
AMD在并购ATI以后,需要同时兼顾CPU、GPU两个事业部,在过去的几年之中也仅仅是表现平平。不过今年可谓是AMD意气风发之年,锐龙横空出世,以多核、性价比打得Intel措手不及,无奈之下Intel只能匆忙地祭出全新Core i9系列处理器。在GPU市场上,虽然年初AMD已经发布了一系列的RX 500,但是在高端显卡上依旧缺席,等的就是Vega架构显卡。在历经多次Vega吹风会、计算卡/专业卡发布会后,RX Vega游戏卡终于要在7月30日发布。在发布前,我们先来谈谈AMD Vega架构显卡背后的一些变革。

按照AMD显卡发展路线图,Vega显卡本应该在今年初就要退出的,但由于某种原因才推迟到Q3季度,中间没有新品的空档就让仍是Polaris架构的RX 500系列顶上,原本RX 500系列显卡相比RX 400系列只是提升了频率,人们升级购买的欲望不是太充分。幸好RX 500系列显卡“生得逢时”,遇上了第二波挖矿热潮,RX 560以上级别的显卡一卡难求。

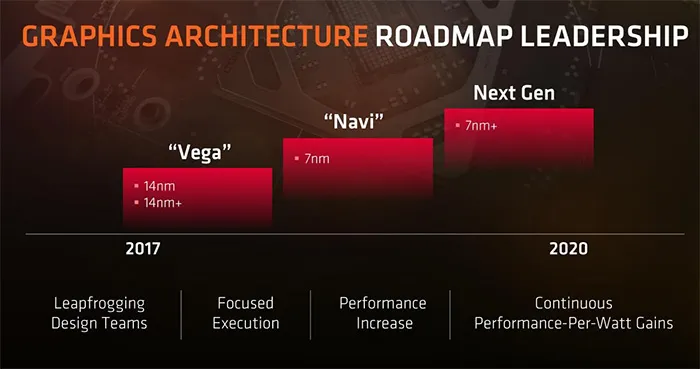
AMD GPU发展路线图
14nm FinFet制程:
根据AMD之前公布的显卡路线图,这一代Vega显卡核心将会使用14nm FinFET工艺制造,其实和之前Polaris架构核心制程差别不大,代工方依然是AMD亲密小伙伴GlobalFoundries格罗方德,而14nm工艺技术转让方是韩国三星半导体。
半导体制程工艺对于芯片性能、功耗有着根本性的影响,按照Polaris的14nm工艺官方资料,可以帮助显卡核心电压降低了150mV,从而功耗降低了30%,所以Polaris架构使用的14nm工艺相比28工艺能提升70%的每瓦性能比,即便是这样RX 480/580依然逃不掉“电老虎”的称号。
新旧两代显卡架构对比图:
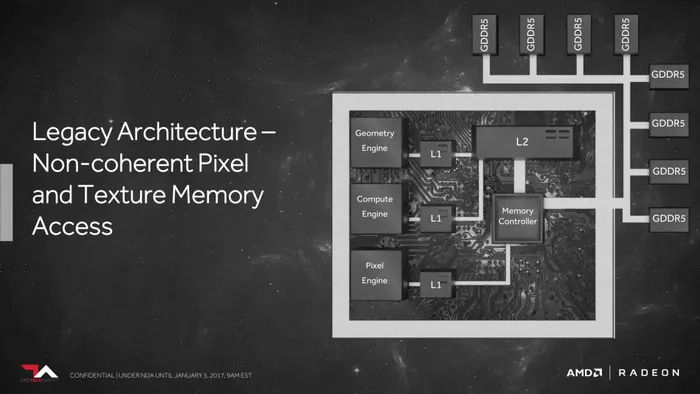
Polaris显卡架构示意图
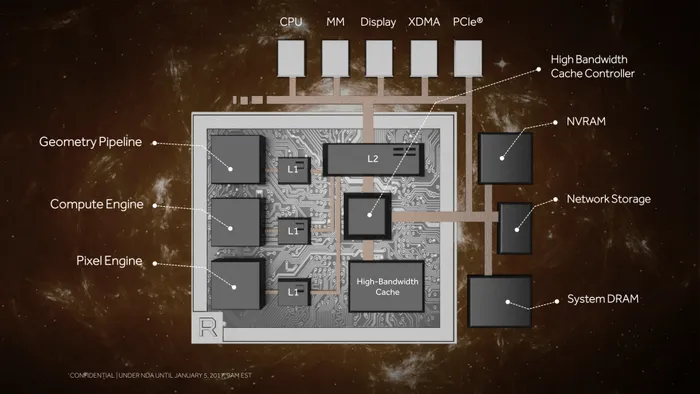
Vega显卡架构示意图
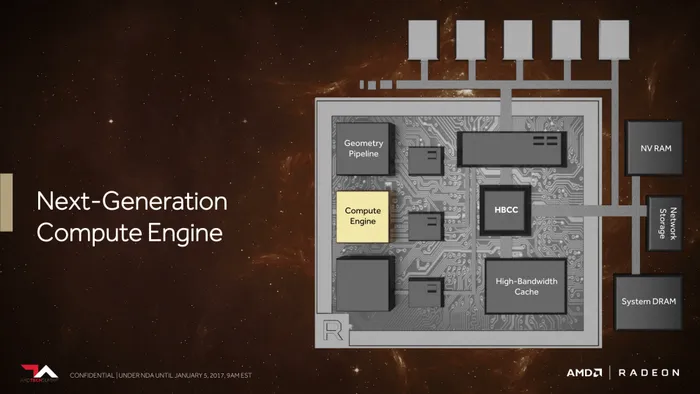
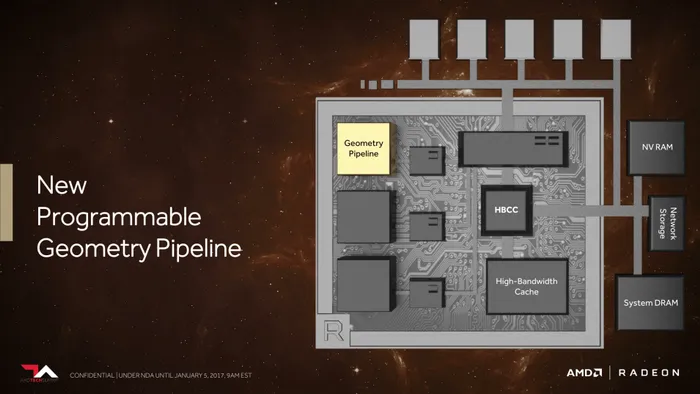
早前AMD曾经召开过几次的Vega架构显卡吹风会,透露了Vega显卡的四大特性:高带宽缓存控制器、下一代计算单元NCU、高级像素引擎、新一代几何渲染引擎。这次我们的内容也会围绕这四大亮点来解说。

新一代显存架构:HBM 2 HBCC
虽然AMD在Fiji核心上已经率先采用了HBM显存,当时Fiji核心一经公布,就引发了业界的一番讨论热潮,原来显存还能这样玩,HBM直接和GPU核心集成在同一块基板上,大大地节省了PCB面积,显卡能做得非常小(R9 Nano就是例子),而且减少了信号传输延迟。不过当时Fiji架构没有针对HBM研发的,HBM显存优势并没有得到体现,而且只有4GB的容量在当时高性能显卡中算是比较落后。但Vega核心经历大改,针对性优化HBM2之后,AMD称其为世界上最具并行性的GPU显存架构。
HBM首个完整规范就是AMD联手SK海力士研发的,因此初期只有AMD显卡专用,HBM说到底就是一种拥有超高位宽同时超功耗低内存芯片。与目前的闪存颗粒一样,也是由若干层高带宽内存Die垂直堆栈,每一层内存与底层的逻辑控制电路通过TSV硅穿孔、微凸点技术直接互连,再通过同样的技术,经中介层与GPU直接通信。
第一代HBM频率最高只有500MHz(等效频率1000MHz),每颗HBM显存总线位宽高达1024Bit,四颗总位宽就高达4096Bit,总带宽超过512GB/s,电压低至1.3V。
经过一年的发展,HBM 2显存相关技术规范已经准备差不多,同时成为JEDEC标准之一。HBM 2显存最大提升在于实现了8-hi堆栈,容量可以由每颗粒1GB提升至8GB,工作频率由1000MHz提升至1890MHz(比预期的稍有缩水),但是VEGA专业卡只用两颗就能达成16GB容量,游戏卡只要一颗就能拥有8GB显存。

距离AMD宣称2x带宽提升还差一点点

HBM 2显存占用的面积比GDDR5更低,单位面积容量提升8倍
AMD为了展示HBM 2显存性能,演示了一间起居室的照片级渲染画面。原本需要花费数小时去渲染的600GB场景,但在Vega架构配合HBM 2加持下,仅仅几分钟就渲染完成。最终效果还能实时移动镜头去查看房间的角落,细致的画面令人感到震惊。

之前AMD放出的Radeon Pro Vega核心渲染图,下面两颗就是HBM 2显存

我们拆解的AMD Radeon Vega Frontier Edition显卡核显,与渲染图一致

如果说HBM 2显存是Vega显卡一大特色,那么HBCC高带宽高缓存控制器可以说是其杀手锏。从之前显卡架构示意图来看,以往显卡内存控制器只能控制GDDR5显存,Vega大改以后HBCC就厉害了,它还可以连接显卡PCB接入的SSD(Radeon Pro SSG那种)、网络存储、系统DRAM等不同形式的片外存储器件。
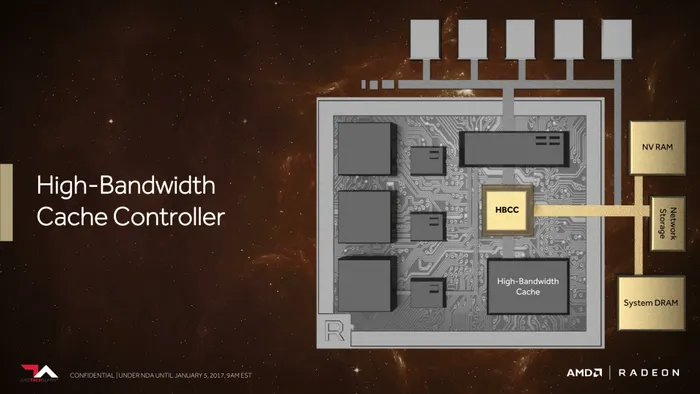
HBCC高带宽高缓存控制器
而且AMD表示HBCC的寻址能力高达512TB!也就说未来开发者可以把所有的存储器件都当做显存来用,只要速度够快!如此一来Vega显卡就可以成为一个名副其实的计算卡,看来AMD是为Vega在人工智能、深度计算上隐藏了一个大招。


自适应、细粒度数据迁移
在《杀出重围:人类分裂》中,启用了HBCC(高带宽缓存控制器)后,GPU的显存寻址效率提升明显,对应所需的显存大小需求更小,从而提升了游戏画面速度。在帧率优化演示中,启用了HBCC后,游戏平均帧数提升了50%,最小帧率提升一倍,游戏画面非常流畅。
演示过程中,AMD还将HBCC的显存寻址上限从4GB缩小到2GB,即便如此,在显卡只能使用一半的显存依旧能获得流畅而稳定的游戏画面,这个就要归功于超高带宽的HBM 2显存和高效率的HBCC。

新一代NCU单元:
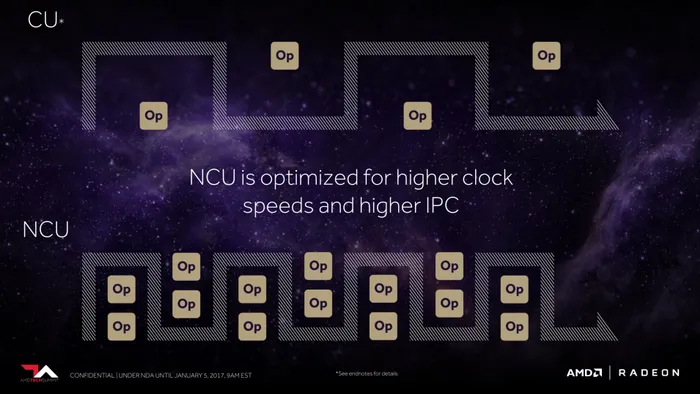
AMD GCN架构改了一代又一代,不过测试下来一看,每一代的性能提升并不大。今年在Vega上,AMD也是痛定思痛,设计了“全新”的NCU(Next-Generation Compute Engine)架构,不仅优化了IPC性能,还提高了运算单元的灵活性。
一般来说我们玩游戏、3D渲染对于单精度FP32、双精度FP64要求比较高,而在大规模深度计算中却对半精度FP16有非常高的需求,在深度计算领域先行一步的NVIDIA早就意识到这个问题,率先加入了对FP16半精度支持,半精度性能几乎是双精度的两倍,在深度计算上性能优势十分明显。而AMD在Fiji还是Polaris架构上都慢半拍,没有周全考虑到,导致其专业卡在市场是不受青睐。
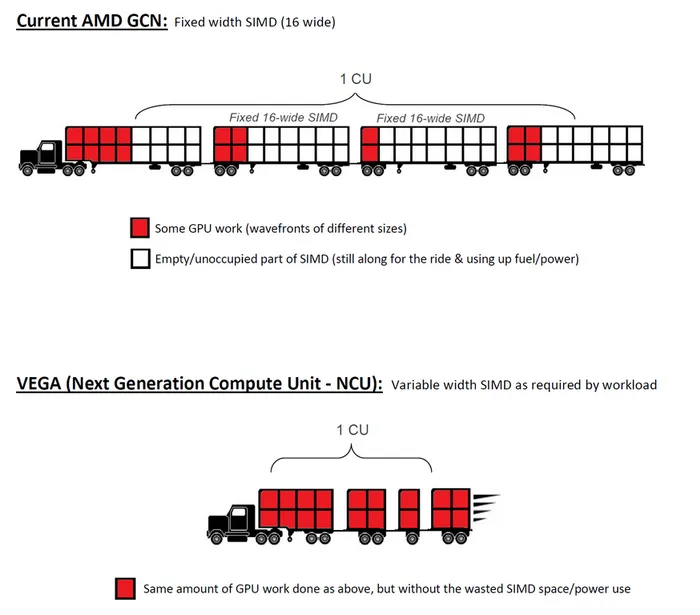
因此Vega GPU中首度引入了紧缩的半精度计算支持,Vega的微架构被称为“NCU(下一代计算单元)”,每个NCU中拥有64个ALU,它可以灵活地执行紧缩数学操作指令,如每个周期可以进行512个8位数学计算,或者256个16位计算,或者128个32位计算。这不仅充分利用了硬件资源,也大幅度提升Vega在深度学习计算的性能。效果也非常显著,在之前公布的Radeon Instinct MI25计算卡就是基于Vega架构的,其FP32单精度浮点性能12.5TFLOPS,而半精度FP16性能直接翻倍到25TFLOPS。

现有的GCN单元中每个CU计算单元是64个流处理器,实际上是由4组固定16-Wide的单元组成,而Vega显卡的NCU单元中流处理器数目更具灵活性,可以根据工作负载来动态调配。
AMD与NVIDIA在单精度与半精度单元使用上如出一辙,都是可以将两个16bit单元组装成一个完成的32bit单元使用。

现在AMD强调Vega显卡为更高的时钟频率及IPC性能优化,其实Polaris显卡的频率经历RX 400、RX 500两代,频率对比从前已经大有长进,能跑到1500MHz上,不过这也是AMD显卡的上限了。而老对手NVIDIA Pascal显卡起步就是1500MHz水平,Boost频率分分钟能上2000MHz。
既然AMD说明Vega的NCU已经对更高时钟频率作出优化,我们从已经发售的AMD Radeon Vega Frontier Edition专业显卡就知道,最高频率可以达到1600MHz,不过依然是不够出彩,据说RX Vega游戏卡频率将会设定在1630MHz。

下一代计算单元NCU中引入了RPM(Rapid Packed Math),专门用于加速FP16的运算速度,新的着色器可以利用RPM,在AMD一直引以为豪的TressFX毛发渲染中,Radeon RX Vega显卡每秒能渲染的头发数量增加了一倍,因此RPM能够辅助GPU核心进行更快更强的的物理计算。

新一代几何渲染可编程引擎:
几何渲染计算是所有图形渲染的基础,它的重要性不言而喻。不过在过往,AMD一直都是采用固定的流水线来处理几何计算,虽然这种固定的几何着色引擎具有像DSP那样的高效、速度快等优势,但是对于现在的游戏来说,渲染场景变化非常大,这种固定式流水线显得不够灵活。
AMD举出了一个例子,那就是Benchmark杀手的《杀出重围:人类分裂》,在这个Benchmark测试场景中,画面中的物体元素非常复杂,整个场景每个物体共包含2.2亿个多边形需要计算,但是很多物体都是被遮盖,实际上只要输出0.02亿个多边形就能完成画面渲染,其余的多边形根本不需要显示出来,换而言之,多达98%的性能被白白浪费了。

《杀出重围:人类分裂》Benchmark场景

《杀出重围:人类分裂》几何线框渲染图
因此新一代的几何渲染可编程引擎诞生了,灵活地运用几何着色器进行特定的算法优化,将大量不必要的渲染计算全部忽略掉,只保留我们可视部分,从而达到节省硬件资源和能耗、提高游戏性能目的,其实这个也是游戏优化思路之一。
图像除了经过顶点着色器和几何着色器常规处理,Vega架构中还引入了一个全新的Primitive Shader(原始着色器),AMD解释这种新型着色器可以大幅度减少不必要的几何计算,实现更加快速、精简的渲染过程。据说引入这个机制的灵感是因为主机开发者对于主机性能更为敏感,总是要各种花式优化游戏(讲到底就是在你看不到的地方砍渲染精细度,这也是没办法,主机性能就是这么多)。
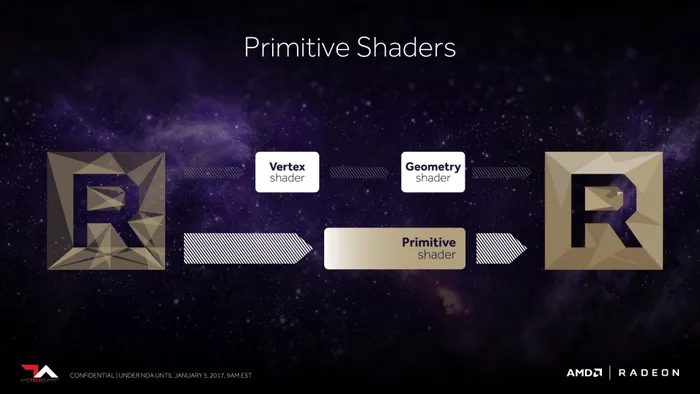
提升几何计算性能的另一个方法就是让GPU可以同时控制更多的着色器引起,因此加入了名位“Intelligent Workgroup Dostributor”(智能工作组分发器)的单元,该分发器可以实现对更多的着色器引擎的控制,并且可以根据负载情况智能地在各引擎之间均衡分配几何计算任务。
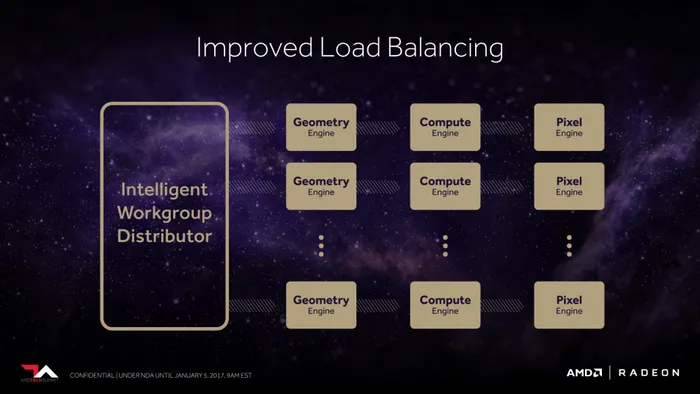

最终AMD在Vega架构显卡上实现了两倍的每时钟周期几何性能提升
新一代像素引擎:
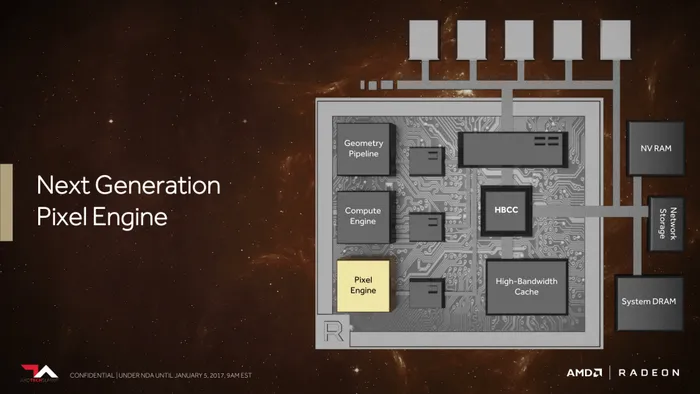
最后一部分的改进就是针对像素着色引擎进行优化,并且将其命名为Draw-streaming binning rasterizer(渲染流分档光栅器),其工作原理和之前的几何渲染引擎很相像,也是通过预先识别出无需出现、不必要的被遮掩像素,直接把这部分像素渲染计算剔除掉,以此达到更加高效的像素渲染性能。也能帮助显卡减少工作量、发热、耗电量,间接地提升了性能以及能耗比。
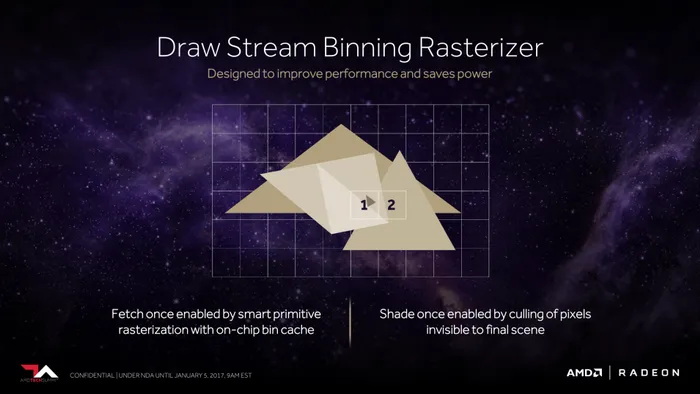
翻看前面的PPT,你会发现像素着色引擎通过L1缓存直接与L2缓存相连,后端渲染单元可以直接访问二级高速缓存,减少了清空缓存后在需要的时候重读显存数据,对于延后式渲染技术的性能有不少提升,特别适用于VR渲染应用。不过由于渲染流分档光栅器不是Vega架构中必须项,游戏开发者可以按照实际情况来觉得是否采用这个技术,换而言之就是,目前目前已有的游戏都适用渲染流分档光栅器,需要游戏开发者针对性优化,才能体现其威力。
目前AMD所透露的Vega信息全都在这里了,可以看得出AMD这次在Vega上并没有打算堆晶体管数目来提高性能,而是另辟蹊径去提高每一个单元的效率,不做无用功。
那么现在我们能看到那几款Vega架构的产品呢?AMD Vega架构显卡产品线:
Radeon Instinct MI25:
Radeon Instinct MI25属于高性能计算卡,拥有64组NCU单元,换算过来就是4096个SP流处理器,配合16GB的HBM2显存,显存带宽高达484GB/s,目前推测其基础频率约为1500MHz。半精度浮点性能有了很大进步,达到了24.6TFLOP,而单精度也有12.3TFLOPS,双精度性能为768GFLOPS,在半精度、单精度性能上都完美超越了Tesla P100-16,不过却比不上NVIDIA新发布的Tesla V100,后者的半精度性能已经飙升至30TFLOPS水平。
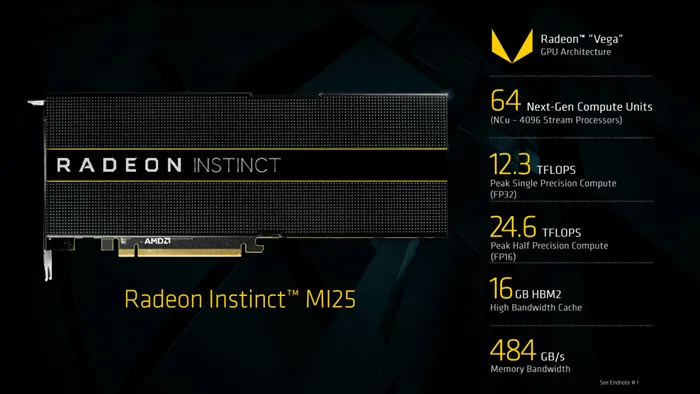
适合密集型计算、高性能深度计算上
AMD Radeon Vega Frontier:
Radeon Vega Frontier Edition属于专业绘图卡,通用有64组NCU单元,16GB HBM2显存,显存带宽480GB/s,单精度与双精度性能均好于Radeon Instinct MI25计算卡,FP32单精度浮点性能12.5TFLOPS,FP16半精度浮点性能25TFLOPS。


RX Vega:
RX Vega就是我们零售市场上的游戏卡,AMD对于Vega游戏卡信息守口如瓶,目前尚未知道有多少款Vega游戏卡产品。不过可以确定的是,最高阶RX Vega同样会有64组NCU单元,即4096个流处理器,HBM 2显存减配至8GB(应该是单颗粒8GB),因此显存位宽同样为2048Bit,至于显存带宽483GB/s。

距离RX Vega发布也只剩下三天时间了,这一次小超哥微信9501417也将会亲赴美国洛杉矶参加AMD Radeon Vega&Ryzen Threadripper Tech Day,第一时间为大家来详细消息。
总结:
Vega架构上的变革无疑是为使用多年的GCN架构注入了新的血液,AMD也因此有资本与NVIDIA在高端显卡上一较高下,就目前泄露出来的跑分成绩来看,RX Vega至少有GTX 1080的水平,如果价格合适,并且能大量投放到市场中,相信AMD也能重回荣光,努力向锐龙处理器学习吧,大家都等着Vega显卡呢。
此外,从Vega中的HBCC、加入FP16半精度单元,我们都看到AMD想在Vega上实现游戏与计算的大一统,技术既能用于游戏处理上,也能成为专业卡、计算卡,挖掘其深度计算能力。
其实我们很欣慰看到这种创新推进力,毕竟有创新才有进步,有进步竞争对手才有压力,市场才有有充分的竞争力,最终收益的还是我们这些玩家。