

去年,谷歌发布了 Google Neural Machine Translation (GNMT),即谷歌神经机器翻译,一个 sequence-to-sequence (“seq2seq”) 的模型。现在,它已经用于谷歌翻译的产品系统。
虽然消费者感受到的提升并不十分明显,谷歌宣称,GNMT 对翻译质量带来了巨大飞跃。
但谷歌想做的显然不止于此。其在官方博客表示:“由于外部研究人员无法获取训练这些模型的框架,GNMT 的影响力受到了束缚。”
如何把该技术的影响力最大化?答案只有一个——开源。
因而,谷歌于昨晚发布了 tf-seq2seq —— 基于 TensorFlow 的 seq2seq 框架。谷歌表示,它使开发者试验 seq2seq 模型变得更方便,更容易达到一流的效果。另外,tf-seq2seq 的代码库很干净并且模块化,保留了全部的测试覆盖,并把所有功能写入文件。
该框架支持标准 seq2seq 模型的多种配置,比如编码器/解码器的深度、注意力机制(attention mechanism)、RNN 单元类型以及 beam size。这样的多功能性,能帮助研究人员找到最优的超参数,也使它超过了其他框架。详情请参考谷歌论文《Massive Exploration of Neural Machine Translation Architectures》。
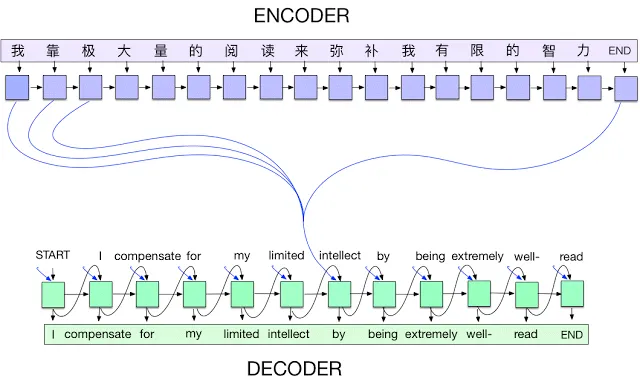
上图所示,是一个从中文到英文的 seq2seq 翻译模型。每一个时间步骤,编码器接收一个汉字以及它的上一个状态(黑色箭头),然后生成输出矢量(蓝色箭头)。下一步,解码器一个词一个词地生成英语翻译。在每一个时间步骤,解码器接收上一个字词、上一个状态、所有编码器的加权输出和,以生成下一个英语词汇。雷锋网(公众号:雷锋网)提醒,在谷歌的执行中,他们使用 wordpieces 来处理生僻字词。
据雷锋网了解,除了机器翻译,tf-seq2seq 还能被应用到其他 sequence-to-sequence 任务上;即任何给定输入顺序、需要学习输出顺序的任务。这包括 machine summarization、图像抓取、语音识别、对话建模。谷歌自承,在设计该框架时可以说是十分地仔细,才能维持这个层次的广适性,并提供人性化的教程、预处理数据以及其他的机器翻译功能。
谷歌在博客表示:
“我们希望,你会用 tf-seq2seq 来加速(或起步)你的深度学习研究。我们欢迎你对 GitHub 资源库的贡献。有一系列公开的问题需要你的帮助!”
GitHub 地址:https://github.com/google/seq2seq
GitHub 资源库:https://google.github.io/seq2seq/nmt/
via googleblog