出声卡。我希望我带上蓝牙耳机后,声音能从扬声器直接转移到耳机里播放。
但是 ALSA 的先天缺陷导致无法实现这个功能。播放器必须重新打开蓝牙声卡 。。。 也就是说,把切换输出的责任全部交给播放器实现。播放器可以实现,问题是所有的播放器都必须实现。另一个问题是,用户必须到各个播放器下依次调节。非常麻烦。
呆着解决ALSA固有缺陷的目的, PulseAudio 又出现了。
PulseAudio 解决办法也是提供一个混音服务。混音服务后台执行,独占 声卡的访问权限。其他程序要播放声音的,都需要将声音数据交给 pulseaudio 。由 pulseaudio 执行混音。
pulseaudio 将 A 程序的 48000hz 重采样到 32000hz , B 的 44100 重采样到 32000hz , 混音后输出给蓝牙耳机。
同样是系统混音, pulseaudio 支持动态采样率调节。依据当前声卡支持的采样率和当前程序提交的数据,动态修改内部混音的采样率。尽量减小不必要的重采样过程
我们看看 Windows 如何解决这个问题:
因为系统混音无法避免,一群发烧声音的人开发了 ASIO , 注意,这个不是 Boost.Asio , 而是 Audio Stream IO 的缩写。 ASIO 是一个非 M$ 产的声音驱动。使用 ASIO 输出,意味着声音数据绕过了一切 M$ 产的代码,直接到达声卡(原装驱动也得卸载, lol, 禁用 windows audio 服务, lol ) 。当然,也要付出 ASIO 只能支持有限的几款声卡的代价。一些发烧友认为这样可以提升音质。。。。。。我只能说,呵呵。
因为从 Vista 开始, Windows Audio 服务也开始支持 pulseaudio 类似的 “动态采样率” 了。因为系统重采样导致的声音劣化,已经不存在了。
顺便提醒一下列位: google 这个傻逼搞的 android 不使用 pulseaudio , 自己搞了个 audiofinger , 不支持动态采样率, 还是会强制重采样到 44100hz 。 我只能说, Google 的一群傻逼。