
编者按:本文来自微信公众号“极限元”,本文由极限元智能科技语音算法专家、中科院-极限元“智能交互联合实验室”核心技术人员、中科院自动化所博士刘斌整理分享
本期分享的主题为:智能语音前端处理中的关键问题
随着深度学习技术的快速发展,安静环境下的语音识别已基本达到实用的要求;但是面对真实环境下噪声、混响、回声的干扰,面对着更自然随意的口语表达,语音识别的性能明显下降;尤其是远讲环境下的语音识别,还难以达到实用的要求。
语音前端处理技术对于提高语音识别的鲁棒性起到了非常重要的作用;通过前端处理模块抑制各种干扰,使待识别的语音更干净;尤其是面向智能家居和智能车载中的语音识别系统,语音前端处理模块扮演着重要角色。除了语音识别,语音前端处理算法在语音通信和语音修复中也有着广泛的应用。
在面向语音识别的语音前端处理算法,通过回声消除、噪声抑制、去混响提高语音识别的鲁棒性;真实环境中包含着背景噪声、人声、混响、回声等多种干扰源,上述因素组合到一起,使得这一问题更具挑战性。
远场语音识别的几个典型的应用场景,包括:智能机器人、智能家居等,此外智能车载也有着非常广泛的应用。为了使得这几个典型应用场景的技术真正落地,需要解决一系列技术痛点,语音前端处理的一个最为重要的目标是实现释放双手的语音交互,使得人机之间更自然的交互。
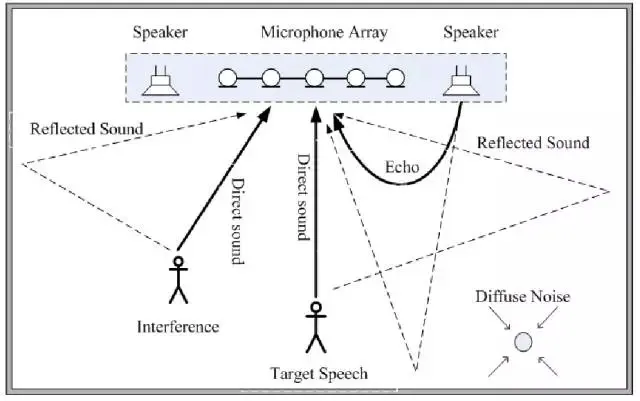
此图形象的描述的语音前端处理模块的几个关键问题:Echo:远端扬声器播放的声音回传给麦克;Diffuse Noise:无向噪声的干扰;Reflected Sound:声音通过墙壁反射,造成混响干扰;Interference:其他方向的干扰源; Target Speech:目标方向声音。Microphone Array:利用麦克风阵列拾音。
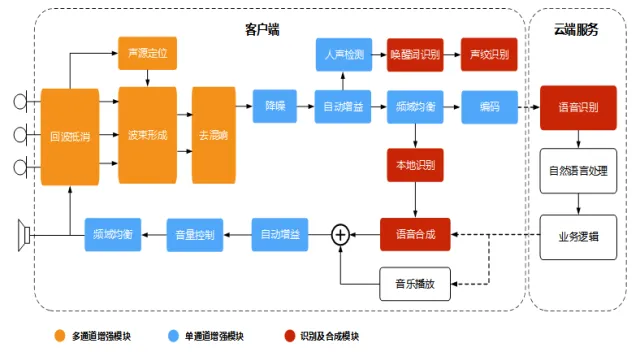
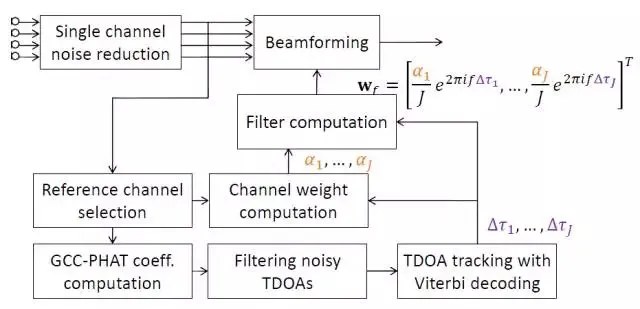
语音前端处理模块跟语音交互系统的关系:橙色部分表示多通道处理模块,蓝色部分表示单通道处理模块,红色部分表示后端识别合成等模块。麦克风阵列采集的语音首先利用参考源对各通道的信号进行回波消除,然后确定声源的方向信息,进而通过波束形成算法来增强目标方向的声音,再通过混响消除方法抑制混响;需要强调的是可以先进行多通道混响消除再进行波束形成,也可以先进行波束形成再进行单通道混响消除。经过上述处理后的单路语音进行后置滤波消除残留的音乐噪声,然后通过自动增益算法调节各个频带的能量后最为前端处理的输出,将输出的音频传递给后端进行识别和理解。
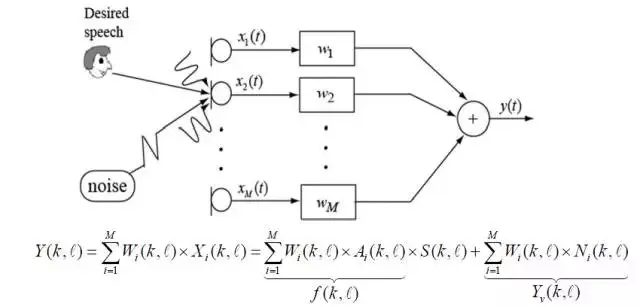
对于远场语音识别,更多的是采用双麦克,甚至是多麦克进行声音采集,这是由于单麦克远距离拾音能力有限,而麦克风阵列可以有效的增强目标方向声音。上图为麦克风阵列采集语音的示意图,各个通道的信号通过滤波器加权融合,Y为多通道融合增强后的语音,可以将其分解为两部分:目标语音成分和残留噪声成分;残留噪声成分可以通过后置滤波算法进一步处理,也可以通过改进麦克风阵列波束形成算法使这一成分得到有效抑制。
一、回声消除的方法:
在远场语音识别系统中,回声消除最典型的应用是智能终端播放音乐,远端扬声器播放的音乐会回传给近端麦克风,此时需要有效的回声消除算法来抑制远端信号的干扰。回声消除的两个难点是双讲检测和延时估计,对于智能终端的回声消除模块,解决双讲条件下对远端干扰源的抑制是最为关键的问题。
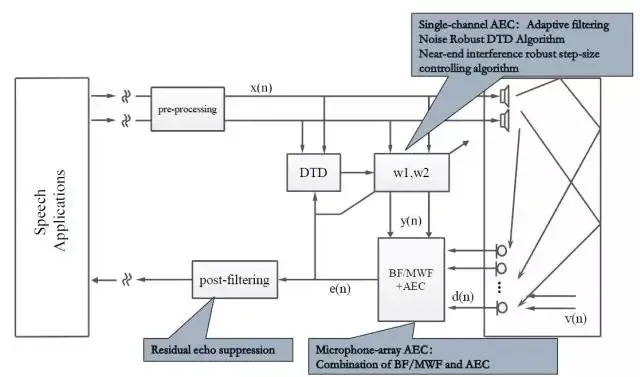
这是一个更为复杂的回声消除系统,近端通过麦克风阵列采集信号,远端是双声道扬声器输出;因此近端需要考虑如何将波束形成算法跟回声消除算法对接,远端需要考虑如何对立体声信号去相关。如图所示 DTD 部分结合远端信号和近端信号进行双讲检测,通过判断当前的模式(近讲模式、远讲模式、双讲模式)采用不同的策略对滤波器 w1 和 w2 进行更新,进而滤除远端干扰,在此基础上通过后置滤波算法消除残留噪声的干扰。
二、混响消除方法:
声音在房间传输过程中,会经过墙壁或其它障碍物的反射后到达麦克风,从而生成混响语音;房间大小、声源和麦克风的位置、室内障碍物、混响时间等因素均影响着混响语音的生成;可以通过 T60 描述混响时间,它的定义为声源停止发声后,声压级减少 60dB 所需要时间即为混响时间。混响时间过短,声音发干,枯燥无味不亲切自然,混响时间过长,会使声音含混不清:合适时声音圆润动听。大多数房间的混响时间在 200-1000ms 范围内。
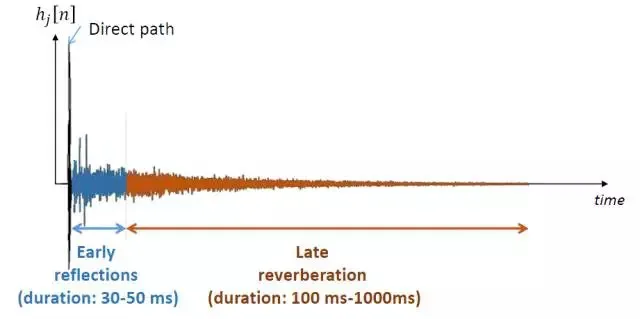
上图为一个典型的房间脉冲响应,蓝色部分为早期混响,橙色部分为晚期混响;在语音去混响任务中,更多的关注于对晚期混响的抑制。
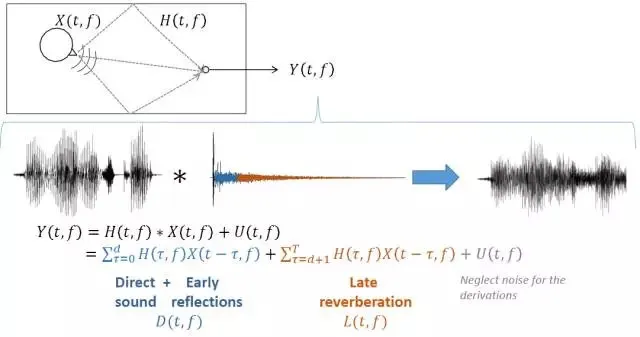
此图相对直观的描述了混响语音的生成过程,安静语音在时域上卷积房间脉冲响应滤波器后生成混响语音;通常语音在传输过程中会伴随噪声的干扰;因此麦克风接收到的语音Y包含三个部分:蓝色部分包括了从声源直接到达麦克风的语音以及早期混响成分、橙色部分是晚期混响成分、灰色部分是房间中各种噪声源的干扰。
当前主流的混响消除方法主要包括以下四类:基于波束形成方法、基于逆滤波方法、基于语音增强方法、基于深度学习方法。基于波束形成的混响消除方法假设干扰信号与直达信号之间是独立的,它对于抑制加性噪声非常有效,它并不适用于混响环境;理论上,逆滤波算法可以获得较好的混响消除性能,但是缺少能够在实际环境中对混响等效滤波器进行盲估计的有效算法,因此很难实际应用;谱增强算法根据预先定义好的语音信号的波形或频谱模型,对混响信号进行处理,但是该方法难以提取出纯净语音,从而难以有效实现混响消除。针对上述问题,一些学者开始尝试基于深度学习的语音混响消除方法,这种方法的劣势是当训练集和测试集不匹配时,算法性能会下降。这次报告重点介绍一种使用比较广的基于加权预测误差的混响消除方法。这种方法是由日本的 NTTData 公司提出并进一步改进的,能够适用于单通道和多通道的混响消除。
这种方法的思想和语音编码中的线性预测系数有些相似,如下图所示,混响语音信号Y可以分解为安静语音成分D混响成分L,L可以通过先前若干点的Y加权确定,G表示权重系数;WPE 算法的核心问题是确定G,然后估计出混响消除后的语音。
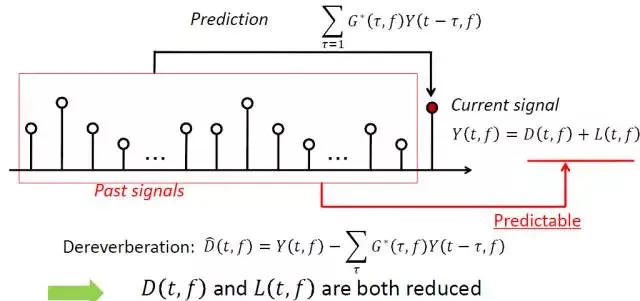
该算法通过如下目标函数估计滤波器系数,具体推倒过程如下所示,更为详细的算法流程可以参考一下网址推荐的论文。
http://www.kecl.ntt.co.jp/icl/signal/takuya/research/dereverberation.html
由于早期混响成分有助于提高语音的可懂度,因此可以对上述的方法进行改进,只抑制晚期混响成分。如下图所示D同时包括安静语音成分和早期混响成分,通过先前若干点的Y确定L时没有考虑早期混响成分。
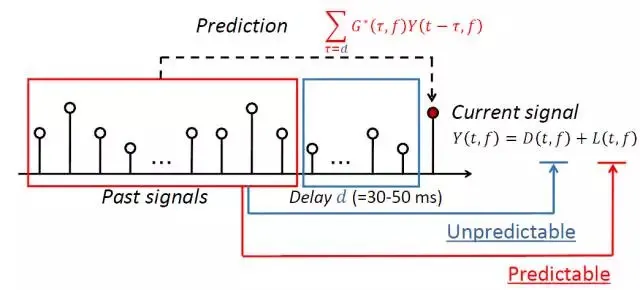
在此基础上将 WPE 方法扩展到多通道混响消除模式,此时某一通道的晚期混响成分L可以通过各个通道先前若干点的Y加权确定,通过估计最优的权重系数G,消除晚期混响成分的干扰。
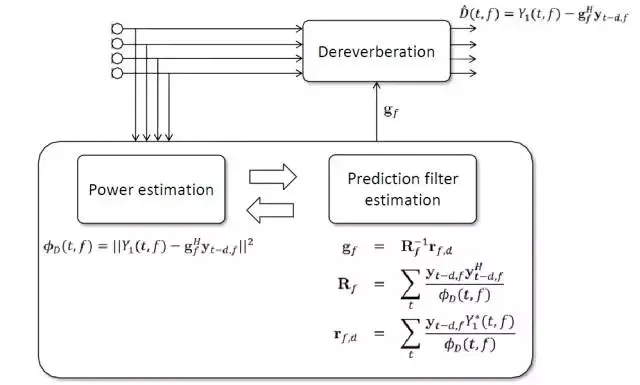
基于 WPE 的多通道混响消除的流程,如果所示需要经过多次迭代确定出滤波器系数g,生成出混响消除后的语音。输出的去混响后的各通道语音可以作为波束形成算法的输入。
三、语音降噪方法:
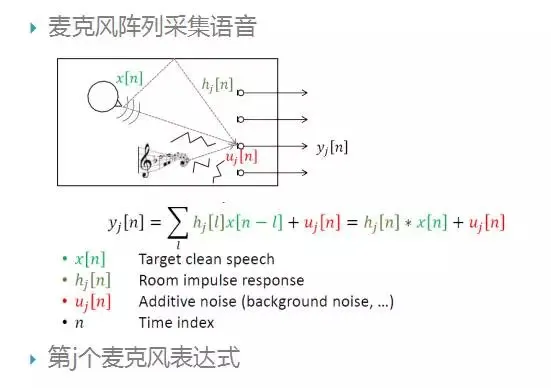
这个公式表示第j个麦克风接收到语音信号时域上的数学表达式,x表示安静语音,h表示房间响应函数,u表示其它噪声干扰。接下来介绍的算法将更多的侧重于对噪声源u的抑制。

此公式表示第j个麦克风接收到语音信号频域上的数学表达式,X表示安静语音,H表示房间响应函数,U表示其它噪声干扰。接下来介绍的算法将更多的侧重于对噪声源U的抑制。
波束形成算法的目的:融合多个通道的信息抑制非目标方向的干扰源,增强目标方向的声音。从图中我们可以看到,各个麦克风接收到的语音信号存在延时,这种时延信息能够反映出声源的方向;直觉上分析,通过对齐各个通道的信号,能够增强目标语音信号,同时由于相位差异可以抵消掉部分干扰成分。
波束形成算法需要解决的核心问题是估计空间滤波器W,它的输入是麦克风阵列采集的多通道语音信号,它的输出是增强后的单路语音信号。对空间滤波器进一步细分,可以分为时不变线性滤波、时变线性滤波以及非线性变换模型。最简单的延时求和法属于时不变线性滤波,广义旁瓣滤波法属于时变线性滤波,基于深层神经网络的波束形成属于非线性变换模型。
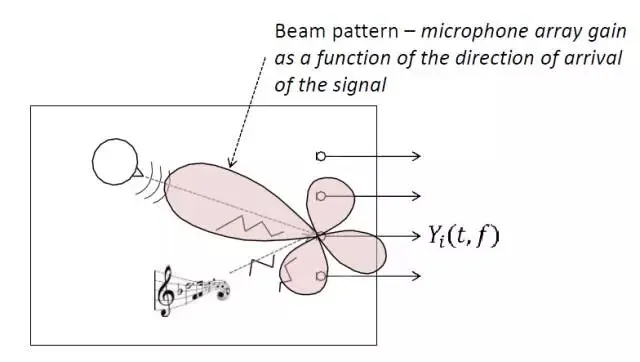
通过波束方向图可以更直观的理解波束形成的原理,上图是一个麦克风阵列算法在f频带上所对应的波束方向图,不同频带对应不同的波束方向图;波束方向图同时还依赖于麦克风阵列的硬件拓扑,例如线型阵只能实现 180 度定向,因此它的波束方向图是对称的。在设计波束形成算法时,需要尽可能使得主瓣带宽尽可能窄,同时能够有效的抑制旁瓣增益。在麦克风阵列选型上,麦克风之间的距离越大,则阵列的定向拾音能力越强,但是不能无限加大麦克风之间的距离,需要遵循空间采样定理。声学信号中的波束形成方法与雷达信号处理中的波束形成方法有很多相似之处,但两者处理的频带和带宽有差异。

麦克风阵列算法的数学表达式解析,式中Y表示各个麦克风接收到的信号,绿色部分表示声源信号,橙色部分表示声源信号传输到麦克风的变换,红色部分表示各种噪声源的干扰。因此波束形成算法需要在已知Y的条件下,尽可能准确的估计h和u;即估计导向矢量和噪声模型。
导向矢量是麦克风阵列算法中最为重要的参数,能够反映声源传输的方向性信息,用于描述从声源到麦克风传输过程中延时、衰减等特性;下图为自由场条件下的平面波模型,自由场假设忽略了混响干扰,远距离拾音可以近似为平面波模型;数学表达式中紫色部分表示声源到达各个麦克风的时间差,绿色部分表示声源向麦克风传输过程中的衰减,导向矢量主要跟这两个因素有关;在一些算法中会忽略能量衰减因素的影响。对导向矢量进一步处理也可以对声源方位信息进行估计。

通过广义互相关函数可以确定各个麦克风之间的相对延时,如下图所示,寻找广义互相关函数中的峰值点,通过峰值点的位置计算出相对延时。为了进一步提高 TDOA 估计的鲁棒性,可以采用 GCC-PHAT 方法,这种方法在已有方法基础上引入了能量归一化机制。
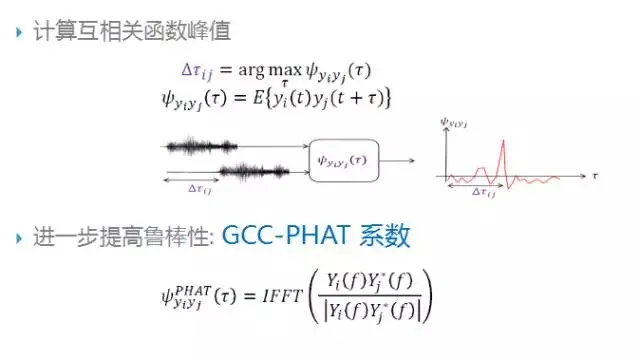
下图为一种改进的基于加权延时求和的波束形成方法,针对 TDOA 模块,利用维特比算法确定各个通道的最优相对延时,根据实际环境对各个通道的权重进行控制;算法细节可以参考 BeamformIt 工具包,这种算法作为 CHIME 评测比赛中的基线方法。
基于延时求和的方法计算复杂度低,但是它在真实环境下的鲁棒性差,接下来介绍一种应用更为广泛的方法:基于最小方差失真响应波束形成。如下图中的数学表达式所示,y表示多通道语音,w表示空间滤波器,x表示增强后的单通道语音,这种波束形成算法的假设是期望方向上的语音无失真,也就是w*h这项为1;同时保证对噪声的响应最小,也就是最小化w*u这项。在这两个约束条件下估计最优的空间滤波器w。

经过一系列的变换和推倒,我们能够确定空间滤波器w与噪声协方差矩阵和导向矢量的关系。为了计算噪声协方差矩阵,需要估计出各个通道中信号在各个频带上噪声成分的互相关系数,因此对噪声成分的有效估计将直接影响到波束形成算法的性能。对于导向矢量,可以通过估计声源到达各个麦克风的相对延时来确定。
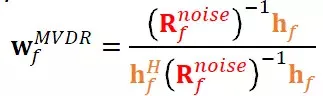
为了有效的估计噪声协方差矩阵,需要对各个通道信号的各帧的各个频带的屏蔽值进行估计,可以采用二值型屏蔽或浮点型屏蔽;通过这一屏蔽值可以判断各个频带是否是噪声主导以及噪声所占的比重;在确定了屏蔽值,可以进一步计算出噪声协方差矩阵和语音协方差矩阵;对于导向矢量,不仅可能通过到达各个麦克风的相对延时来确定,还可以通过语音协方差矩阵变换得到,导向矢量可以近似的表示为语音协方差矩阵最大特征值所对应的特征向量。
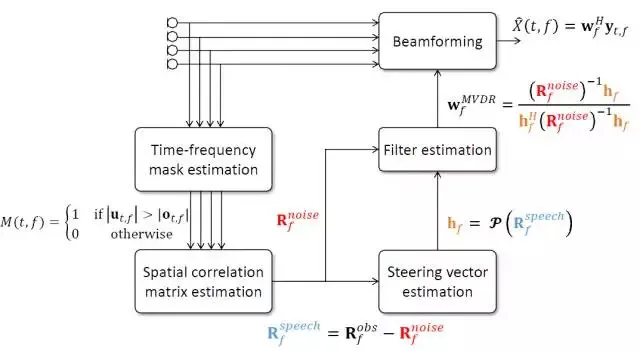
重点介绍基于最小方差失真响应波束形成的流程,对各个通道语音首先进行屏蔽值估计,然后计算噪声协方差矩阵和语音协方差矩阵,进一步确定导向矢量,通过导向矢量和噪声协方差矩阵估计空间滤波器,生成波束形成后的单通道语音。
除了基于延时求和的波束形成和基于最小方差失真响应的波束形成,以下几种波束形成方法应用也比较广泛,包括:基于最大信噪比的波束形成、基于多通道维纳滤波的波束形成以及基于广义旁瓣滤波的波束形成;通过数学表达式我们可以看出,噪声协方差矩阵的估计起到了非常关键的作用。
下面重点介绍一下基于深度学习的波束形成方法;深度学习方法在智能语音领域的应用非常的广泛,包括单通道的语音增强和语音去混响问题,深度学习方法已经成为了智能语音领域重要的主流方法之一;不同于单通道语音增强,多通道语音增强方法跟麦克风阵列的硬件结构高度相关,所以如果直接将各通道谱参数特征作为输入,将干净语音谱参数特征作为输出,所训练的模型将受限于硬件结构;因此,为了提高模型的泛化能力,更常用的方法是采用深层神经网络模型对各个通道各个频带的屏蔽值进行估计、融合,进而计算出噪声协方差矩阵,然后再跟传统的波束形成方法对接,如下图所示的方法是将深层神经网络方法跟最小方差失真响应波束形成方法对接。
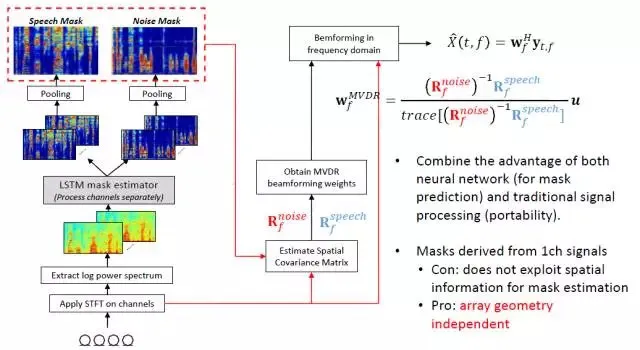
采用这种基于深度学习的方法,可以有效的抑制噪声的干扰,提高增强语音的质量。增强后的语音可以输入到语音识别系统,提高语音识别的鲁棒性。
四、语音前端处理方法在语音识别中的应用

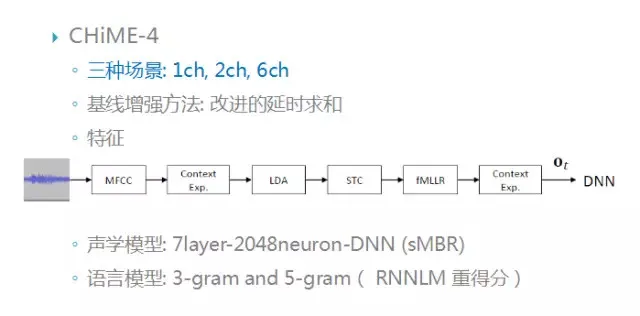
这是用于远场语音识别的公共数据库,不同于近场语音识别数据库,远场语音数据的采集不仅录音环境更为复杂,同时还跟采集语音的硬件相关。所以录制远场语音数据的成本相对较高。比较有名的远场语音数据库包括 AMI 数据,这个数据库是在会议室环境下录制的,混响时间较长;Chime 数据库,在噪声环境下录制的数据库,其中 Chime1 和 Chime2 是单通道采集的,Chime-3 和 Chime-4 是多通道采集的。
Chime-4 比赛中包括了三种场景:单通道、双通道和六通道。前端基线方法是改进的延时求和;后端声学模型是 7 层的 DNN,得到的声学模型需要再进行 sMBR 区分性训练;语言模型采用 3 元或 5 元的语言模型;语料内容来自 WSJ0 数据库。如果感兴趣可以关注 CHIME 的官网 http://spandh.dcs.shef.ac.uk/chime_challenge/index.html
以下是对 Chime-3 和 Chime-4 比赛中的有效方法进行的梳理。
首先看一下前端部分,有效的估计噪声协方差矩阵将有助于提高算法性能。为了有效的估计噪声协方差矩阵,需要对各个通道的各个时频单元进行屏蔽值估计,可以采用深度学习等方法进行估计,在此基础上计算噪声协方差矩阵;使用最多的波束形成方法包括:最小方差响应失真波束形成、最大信噪比波束形成、广义旁瓣滤波波束形成、多通道维纳滤波波束形成等。自适应波束形成方法要优于固定波束形成方法。
接下来介绍后端有效方法,在数据选择上充分利用各个通道数据;比如单通道语音增强任务,将六个通道采集的数据都作为训练数据;前端算法和后端算法的匹配非常重要,具体来说,训练声学模型时,如果是将前端算法处理后的数据作为后端声学模型的训练数据,则对于测试集,需要先通过前端算法进行增强处理,然后在此基础上通过后端模型识别;此外前端算法跟麦克风阵列的适配也是非常重要的。当前主流的声学模型包括了 BLSTM 和深层的 CNN;对不同的声学模型进行融合也有助于提高识别率,比如将 BLSTM 和深层 CNN 的输出层进行融合。对于语言模型 LSTM 优于 RNN,RNN 优于n-gram,对于工业领域的上线产品更多的是实用n-gram 模型。
当前这一领域仍然面临的挑战和需要解决的痛点包括:多说话人分离的鸡尾酒问题,如何改进盲分离算法突破鸡尾酒问题;说话人移动时,如何保证远场语音识别性能;面对不同的麦克风阵列结构,如何提高语音前端算法的泛化性能;面对更加复杂的非平稳噪声和强混响如何保证算法鲁棒性;针对更随意的口语,尤其是窄带语音,如何提高语音识别的性能;远场语音数据库不容易采集,如何通过声场环境模拟方法扩充数据库。上述问题的解决将有助于提高远场语音识别算法的性能。
极限元是国内少数可以提供人工智能全套技术解决方案,拥有自主产权的智能语音、机器视觉、大数据分析等人工智能技术的公司之一,极限元在北京、杭州设立公司, 与中国科学院自动化研究所共同成立“智能交互联合实验室”。
关于作者:
刘斌博士在国际顶级会议上发表多篇文章,获得多项关于语音及音频领域的专利,具有丰富的工程经验,擅长语音信号处理和深度学习,提供有效的技术解决方案。后续将会为大家分享更多智能语音技术的研究、应用等一系列的优质内容。