

《自然》杂志日前撰文称,由于人工智能技术模拟了人脑的工作模式,而没有采用明确的数据存储和分析方式,因此存在一些难以捉摸的黑盒子。如何解决这些“黑盒子”问题,从而真正了解机器的学习方式便成为摆在科学家面前的严峻挑战。以下为原文内容。
所谓“黑盒子”,是指从用户的观点来看一个器件或产品时,并不关心其内部构造和原理,而只关心它的功能及如何使用这些功能。但从研究者的角度讲,搞清楚内部构造和原理是必须的。
迪恩·鲍莫里奥(Dean Pomerleau)至今还记得他第一次碰到黑盒子问题时的情形。那是 1991 年,他当时正在开创一项如今在无人驾驶汽车领域早已随处可见的技术:教电脑开车。
这意味着要在一台军用悍马上安装一些特殊装备,并控制其在城市道路上行驶。当时的鲍莫里奥还是卡内基梅隆大学机器人专业的一名研究生。
那辆悍马上安装了一台电脑,可以通过对摄像头编程来解读路况,然后记住他针对各类情况采取的每个动作。鲍莫里奥希望这台机器最终能够通过这种方法学会自己开车。
鲍莫里奥会在驾车过程中为系统提供几分钟的训练,然后让它自行练习。一切似乎进展顺利——直到有一天,那辆悍马在靠近一座桥时突然转向一侧。幸亏他及时抓住方向盘,才避免了事故的发生。
回到实验室后,鲍莫里奥开始着手研究电脑的问题所在。“我的观点是要打开黑盒子,搞清楚它在想什么。”他解释道。但现在呢?他已经通过编程让电脑扮演了“神经网络”的角色——这是一种模拟人脑结构的人工智能技术,而且号称比传统算法更善于应对复杂的现实环境。
不幸的是,这类网络就像人脑一样捉摸不透。他们并没有把自己学到的知识明确地存储在数字存储器的某个位置,而是把信息分散开来,使得研究人员难以解读。直到对自己的软件在面对各种刺激时的表现展开了全面测试后,鲍莫里奥才发现了问题的根源:这套神经网络程序将长满草的路肩当成方向指引标志,所以桥梁的出现才令它感到困惑。
25 年后,解密黑盒子的难度急剧增加,也更加紧迫。人工智能技术本身在复杂程度和应用场景上也实现了爆发。
鲍莫里奥如今在卡内基梅隆大学兼职讲授机器人课程,他把那套固定在汽车顶端的系统描述为安装在现代设备上的“穷人版”巨型神经网络。所谓深度学习,其实是一套可以借助海量大数据对其进行训练的神经网络,这种技术正在获得越来越多的商业应用——从无人驾驶汽车到根据用户浏览历史推荐产品的网站,均属此类。
这还有望成为一项无处不在的科技。未来的射电天文学观测可以借助深度学习寻找有价值的信号,帮助天文学家应对难以处理的海量数据。引力波探测者也可以借此理解和消除最细微的噪音来源。而发行商同样可以利用这种技术过滤和标记数以百万的论文和图书。
一些研究人员相信,融合了深度学习技术的电脑最终甚至有可能具备想象力和创造力。“我们直接为其提供数据,它就会按照自然规律进行反馈。”加州理工学院物理学家简·洛奇弗里曼特(Jean-RochVlimant)说。
但这些优势恰恰也会导致黑盒子问题越发严重。例如,这些机器究竟是如何找到有意义的信号的?如何确定它们的结论正确与否?人们应该给予深度学习技术多大的信任?
“我认为我们肯定会屈从于这些算法。”哥伦比亚大学机器人专家霍德·立普森(Hod Lipson)说。他表示,这就好比碰到了一种拥有智慧的外星生物,他们的视觉受体不仅能感受到红、绿、蓝三种色彩,还能感知第四种颜色。人类很难理解这种外星生物看待世界的方式,而这种外星生物也很难向我们解释清楚。
他表示,电脑在向我们解释事情的过程中也会面临类似的困难,“从某种意义上讲,就像跟一条狗解释莎士比亚一样。”
面对这些挑战,人工智能研究人员开始采取与鲍莫里奥一样的应对策略——他们纷纷开始研究黑盒子里的秘密,并借助神经系统科学了解神经网络的内部原理。但欧洲核子研究组织(CERN)的物理学家文森佐·伊诺森特(Vincenzo Innocente)表示,目前得出的答案还不够深刻。“作为一名科学家,我们不仅要知其然,还要知其所以然。”他说。
技术原理
第一个人工神经网络创造于 1950 年代初,几乎是在能够执行算法的电脑诞生后立刻出现的。当时的想法是模拟“神经元”这种小型计算单元——它由大量的数字“突触”相连,呈层状排列。底层的每个单元吸收额外的数据(例如一个图片中的像素),然后将这些信息发送给下一层的部分或全部单元。
第二层的每个单元之后使用简单的数学规则融合从第一层吸收的信息,然后将结果进一步向上传递。最终,顶层便可得出答案——判断最初那张图片里的动物究竟是“猫”还是“狗”。
这类网络的优势在于它们的学习能力。利用附带正确答案的数据对其进行训练后,它们便可通过调整每个连接来大幅改进效果,直到顶层也输出正确答案为止。这一过程通过加强和弱化突触的方式模拟了人脑的学习方式,最终生成了一个网络,使之可以对从未见过的新数据进行归类。
在 1990 年代,这种学习能力对欧洲核子研究组织的物理学家形成了巨大吸引力,他们当时成为首批在科研工作中定期使用大规模神经网络的机构之一:在再现大型强子对装机的粒子对撞产生的亚原子颗粒轨道时,这些神经网络起到了巨大的帮助。
但这种学习模式正是信息在网络中如此分散的原因:与在大脑中一样,记忆会利用多重连接进行编码,而不是像传统数据库一样存储在某个具体的位置。“你电话号码的第一个数字存储在大脑的哪个位置?可能在很多突触上,或许距离其他数字不远。”加州大学欧文分校机器学习研究员皮埃尔·巴尔迪(Pierre Baldi)说。
但并没有明确的比特序列对数字进行编码。怀俄明大学计算机科学家杰夫·克鲁尼(Jeff Clune)表示,因此,“即使我们开发了这些网络,我们对它的了解仍然像对人脑的了解一样不够深入。”
那些需要在自己的学科领域处理大数据的科学家,在使用深度学习时则会保持一份谨慎。牛津大学计算机科学教授安德里亚·维达尔迪(Andrea Vedaldi)表示,想要了解背后的原因,可以设想一种情形:在不远的将来,可以使用最终患上乳腺癌的女性的乳房X光片对深度学习神经网络进行训练。
维达尔迪表示,经过训练后,机器便可从一个看似健康的妇女身上“看出”癌变。“神经网络可以学会识别各种迹象——这些性状有可能是我们尚不了解的,但却可以用于预测癌症。”他说。
但维达尔迪表示,如果机器无法解释它是如何诊断的,就会给医生及其病人带来严重的困惑。对一位女士而言,即使是自己的基因中含有可以大幅提升乳腺癌患病几率的遗传变异,也很难促使其下决心接受预防性的乳房切除术。而如果在不知道具体风险因素的情况下,她就更加难以作出决定——即便机器给出的建议可以实现很高的预测率。
“问题在于,知识被神经网络吸收了,但却没有被我们吸收。”谷歌生物物理学家迈克尔·蒂卡(Michael Tyka)说,“我们了解了什么事情?什么也没有——但神经网络却学到了东西。”
从 2012 年起就有一些团队开始研究黑盒子问题。一个由多伦多大学机器学习专家杰弗里·欣顿(Geoffrey Hinton)领导的团队参加了一次计算机视觉竞赛,并首次证明深度学习可以对 120 万张图片组成的数据库进行归类,处理能力远超其他任何一项人工智能技术。
在深入挖掘了背后的原理后,维达尔迪的团队利用欣顿开发的算法改进了神经网络的训练流程,并且采用了截然相反的运行模式。他们并未教给神经网络如何正确地解读一张图片,而是开始对网络进行预先训练,然后重构创建这些网络时使用的图片。这可以帮助研究人员确定机器是如何表现各种特征的——就好像他们在询问一个想象中的癌症诊断神经网络:“乳房x光片的哪个部分让你认为存在癌症风险?”
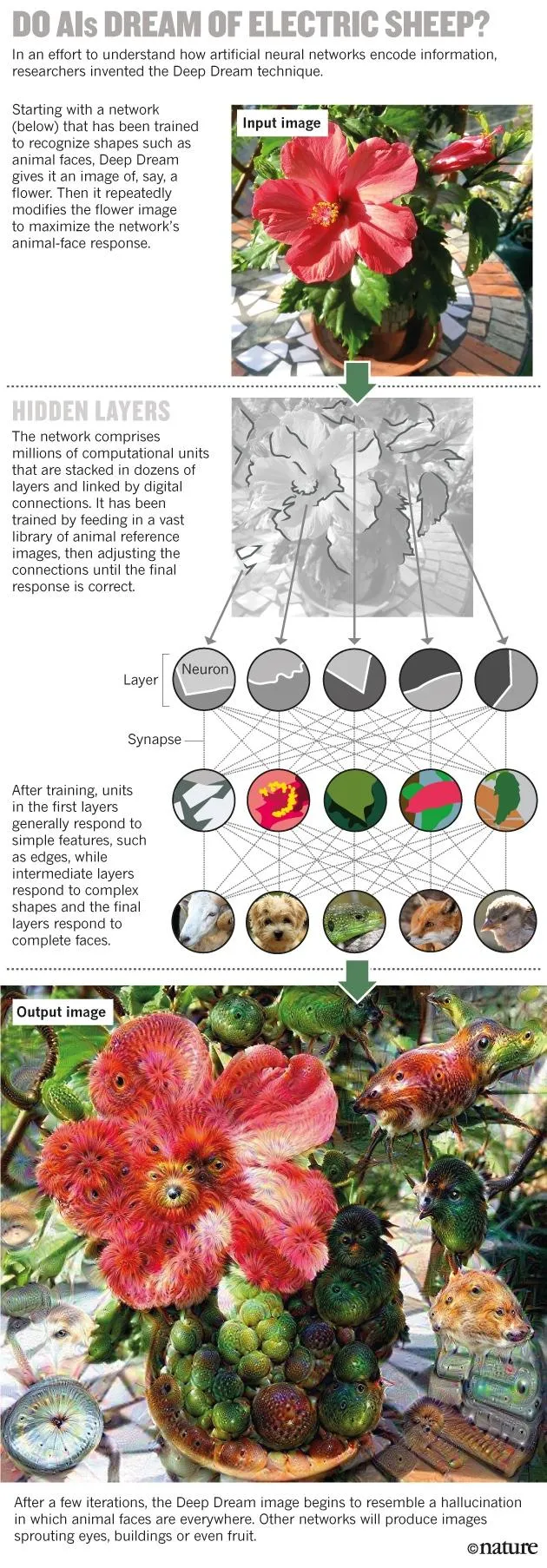
去年,蒂卡和其他谷歌研究人员也采用了类似的模式。他们的算法名叫“深梦”(Deep Dream),首先从图片开始(例如花朵或海滩),然后通过修改图片加强某些顶层神经元的反应。例如,如果神经元喜欢将图片标记为鸟,那么修改后的图片就会到处是鸟。最终的图片会调动起一场虚幻之旅,各种各样的鸟从人脸、建筑和各种图片中显现出来。

同时身为艺术家的蒂卡说,“我认为这更像一种幻觉,”而非梦境。当他和他的团队发现可以使用这种算法进行创作时,便对所有人开放下载。几天之内,“深梦”就在网上火了起来。
这些技术的作用对象不仅是顶层神经元,而是可以最大程度地加强任何一个神经元的反应。通过这些技术,克鲁尼的团队在 2014 年发现,黑盒子问题或许比我们想象得更加糟糕:令人意外的是,神经网络非常容易被愚弄,甚至只需要借助人类眼中的随机噪音或抽象图案即可实现。
例如,一个神经网络或许会将弯曲的线错当成海星,或者把黑黄相间的格子布错当成校车。不仅如此,即便通过不同的数据库对神经网络进行训练,这些形状还是会使其产生相同的反应。
研究人员提出了多种方法来解决这个问题,但目前还没有找到通用的解决方案。从现实应用的角度来看,这会引发很多危险。克鲁尼列举了一种令人尤其担忧的情形:图谋不轨的黑客可以利用这些缺陷:他们可以借此让一辆无人驾驶汽车把广告牌误认为是道路,从而引发事故;或者让虹膜扫描器把入侵者误认为是美国总统奥巴马,使之可以随意出入白宫。“我们得认真研究一番,只有这样才能让机器学习更强大、更智能。”克鲁尼说。
由于存在这些问题,一些计算机科学家认为,基于神经网络技术的深度学习并非唯一的解决方案。英国剑桥大学机器学习研究人员左斌·加拉玛尼(Zoubin Ghahramani)表示,如果人工智能的目的是解答人类可以轻松搞定的问题,“那就还有很多问题是深度学习无法解答的。”
立普森和前康奈尔大学计算生物学家迈克尔·施密特(Michael Schmidt)2009 年设计了一种相对透明的科研方法。这种名为 Eureqa 的算法能够通过观察相对简单的机械对象(一套钟摆系统)的运动重新发现牛顿力学定律。
首先从数学符号的随机组合开始,包括加号、减号、正弦、余弦,Eureqa 采用了受到达尔文进化论启发的试错法来不断调整,直到得出能够确切描述数据的公式。它随后会设计一些试验来检验自己的模型。立普森表示,这套算法的一大优势是简单。“Eureqa 生成的模型通常有 12 个参数,而神经网络则有几百万个。”
加强透明度
去年,加拉玛尼发布了一套算法,可以自动完成数据科学家的工作,从分析原始数据到撰写论文的整个流程都包含在内,他的这套名为“自动统计员”(Automatic Statistician)的软件可以确定数据库里的趋势和异常值,然后得出自己的结论,甚至对它的推理进行详细的解释。
加拉玛尼表示,这种透明性在科学应用中“至关重要”,对很多商业应用同样如此。例如,在很多国家,拒绝发放贷款的银行有义务阐述原因——深度学习算法或许就无法胜任这项工作。
奥斯陆大数据公司 Arundo Analytics 的数据科学总监艾利·多布森(Ellie Dobson)表示,很多机构也都怀有类似的担忧。如果英国利率的设定引发了什么问题,“英格兰银行不能简单地说一句‘黑盒子使然’就了事。”
尽管存在这些担忧,但计算机科学家还是认为,透明的人工智能是对深度学习的一种补充,而非替代。他们表示,一些透明的技术或许比较擅长解决已经被描述成一组抽象事实的问题,但感知能力——也就是从原始数据中提取事实的能力——却不够好。
最终,这些研究人员认为,机器学习提供的复杂答案必须成为科学工具包的一部分,因为真实世界非常复杂:对于天气和股市等现象,可能根本就不存在既简单又全面的描述。“有些事情说不清楚。”巴黎综合理工大学应用数学家史蒂芬·马拉特(Stéphane Mallat)说,“如果你问医生,他为什么给处这样或那样的诊断,他或许会给你一些理由。但培养一个好医生为什么要花 20 年?因为很多信息是课本上学不到的。”
对巴尔迪来说,科学家拥抱深度学习技术时不应该过分担心黑盒子。毕竟,每个人的脑子里都有一个黑盒子。“你随时都在使用你的大脑,但你却时刻信任自己的大脑,然而,你其实并不了解大脑的工作方式。”