

有人最近在社交问答网站 Quora 上提出了这样一个问题:深度学习可以促成哪些产品突破?谷歌大脑团队工程师埃里克·蒋(Eric Jang)专门撰文给出了详细的回答。
以下为原文内容:
深度学习指的组成下列内容的一类机器学习技术:
——大神经网络(拥有数百万个自由参数)
——高性能计算(采用成千上万个处理器并行计算)
——大数据(例如,数百万的彩色图片或象棋档案)
深度学习技术目前已经在很多领域实现了最尖端的水平(视觉、音频、机器人、自然语言处理……暂举几例)。深度学习最近的进步还融合了来自统计学习、强化学习和数值优化等领域的内容。
以下是当今的深度学习技术有可能促成的一些产品(顺序不分先后):定制数据压缩、压缩传感、数据驱动型传感器校准、离线人工智能、人机互动、游戏、艺术助理、非结构化数据挖掘、语音合成。
定制数据压缩
假设你在设计一款视频会议应用,希望增加一套有损编码方案,以便减少通过互联网发送的数据包。你可以使用H.264 等现成的编解码器,但H.264 并非最优方案,因为它是针对普通视频设计的——从猫咪视频到故事片,再到风光片。
如果能有一套针对 FaceTime 视频设计的编解码器就好了,这样就能比一般算法节约更多数据,原因在于:多数时候,屏幕中央都有一张人脸。然而,设计这样的编码方案并非易事。如何确定人脸的位置?人脸上的眉毛有多宽?眼睛是什么颜色?下巴是什么形状?如果头发盖住了一只眼睛怎么办?如果图像上没有人脸或者有多个人脸怎么办?
这个时候,深度学习便可发挥作用。自动编码器是一种神经网络,它输出的数据只是输入数据的副本。如果不是自动编码器的隐藏层小于输入层,学习这种“恒等映射”(identity mapping)并没有太大意义。这种“信息瓶颈”会迫使自动编码器学习隐藏层里的数据的压缩表现,然后再借助网络中的剩余层解码原始形态。
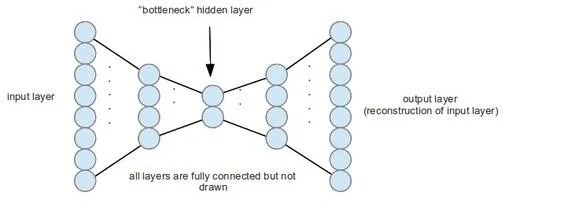
通过端对端训练,自动编码器和其他深度学习技术可以适应你的数据特性。与主成分分析不同,这些编码和解码步骤并不限于仿射(线性)变换。主成分分析学习的是 “编码线性变换”,而自动编码器学习的则是“编码程序”。
这便大大加强了神经网络的力量,甚至可以实现复杂且有针对性的压缩:无论是在 Facebook 上存储海量自拍,还是加快 YouTube 视频流,抑或压缩科学数据和降低个人 iTunes 曲库占用的空间,都可以通过这种技术来实现。试想,你的 iTunes 曲库可能会学习一个“乡村音乐”自动编码器,为的就是压缩你的个人曲库。
压缩传感
压缩传感与有损压缩的解码部分密切相关。很多有趣的信号都有自己独特的结构——也就是说,信号的分布并非完全随意的。这意味着我们不必为了获得完美的信号重建而按照奈奎斯特极限进行取样,只要我们的解码算法能够正确地利用底层结构即可。
深度学习可以适用于这种情况,因为我们可以利用神经网络学习松散的结构,而不必借助手工特征工程的帮助。以下是一些产品应用方式:
——超分辨率算法(waifu2X),相当于《犯罪现场调查:迈阿密》里面的“加强”按钮。
——使用 Wi-Fi 无线电波干涉实现穿墙透视(麻省理工学院的 Wi-Vi)。
——借助不完整的图像(例如 2D 图像或局部闭塞)来解析一个物体的 3D 结构。
——更加精确地重建来自声呐/激光雷达的数据。
数据驱动型传感器校准
优秀的传感器和测量装置往往要依靠价格昂贵的高精度元件。
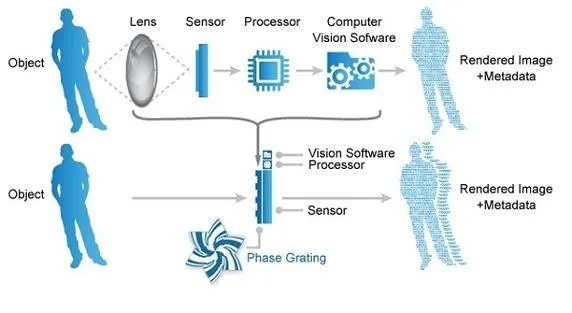
以数码相机为例。数码相机会假设玻璃镜头是某种“精密的”几何图形。拍摄照片时,机载处理器会解开穿过镜头的光迁移方程,然后计算出最终的图像。

如果镜头被刮花,或者发生弯曲,甚至造型像兔子(而非圆盘),这些假设就会被打破,无法顺利成像。
还有一个例子:磁共振和脑电图目前的解码模型假设颅骨是完美的球形,以此来控制数学运算。但借助这种方式计算肿瘤位置时,有的时候会出现几毫米的偏差。更加精确的摄影和磁共振成像应该可以弥补几何形状上的偏差,无论这些偏差来自底层资源还是制造缺陷。
幸运的是,深度学习可以借助数据校准解码算法。
不必借助一刀切的解码模式(例如卡尔曼滤波器),而是可以针对每个病人或每台测量装置表达更加复杂的偏差。如果我们的相机镜头刮花了,便可训练解码软件对变化后的几何图形进行补偿。这意味着我们不必再生产和匹配超精准的传感器,从而节省大量资金。
在某些情况下,甚至可以彻底抛弃硬件,让解码算法进行补偿。哥伦比亚计算摄影实验室就开发了一种没有镜头的相机。这是一种由软件定义的成像方式。
离线人工智能
能够摆脱互联网来运行人工智能算法对需要降低延迟的应用(例如自动驾驶汽车和机器人),以及没有可靠上网连接的应用(智能手机上的旅行应用)都至关重要。
深度学习就很适合这种情况。训练阶段结束后,神经网络可以迅速进步。另外,还可以直接将大型神经网络分割成一个个小型神经网络,直到足以在智能手机上运行为止(但要牺牲一定的精确度)。
谷歌翻译的离线相机翻译功能已经应用了这种技术。

此外还有其他一些可能的模式:
——智能助理(例如 Siri)可以在离线时保留一些功能。
——野外生存应用可以告诉你某种植物是否有毒,或者某种蘑菇是否可以安全食用。
——配备 TPU 芯片的小型无人机可以避开简单的障碍物。
人机互动
深度神经网络是第一种能够在可以接受的程度内看见和听见人类世界的计算机算法。这便为人机互动开辟了很多可能。
摄像头现在可以用来读取标志牌上的内容,甚至可以为人们大声读书。事实上,深度神经网络现在还可以用完整的句子向我们描述它所看到的内容。百度小明项目便可通过耳机里传出的语音帮助视力损伤的人“看到”周围的世界。
人机互动不仅限于视觉范畴。深度学习还可以帮助下身瘫痪的人校准脑电图接口,从而加快与电脑的互动速度,或者为 Soli 等项目提供精确的解码技术。
游戏
游戏之所以在计算性能上面临挑战,是因为需要同时运行物理模拟程序、人工智能逻辑、渲染和多人互动。很多组件的复杂度都极高,所以目前的算法已经达到摩尔定律的天花板。
深度学习可以通过几种方式扩大游戏的极限。
显然存在“游戏人工智能”这样一个领域。在目前的视频游戏中,非玩家角色(NPC)的人工智能逻辑只是一组 if-then-else 语句的堆砌,通过简单的调整来模拟智能行为。这对于高级玩家而言显然不够,因此他们可以在单人模式中轻松通关。即便是在多人模式中,人类玩家往往也是整个游戏中最聪明的一员。
深度学习就可以改变这种现状。谷歌 DeepMind 的 AlphaGo 已经向我们证明,深度神经网络与政策梯度学习整合到一起,便足以在复杂的围棋游戏中击败最强大的人类选手。AlphaGo 使用的深度学习技术或许很快就能应用到 NPC 中,使之可以找到玩家的弱点,并提供更具互动性的游戏体验。其他玩家的游戏数据也可以发送到云端,用于训练人工智能,使之可以了解自己的错误。
深度学习在游戏中的另外一项应用是物理模拟。不必模拟流体或颗粒在牛顿第一定律下的状态,而是可以将非线性动力学问题变成一个回归问题。例如,如果我们训练一个神经网络学习流体力学的物理学原理,那就不必实时求解大规模的纳维叶-斯托克斯方程,也可以在游戏过程中快速进行评估。
事实上,Ladicky 和 Jeong 已经在 2015 年做过这种尝试。

对于最小播放速率必须达到 90 帧/秒的虚拟现实应用来说,这是在目前的硬件局限下唯一可行的方法。
第三,深度产生式建模技术还可以用于创建无限而丰富的程序性内容——动物群、角色对话、动画、音乐甚至游戏本身的描述。这一领域刚刚开始爆发,代表游戏是《无人深空》(No Man’s Sky),这款游戏可以无止境地为玩家提供新颖内容。

深度神经网络很适合同步进行小批量的评估,例如,可以在一张图形卡上同时评估 128 个 NPC 人工智能逻辑和 32 个水流模拟。
艺术助理
考虑到神经网络在感知图片、音频和文本方面的强大能力,使用这种技术来绘图、作曲和写小说也就不会令人感到意外了。

从多年前开始,人们就已经尝试用电脑来作曲和绘画,但深度学习却是第一个能够真正创作出“好作品”的电脑程序。App Store 里已经有几款应用借助这种算法制作笑声,但我们很快或许就会在专业内容制作软件中看到类似的内容。
非结构化数据挖掘
深度学习从网页中提取的信息量仍然无法与人类媲美,但深度神经网络的视觉能力却足以让机器理解超文本之外的内容。
例如:
——通过扫描海报来解析事件。
——判断 eBay 上的哪些产品是相同的。
——通过网络摄像头判断消费者的情绪。
——不使用 RSS,也可以直接从页面上提取博客内容。
——整合照片信息,用于评估金融工具、保险政策和信用评分。
语音合成
产生式建模技术已经实现了充分的发展,目前的数据也已经非常充足,所以要不了多久应该就会有一款应用能够用摩根·弗里曼(Morgan Freeman)或斯嘉丽·约翰逊(Scarlet Johansen)的声音为你大声朗读。我们甚至可以直接用声音当密码。
更多产品
——适应性操作系统/网络堆栈排列——在操作系统中排列线程和进程是一个非常复杂的问题。我们目前没有针对这一问题开发出令人满意的解决方案。而现代化的操作系统、文件系统和 TCP/IP 的排列算法却都非常简单。如果能够使用小型神经网络来适应一个用户的独特排序状态,或许就能降低操作系统产生的排列费用。这对数据中心或许有着重大意义,因为在那里,任何一点改进都可以节约巨额费用。
——显微镜检查软件的菌落计数和细胞追踪功能。
——“用机器学习取代模拟”的战略在药物设计领域也很有用,可以在寻找有用或有毒化合物的过程大幅加快速度。