
随着深度学习的发展,深度学习框架之间竞争也日益激烈,新老框架纷纷各显神通,想要在广大 DeepLearner 的服务器上占据一席之地。近日它们交锋的战场就是动态计算图,谁能在这场战争中取得优势,谁就把握住了未来用户的流向。作为一名 DeepLearner,如果能选中最适合的框架,就能在学习、研究和生产中提高自己的效率,步步领先。但要是上错了船,文档、性能、灵活性四处漏水,跳船之后还得游一段时间,这段时间可能都够别人开到新大陆了。所以说了解框架发展,掌握最新形式,可谓是每个不甘人后的 DeepLearner 的必修课。
近期各大框架发展的趋势主要有两个,一个是增加对动态图计算的支持,另一个是在主编程语言上适应广大用户的需求。最近比较火热的动态计算图相关的框架主要有 DyNet、PyTorch 和 TensorFlow Fold,就是围绕着这其中一个点或两个点进行的。
目前在这场竞争中,TensorFlow Fold 以其先进的 Dynamic Batching 算法走在了其他框架的前面。为了方便大家了解 TensorFlow Fold 的特性,本文将会为大家厘清有关动态图计算的一些概念,对比介绍 DyNet、PyTorch 和 TensorFlow 等框架的特性,重点讲解 TensorFlow Fold 的核心算法和接口。
本文分为五个部分:
一、当我们说动态计算图的时候,我们指的是什么?
二、框架竞争的焦点:编程语言与动态计算图
三、以静制动:巧妙的 Dynamic Batching 算法
四、TensorFlow Fold:封装在静态框架上的动态接口
五、总结
当我们说动态计算图的时候,我们指的是什么?
首先,我们要搞清楚深度学习框架所谓的“动态”和“静态”究竟是按照什么标准划分的。为了大家的直观理解,我这里要引入一个系列比喻,房地产商(框架使用者)通过电子邮件(编程语言代码)请建筑公司(深度学习框架)帮忙建造房子(计算图) 。
在静态框架使用的是静态声明(static declaration)策略,计算图的声明和执行是分开的,换成比喻的说法就是:建筑设计师画建筑设计图(声明)和施工队建造房子(执行)是分开进行的。画设计图的时候施工队的建筑工人、材料和机器都还没动,这也就是我们说的静态。这个整个声明和执行的过程中涉及到两个图,这里我们分别给它们一个名字,声明阶段构建的图叫虚拟计算图,在这个过程中框架需要将用户的代码转化为可以一份详细的计算图,这份计算图一般会包含计算执行顺序和内存空间分配的策略,这些策略的制定一般是这个过程最消耗时间的部分;执行阶段构建的图叫实体计算图,这个过程包括为参数和中间结果实际分配内存空间,并按照当前需求进行计算等,数据就在这张实体计算图中计算和传递。不过这里要注意一点的是,虚拟计算图中的部件并不需要在每一次执行中都转化为实体计算图。像建筑设计图上画了三层别墅的规划,但建筑队可以在按客户的要求只建下面的两层。另外一张设计图可以用多少次也没有规定死,所以说静态只是相对于下面的动态框架而言,并不是说静态框架就只能按部就班。常见的静态框架有 TensorFlow、MXNet、Theano 等。
而动态框架则不同,使用的是动态声明(dynamic declaration)策略,声明和执行一起进行的。比喻一下就是设计师和施工队是一起工作的,设计师看邮件的第一句如“要有一个二十平方米的卧室”,马上画出这个卧室的设计图交给施工队建造,然后再去看第二句。这样虚拟计算图和实体计算图的构建就是同步进行的了。因为可以实时的计划,动态框架可以根据实时需求构建对应的计算图,在灵活性上,动态框架会更胜一筹。Torch、DyNet、Chainer 等就是动态框架。
灵活很好,但也不是没有代价的。不然的话现在流行的框架中,就不会是静态框架占比更高了。静态框架将声明和执行分开有什么好处呢?最大的好处就是在执行前就知道了所有的需要进行操作,所以可以对图中各节点计算顺序和内存分配进行合理的规划,这样就可以就较快的执行所需的计算。就像房地产商邮件里说,“建一个栋大楼,楼顶建个花园,大楼旁边建一个游泳馆”,但这个顺序并不是最优的,设计师画完图之后,发现大楼的选址旁边要预留游泳馆的空间,游泳馆和大楼可以同时开工,并不用等到大楼的楼顶花园建完,就在图上把这些信息标注了出来,施工队就可以更高效地施工。这样一来,静态框架的执行效率相对来说就更高一些。这一点是动态框架的劣势,因为它每次规划、分配内存、执行的时候,都只能看到局部的需求,所以并不能做出全局最优的规划和内存分配。
另外的好处是对于建筑公司的管理层(框架开发者),因为一张设计图可以被反复施工,所以设计师画图的快慢影响就小地多了,对于一个要建几年的工程设计师画图的时间是三天还是五天影响不大,静态建筑公司不用花费太多资源去培训设计师的画图速度(缩短构建虚拟计算图的时间,主要是规划计算顺序和分配内存空间的时间)。而动态建筑公司就不同了,因为每建一套房子或一排房子就要重新画一遍设计图,对于一个几周的子项目来说,花三天画图还是五天就影响比较大了。所以动态框架对虚拟计算图的构建速度有较高的要求。当然因为动态框架每步构建和计算只是虚拟计算图的一个局部,需要策略不会太复杂,所以制定策略也快得多。
在过去的大部分的深度学习项目中,不管使用的是静态框架还是动态框架,我们实际上都只用到了构建静态实际计算图的能力。为什么这样说呢?因为在一般在将数据投入模型进行训练或预测之前,往往会有一个预处理的步奏。在预处理的时候,我们会将图片缩放裁剪,将句子拼接截断,使他们变为同样的形状大小,然后将集成一个个批次(min-batch),等待批次训练或预测。这些不同的输入到模型中其实运行的是同一个计算图。换成房地产的说法,就是说用户的需求虽然略有区别,但经过房地产商的努力,他们都同意要同一款房子。不管是房地产商选的是静态建筑公司还是动态建筑公司,建造的房子都是统一的小区样式。
这样作的好处是可以充分利用 GPU 和多核 CPU 的并行计算能力。这种能力可以怎么理解呢?建筑施工队里面有很多的砌墙工人,100 个人取砌一堵 1 米的墙并不会比 10 个人快上 10 倍(能实际工作的可能还是只有 10 个人),而让他们同时砌十堵 1 米的墙,可能所花的时间可能和砌一堵墙几乎一样快。如果有很多可以通过这样并行来加速的工作,那整个工程所需要的时间也就可以大大缩短。GPU 能够几十倍上百倍地提高计算速度是现代深度学习发展的一个关键,毕竟现在的深度模型很大程度上还是很依赖调参,需要快速地迭代。能否利用这种加速能力常常就是一次训练几个小时还是几周的区别,也是决定一个项目能不能做的关键。
然而,并不是所有项目的数据都可以预处理成相同的形状和尺寸。例如自然语言处理中的语法解析树,源代码中的抽象语法树,以及网页中的 DOM 树等,形状的不同本身就是非常重要的特征,不可剥离。这些数据就像充满个性的艺术家,每个人对房子该是什么样的都有自己的想法,买房的主要目的就是想彰显个性,你想让他们买一样的房子,对不起,做不到。
这样一来,对于每一个样例,我们都需要一个新的计算图,这种问题我们需要使用构建动态计算图的能力才能够解决。这种问题我们可以叫它多结构输入问题,因为这个问题中计算图的动态需求是输入带来的。不同框架这个问题的求解能力可以分为三个程度:第一层,无法计算,对于所有样本都要求同样的结构,在 TensorFlow Fold 出来之前所有正常使用的静态框架处于这个层次。第二层,能计算但不够高效,不同批次的样本之间可以有不同的结构,但同一个批次样本都是同一个结构,因为无法利用 GPU 和多核 CPU 的并行计算能力,不能高效计算,目前所有的动态框架属于这个层次。第三层,能高效计算,能够在同一个批次里包含不同结构的样本,这个层次的多结构输入问题有些论坛上也叫 Dynamic Batching 问题, TensorFlow Fold 的核心算法 Dynamic Batching 算法刚好同名,TensorFlow Fold 和以后实现 Dynamic Batching 算法的框架处于这个层次。
多结构输入问题早已存在,可用的模型诸如递归神经网络(Recursive Neural Networks)也提出许久,但因为没有办法高效实现,研究和使用者寥寥无几。因此,当我们说各大框架的动态计算图的时候,我们关心的不仅仅是他们谁更容易做到,更重要的是能不能高效地做到。动态计算图问题之一的多结构输入问题的高效计算问题一旦解决,就会大大促进树状网络甚至更复杂模型和数据集的发展。
但多结构输入问题并不是唯一的动态图计算问题,这里给大家举另外一个例子,即计算图的结构要依赖于自身的计算结果的情况,类比就是后面房子怎么建要看前面建得怎么样,这种问题更加复杂,所有的动态框架都可以轻松解决,而静态框架目前是做不到,不过目前还没发现有具体问题需要这样操作,我们这里不作仔细讨论。
框架竞争的焦点:编程语言与动态计算图
在动态计算图争锋下面,还隐含着另外一重较量,编程语言的支持。上文我们将代码比作电子邮件,那编程语言就是像英语、中文这样的语言。当前深度学习界最受欢迎的语言莫过于 Python 了,此外 C 也因为其本身的高效在工业界颇得青睐。现在大多主流框架都支持这两种语言,他们是就像机器学习界的中英文。不过 Torch 是一个例外,它使用的是比较小众的 Lua,这实际上是它最大一块短板,因为使用 Lua 做一些数据处理并不方便,使用者经常要使用 Python 之类的语言进行数据清洗等操作,然后在转化为 Lua 可以读取的形式。这一点使得无数使用者在不同语言的切换中纷纷投向 TensorFlow、MXNet 的怀抱。即使去年年中 Facebook 推出 TorchNet 这个 Torch 升级版也没有挽回太多的人气,因为 TorchNet 用的也是 Lua。
在 DyNet 出现前,Python 和 C 上还没有一个比较高效的动态计算框架(如 Chainer 效率并不高)。这个由多所大学和公司的二十多位研究者共同发布新框架,一下子就找准了自己的定位,即在深度学习框架中语言最好(Python/C )且动态计算最强。他们通过对动态声明的图构建流程的优化,大大提高了构建虚拟计算图的速度,也就是说他们的建筑设计师画图和规划做得飞起。该框架在 LSTM 和 BiLSTM 等部分测试中超过了 Chainer、Theano 和 TensorFlow,并且在当时 Theano 和 TensorFlow 难以实现的树状模型 TreeLSTM 的测试中也远远打败了 Chainer,所以 DyNet 一出来吸引住了不少使用者。
然而好景不长,Torch 不愧是有 Facebook 支持的公司,很快就推出了据说内部使用已久的 PyTorch,将 Torch 移植到了 Python,补足了自己最后一块短板。这下子就厉害了,不仅挽留住了人气,借助 Python 的力量甚至有机会从 TensorFlow 这位老大手里夺下一块蛋糕。
但是不管是 DyNet 还是 PyTorch,没有解决多结构输入问题的高效计算。它们虽然对不同的批次(mini-batch)可以给出不同的计算图。但同一个批次内部的样本的形状还是要求一致,并没有一个成熟的解决方案来应对这种情况。就是说他们每建一栋楼或一批楼的可以重新设计,但同时开工的同一批楼的样式一定是一样的。
面对新老对手的挑战,TensorFlow 作为深度学习框架界的霸主也不能无动于衷,终于给出了自己关于动态计算图高效计算的答案——TensorFlow Fold,也就是我们今天要讲的主角。这主角出场瞬时就 hold 住了场面,在 Reddit 上就有人立马评论“... pip uninstall pytorch!”。从上一部分我们知道,TensorFlow 其实是一个静态框架,天生在解决动态计算图问题上处于劣势。你说它一个静态的框架,怎么就解决了动态计算图的问题呢?(其实只是解决了多结构输入的问题)这中间究竟有什么奥秘,让笔者为大家娓娓道来。
以静制动:巧妙的 Dynamic Batching 算法
TensorFlow Fold 解决问题的核心技术叫 Dynamic Batching,这个技术能够构建一个能够模拟任意形状和大小的动态计算图的静态图,原本不同样本的动态计算图都会被重写成能够被这个计算图高效计算的形式。这样就巧妙地解决了动态计算图的高效计算问题。打比喻就是,建筑公司请了一位计算机科学家写了一个自动化办公软件,每当房地产商提出一个个性社区问题的时候,这个软件就会把一张通用的设计图告诉设计师去设计;然后对于每一批楼的需求这个软件都会生成对应的施工指南,只要按照这个指南的指示,施工就可以通过多次建造通用设计图中的一部分来完成这批楼的建造;在施工指南中软件已经合并每次建造时重复的工作,这样施工队可以并行施工,高效地完成工程。
更妙的是,这个技术并不仅在 TensorFlow 上能够使用,对于其他深度学习框架完全能够适用。可以预见的是,如果短期内没有更好的解决方案,这个技术很可能会被其他框架的开发者移植到他们自己的框架上,变成 MXNet Fold,PyTorch Fold 等。
那为什么用静态计算图模拟动态计算图是可能的?因为虽然动态计算图的形状和大小千变万化,但对于一个模型来说它们的基本组件却可以简单划分为两种:Tensor(张量)和 Operation(操作)。
Tensor,可以看做各种各样的数据块,主要包括输入的样本和计算结果,Tensor 的类型可以按照 shape(形状)和 data type(数据类型)划分,具有相同 shape 和 data type 的 Tensor 可以被划分为一类,就像相同大小和材质的砖头;这里的 shape 并不包括 batch size,它就像砖头的个数,一叠不管是十块还是五块,只要砖头的大小材质一样,我们认为是同一个类。
Operation,并不是是指加减乘除这样最底层的操作,而是指一块小的计算子图,一块计算子图接受某种确定类型的 Tensor 作为输入,并输出某种确定类型的 Tensor。这块计算子图在动态构建图的过程中并不会被拆开,而是作为一个整体被适用,比如 RNN 的 Cell 或其他用户自己定义的一些固定的操作组合。
对于某一个模型如树状 RNN 来说,但它只会有限种 Operation 和 Tensor 类型,当我们将这些 Operation 和 Tensor 类型放到一起,我们就有了一个通用子图,这时候只需要一些控制部件控制这个每次子图执行的部分(上文有提到每次执行的实体计算图可以只是虚拟计算图的一部分)以及组合方式,我们就可以模拟对应模型所有可能的计算图。达成这种控制只需 TensorFlow 的三个部件:tf.gather、tf.concat 和 tf.while_loop。
说完通用子图的组成,我们再说说 Dynamic Batching 怎么将不同结构的计算图重写成可以用通用子图计算的形式。Dynamic Batching 是一个贪婪(greedy)的算法,它接受一个有向无环计算图作为输入:
给图中的每一个节点(操作)标注一个深度,所有没有任何依赖的节点标注为深度0,依赖的节点深度最大为d的节点的深度标注为d 1;
在图中插入 pass-through(直通)的操作,使得第d 1 层只依赖于第d层;
将同一深度涉及相同操作的节点合并到一起,方便并行计算;
将同一深度的计算结果按 Tensor 类型(包括 Tensor 的形状和数值类型)有序拼接在一起;
将输入原始计算图中的每条边标记上(深度,数据类型,序号),对应它们可以获取上一层计算结果的位置。
对于一批不同结构的计算图,我们可以把它们看做不连通的大图同样处理。上面算法的第三步会将这批图中同一深度的相同操作进行合并,方便并行计算。说完图的构建,我们再说说怎么执行:算法在每次迭代中执行一个深度的计算,使用 tf.while_loop 从深度 0 一直执行到最大深度。在每一个深度中,tf.gather 根据上面第五步的标记为各个 Operation 获取当前深度各条输入边的 Tensor,如果某个 Operation 没有获取到任何 Tensor,说明当前深度这个 Operation 不需要执行计算。Operation 执行完后 tf.concat 将相同 Tensor 类型的计算结果拼接在一起,提供给下一个深度的计算。
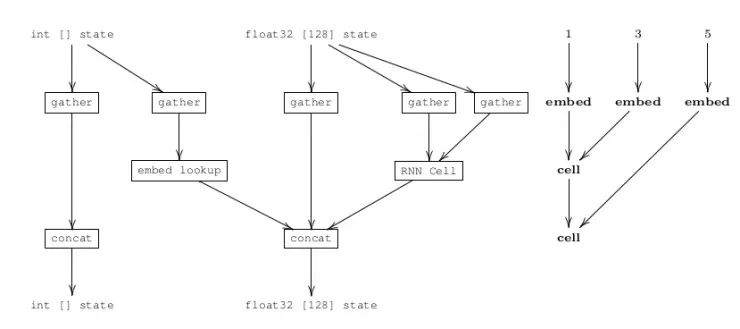
上面这一幅图来着官方论文,左边是 Dynamic Batching 为二叉 TreeRNN 构建的通用计算图。右边是一颗简单的语法解析树。通用计算图中有两种 Tensor,代表单词的编码整数、词向量/hidden 向量的 128 维向量。Operation 也只有两个一个词向量查表操作(embed lookup)和一个 RNN 的 Cell。图中 gather 和 concat 之间的直连表示直通(pass-through)操作。右边的语法解析树可以分为三层计算被执行:第一层,将1、3、5 通过词向量查表操作,输出 3 个 128 维的词向量;第二层,1 和 3 对应的词向量通过 RNN Cell 输出一个 128 维的隐含层向量,5 对应的词向量直通输出;第三层,上一层计算的隐含层向量和 5 对应的词向量通过 RNN Cell,输出一个 128 维的隐含层向量。计算完毕。
那这个算法的效果怎么样呢?它在 TreeLSTM 的实验中,8 核英特尔 CPU 的可以加速 20 多倍,而英伟达 GTX-1080 上可以加速 100 倍左右。这个加速比是采用 Dynamic Batching 算法批处理中平均每个样本执行的平均时间和单个样本不作批处理的执行时间之比。这里不包含构建虚拟图所需要的时间。
TensorFlow Fold:封装在静态框架上的动态接口
上面的 Dynamic Batching 的算法很繁琐,但不用当心,这个过程是由框架自动完成的,作为框架的使用者,我们只要知道怎么调用官方给出来的接口就可以了。新推出的 TensorFlow Fold 就是一个 TensorFlow 的封装,设计参考了函数式编程的一些思想,目的就是方便用户快速地构建动态计算图。下面我们来简单地浏览一下,要进一步了解可以去看官方的教学文档。
TensorFlow Fold 提供了一些函数专门用来处理序列(x1,...,xn):
Map (f):计算[f(x1) ,...,f(xn)]将函数f应用到每一个序列的元素,比如将句子中的每一个词转化为词向量;
Fold (g, z):计算g(...,g(z, x1), x2), ...,xn ),比如说展开一个 RNN(循环神经网络);
Reduce (g ):计算g(Reduce (g)[x1 ,...,xn/2],Reduce (g)[xn/2 ,...,xn],将函数g应用到一颗平衡二叉树上,比如对序列中的元素作 max 或 sum-pooling。
由于 TensorFlow 原本的基本单元 Tensor 不适合用于构建动态图,所以 Fold 引入新的基本组件 Block。Block 有明确的一个输入类型和一个输出类型,包括:
- Input:来着编程语言如 Python 中元素,比如字典等;
- Tensor:拥有数据类型和形状的 TensorFlow 基本模块;
- Tuple (t1 ,...,tn ):括号中的每一个t表示对应位置的类型;
- Sequence (t ):一个不定长的拥有类型为t的元素的序列;
- Void:单元类型。这些基本类型可以相互嵌套,比如一个 Block 的输入类型可以是 Input 类型的 Tuple。
用来创建 Block 的基本函数有:
- Scalar:将 Python 标量转化为 Tensor;
- Tensor:将 Numpy 数组转化为 Tensor;
- Function (h ):创建一个 Operation;
- InputTransform (h ):用于预处理 Python 类型。
用来组合 Block 的基本函数有:
- b1>>b2,流水线(pipeline):将b1 的输出作为b2 的输入;
- Record ({l1:b1,..., ln:bn}): 接受一个 Python 字典为输入,对字典中 key 值为li 的 value 应用;
- OneOf (b1,...,bn):根据输入条件应用b1,...bn中的一个;
- Optional (b):OneOf 的特例,如果输入不为 None,应用b;
- AllOf (b1,...,bn):输入应用中的每一个。
用来组合 Block 的高级函数有:
Composition ():流水线的升级版,流水线只能处理串行的流程,Composition ()创建一个 Scope 对象,在这个 Scope 的缩进范围内,采用b.reads (b1,...,bn )来读取多个数据流,可以用于构建多分支结构;
- ForwardDeclaration ():用来创建递归结构,这个函数可以先定义一个预先占位的表达式 expr,等这个表达式定义完再用 expr.resolve_to (expr_def),将表达式递归地代入,这是用来创建树结构计算图必不可少的工具。
总结
在动态图计算领域 TensorFlow Fold 目前领先一步,却也不是高枕无忧,只要 MXNet, PyTorch 等竞争对手抓紧把 Dynamic Batching 算法实现出来,或进一步想出更好的解决方案,就能很快赶上。而且 TensorFlow Fold 目前只支持 TensorFlow 1.0 版本,但只有尽快支持所有版本,才能让更多的用户使用上。另外工具的发展也会带动学科的进步,随着动态计算图的实现难度的下降和计算效率的提高,研究者们会越来越多地进入这个领域,可以预期的是接下来一段时间肯定会有更多复杂结构的模型和数据集涌现出来。未来将会如何,诸君尽请期待。