
文章来源:赛先生微信公众号
“熟读唐诗三百首,不会作诗也会吟”。见识海量范文之后的机器真的可以通过“暴力学习”来取代人类的工作吗?实际上,优秀的译文应该具有灵活性和创造性,寄望于通过“大数据统计”路线来推进机器翻译的想法是不能指望的,因为这种翻译过程不包括对语句内容及其所属的言语行为的理解,这一重大缺陷也不能通过对该技术的改进而克服。
最近谷歌汉译英改用了神经网络技术。做了测试的人们有两点共识,一是译文质量比以前的技术要好很多,二是离人的翻译水平还差得很远。有趣的是,在此基础上专家们对机器翻译的前景却有截然相反的估计。乐观主义者认为,照这个速度发展下去,机器早晚会接管所有翻译工作;悲观主义者则认为,根据机器翻译所暴露的缺陷可以看出,这个技术再怎么发展也有好多因素是没办法掌握的。
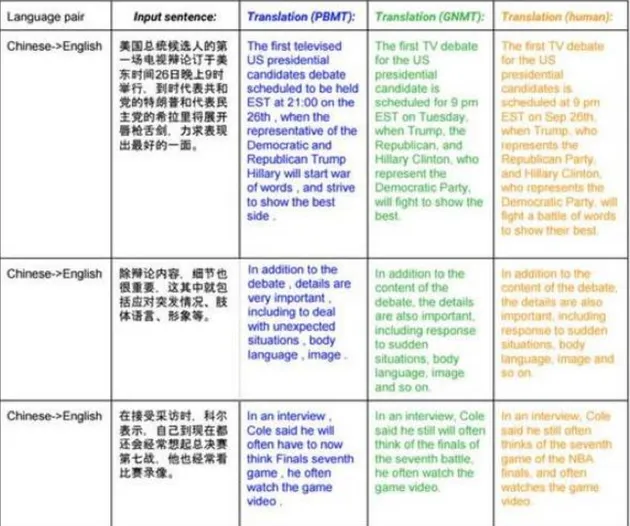
这让我们想起了“半瓶水”既可以说成“半满”也可以说成“半空”。一般说来,对于一个正在发展中的技术而言,两种说法都有道理:一方面,现存一些缺陷是会被该技术的进一步发展所弥补的;但另一方面,任何一个技术都有其根本局限,所以不是所有的问题都一定会在这个技术的框架中被解决。要预测机器翻译的发展空间,必须具体分析现有技术对翻译过程的刻画。
机器翻译的流派
参考资料[1]介绍了机器翻译领域及其中的主要技术流派。翻译是人工智能研究中最早被考虑到的实际应用之一。在人们发现计算机可以被用来对语言进行编码处理以后,很快就有人想到可以用它来进行翻译工作。和人工智能的其它子领域相似,这里的故事也是跌宕起伏。
在开始时,受当时语言学界主流(乔姆斯基理论)的影响,机器翻译主要走的是“基于规则”的路线。简而言之,这就是为每种语言整理出一本“词典”和一本“语法书”,然后在两种语言之间建立词和句子的水平上的对应关系。以英译中为例,这样一个翻译过程对每个英文句子进行下列处理:
(1)分析其语法结构以及其中每个词的角色(主语、谓语、宾语等等)。在这个过程中,主要考虑词类(名词、动词、形容词等等),而不考虑每个词的意思。
(2)分析其语义,即把句中英语词汇及其语法关系表示成独立于语言的概念关系。
(3)把这些概念关系用汉语重新表达出来。
在这些步骤中所遵循的规则都是语言学家所总结出来的。尽管语言学家和人工智能工作者付出了巨大的努力,这条路径并没有导致预想的进展并达到实用水平。这主要是因为人类的语言,即所谓“自然语言”,实在是太复杂了。和人工构造的数学语言或计算机语言不同,自然语言的使用非常灵活,其结果是几乎所有语法规则均有例外,几乎所有的词汇都有多个意义,因而不同语言的语句或词汇之间也就不存在符合规则的对应关系。
部分地出于对“基于规则”的方案的失望,自然语言处理研究者们逐渐转向了“基于统计”的路线。这个办法是把大量的实际出现的语句整理成“语料库”,然后用统计的办法来发现其中的某些规律性,比如说词与词之间的相继频率(如在“这”之后“是”出现的概率)或可替换性(如把语料库里句子中的“狗”换成“猫”后,有多少结果还在语料库中)。以此来实现语句预测、补全、纠错等功能。把统计方法用到机器翻译当中,就是用大量的已有翻译范文(比如联合国文件)为训练数据来生成一个翻译系统。这种翻译技术直接在两个语言的词句之间建立对应关系,而在此过程当中不依赖于人工整理的语法规则和词典。当然,这个办法要求的数据量和计算量都非常大,但这些现在已不是不可满足的。
谷歌的神经网络翻译系统是统计方法的一种具体的实现方式。下面这个出自谷歌网站的动图简单表示了这个系统将一个中文句子翻译成英语的过程。首先,一个“编码网络”将逐字加长的输入字串表示成一系列数值向量。然后一个“解码网络”依照这些向量逐词生成一个英语句子。在解码过程中,系统对各个向量的“关注”程度是不同的,这就表现为两个网络节点之间的连线有浓有淡,而且随翻译的进展而改变。
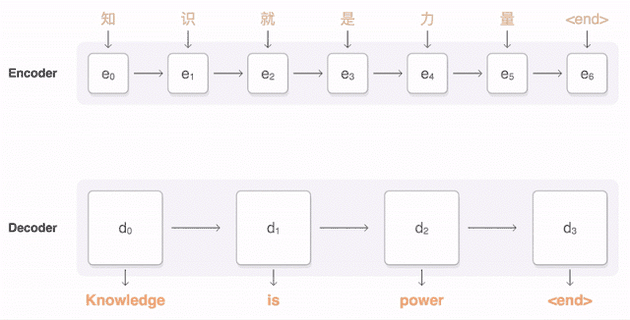
这两个神经网络都是用大量语料训练出来的,即通过反复调整参数,它们“记住了”这两种语言各语句之间的对应关系,并可以据此推广到以前没见过的句子。对每个输入语句,系统实际上是在计算不同输出语句的概率,并最终选取可能性最高的那个。参考资料[2]是谷歌团队关于这个系统工作原理的技术报告。和以往同样基于统计的翻译系统来比,这个系统的优势之一就是把“短语到短语”的翻译拓展到“句子到句子”的翻译,因此改善了译文的可读性。另一个创新是把没见过的词切分成片段,因此可以根据其前后缀、词根等来决定如何翻译。
最近,谷歌翻译团队又取得了新进展。现在同一个翻译模型可以处理多语种,并实现了一定程度的“迁移学习”。比如说该模型的训练语料是在英语-日语之间和英语-韩语之间,但训练完成后可以被用于日语-韩语之间的翻译,尽管该模型从未被直接在这两个语言之间被训练过。这种功能被称作“零数据”(zero-shot)翻译,但这个说法有误导之嫌,因为翻译仍然是基于海量数据的,尽管不是直接关于某次翻译所涉及的两种语言间的对应关系。
统计翻译能走多远
对不关心技术细节的读者,我们只需说统计翻译的基本思路是“照猫画虎”,即把每句话按照最接近、最常见的方式处理,正所谓“熟读唐诗三百首,不会作诗也会吟”。在系统见识了海量范文之后,用这个办法的确可以完成大量翻译工作。随着语料的积累、算法的优化、硬件性能的提高等可以预见到的进展,机器翻译的能力必定会进一步提高。
但这不意味着统计翻译可以完全取代人的翻译工作。具体到谷歌神经网络翻译来说,下面两个基本预设其实就划出了这个技术的边界:(1)“翻译是把一种语言中的语句对应到另一种语言中的语句”;(2)“在诸个可能的翻译结果中,选择那个在训练语料中最常出现的”。
这两个预设对简单翻译任务来说是合理的,但翻译活动中的很多其它因素被完全忽略了,例如背景知识、上下文、作者(说者)的意图、读者(听者)的接受能力、文体的一贯性、情感色彩等等。在任何需要考虑这些因素的场合,神经网络翻译的局限性就暴露出来了。
这些局限性是不能被神经网络翻译的进展所克服的,因为它们来自这个技术的基本前提,而否定了这些前提的发展就不能再算是这个技术的发展,而应当说是另一个技术了。某些小改动可以缓解一些困难,如对训练样本加标记,把翻译单位从单句扩大到多句等等,但这些都不足以彻底解决问题。神经网络翻译的上述问题可以总结为一点:这种翻译过程没有包括对语句内容及其所属的言语行为的理解。
翻译和理解

这就扯出个大麻烦来:怎么才算“理解”?对这个概念不同的人显然有不同的理解。谷歌翻译团队就说,既然他们的模型可以把一句话翻译成多种语言,这就说明该模型真正理解了这句话的含义。这个标准对人说来是足够好了,但人工智能的历史说明了对人合适的标准对机器未必合适。如果某系统对一句话的翻译很准确,但既不能回答有关的简单问题,也不能以此影响自己的行为,那说它“理解了这句话”就很牵强。
本文不试图对“理解”这个概念做全面、深入的分析,而希望通过两个简单的例子说明统计翻译的局限性。这两个不恰当的名词翻译我以前都提到过。
在《人工智能危险吗?》中,我提到阿西莫夫的“Three Laws of Robotics”应当译作“机器人三律令”而非“机器人三定律”,因为这里的“law”更接近于康德的“道德律令”,而完全不像牛顿的“三大定律”。译成“定律”会使有些读者误以为它们是所有机器人都必然会遵循的法则,而根据阿西莫夫的本意,它们是机器人的设计者强加的约束,因此完全可能被修改甚至背离。实际上阿西莫夫在他的后期作品中又加了一条更根本的律令作为对那三条的修正。
在《图灵测试是人工智能的标准吗?》中,我提到“chatbot”应当译作“聊天程序”而非“聊天机器人”。这个英文单词是由“chat”(“聊天”)和“robot”(“机器人”)的后半部分组成,所以译作“聊天机器人”不是毫无来历。总的来说,“bot”是指和机器人有一些相似的“拟人”程序,但在英文中没人会把“chatbot”误解为一种“robot”,而在中文中,“聊天机器人”完全可能被误解成“机器人”的一种。随着把“bot”译作“机器人”成为时尚,后者将不再特指与通用计算机相区别的专用计算装置。这就是为什么“实体机器人”、“物理机器人”等说法开始出现,以强调它们和纯软件的差别。实际上更好的选择是保留“机器人”一词的“实体”、“专用硬件”的本意,而用其它词汇称呼拟人化的程序,因为这些程序和其它程序的区别并不明晰,而且在所有重要的意思上(商业宣传除外)都没有理由被称为“机器人”。
上述例子说明,在翻译过程中的候选对象常常是需要从多个方面比较和斟酌的,而绝不仅仅是算出现概率这么直截了当。尽管“约定俗成”的确是翻译的一个重要原则,但绝不是唯一的原则。实际上“具体情况具体分析”应当被看作一个更重要的原则。这就是说要试图把握要翻译的内容“在此时此地”是什么意思,而不仅仅是它“在一般情况下”是什么意思。优秀的译文应该具有灵活性和创造性,而这不是“统计路线”所能提供的。
第三条路线
我前面提到的问题远非鲜为人知,而是更接近于有目共睹。但是,除非有更好的技术出现,对这些问题人们除了容忍或抱怨也没什么好办法。
现在大部分研究者仍是希望在“统计路线”的内部解决自然语言处理问题。出于前面解释的理由,我对此不抱希望。统计技术的确能给我们相对简单的自然语言处理工具,但这些工具的局限性也是命中注定的。
另一个显而易见的可能性是在自然语言处理中把“基于统计”的技术和“基于规则”的技术相结合。这条路线会取得一定的进展,但仍不可能彻底解决这两个技术的基本设定中的“先天缺陷”,更不要说还要解决使二者相互协调的难题。
我自己的研究目标是建立一个通用智能系统(见《你这是什么逻辑?》等专栏文章),这自然就涉及到自然语言的处理。因为在我的系统中自然语言的作用不是核心性的,而是边缘性的(尽管也很重要),这方面的具体工作近年来才刚刚开始。我的基本想法和初步结果在参考文献[3]中有介绍。在这里只把和前述两条路线的主要不同点列出来:
不把“自然语言处理”作为一个相对独立的功能模块,而是作为系统的推理和学习机制对言语经验的加工。这就是说对语言材料的处理和对其它材料(感知、运动、概念等等)的处理是基本一样的。
不循“语法-语义-语用”的次序进行语言理解,而是反过来以“目标制导”的方式分析意义(见《“意思”是什么意思?》),并用语法知识协助复杂意义的分析。
不假定一个独立、完整、确定的语法系统,而是允许语法知识、语义知识、语用知识混合存在于各个不同的抽象水平上的概念之中,并主要靠系统自身从经验中习得这些知识。
所有知识,包括语言知识,都只是一定程度上为“真”(见《证实、证伪、证明、证据:何以为“证”?》),但知识的习得和使用更接近于推理,而不是统计。
这条路线在语言学中更接近于“认知语言学”的传统。尽管目前我们的结果还没到能实际应用的程度,但有理由认为这条路线有可能在自然语言处理上(包括翻译)走得更远,因为它更接近人学习和使用语言的实际过程。具体到翻译来说,这就要求系统通过学习掌握词语的一般译法,但在翻译过程中考虑到前述那些被统计翻译所忽略的因素,通过推理来确定每句话应该怎么译。在这个过程中,“理解”体现为把翻译内容与系统的概念系统相联系,尤其是找到其“前因后果”,即作者(说者)为什么要这么写(说),并以此希望在读者(听者)心中产生什么效果。以这种“理解”为基础,系统试图用另一种语言实现尽可能类似的效果。这种对翻译的理解和“规则路线”与“统计路线”均有根本不同。
但纵使是这条路线取得了完全的成功,也不会使得所有的翻译失业。像我在《计算机将拥有“常识”?还有很多关要闯》中所解释的那样,即便一个计算机系统具有了通用智能,它的经验也不会和人的完全一样,因此它的概念和信念不会有和人一样的内容。这种差异必定会体现在翻译作品之中。对某些材料(如文学作品),我们大概还是喜欢人的翻译,尽管机器翻译可能也不错。这就像外国人学中文很难完全达到中国人的水平(中国人学外文也同样),因为到后来差异主要是来自于经历和文化,而不是语言知识和技巧。这类差异可不是靠智力可以弥补的。
总而言之,计算机系统会逐渐越来越多地接管翻译们的工作,但不会在这个领域里完全取代人。实际上这个结论可以推广到很多其它领域。人工智能必定会造成就业结构的重大调整,但在那些密切依赖人类经验的领域,机器是不会完全取代人的。
参考资料
[1] Yorick Wilks, Machine Translation: Its Scope and Limits, 2009th edition, Springer, 2008
[2] Yonghui Wu, et al。, Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, arXiv:1609.08144[cs.CL], 2016
[3] Pei Wang, Natural Language Processing by Reasoning and Learning, in Proceedings of the Sixth Conference on Artificial General Intelligence, pages 160-169, 2013