
曲晓峰,香港理工大学人体生物特征识别研究中心博士生。
近期,两个我曾使用过的云计算平台 Sense.io 和 getdatajoy.com,即将逝去。前者被收购,已经对个人用户关闭;后者即将在 2017 年 1 月 2 日关站。
在人工智能爆发的今天,两个本应是智能计算核心的云计算平台,不仅没有乘风而起、顺势化龙,却倒在了新时代的门槛上,不得不引起人深思。
Sense.io —— 按需分配计算能力
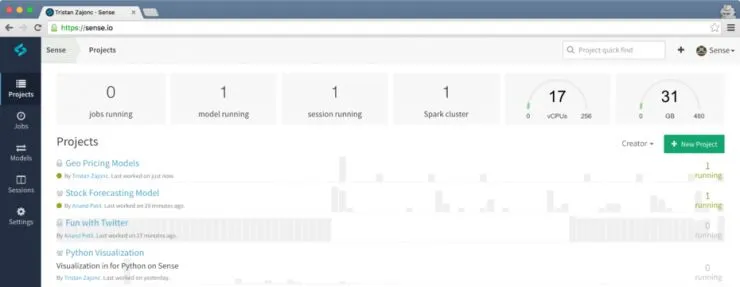
在 Sense.io 上,各个项目可以使用不同运算能力的平台,分别运行。单个项目可以使用多个虚拟 CPU 和或大或小的内存空间。
Sense.io 是一个面向数据科学家的可以动态分配计算能力云计算平台,简单说来就是“数据科学家的 GitHub”。在 Sense 上,数据科学家可以与其他人协作,并生成数据报表。
2016 年 3 月 22 日,Sense 宣布被大数据软件公司 Cloudera 收购。Sense 的创始人 Tristan Zajonc 和 Anand Patil 在 Sense 的博客上发布了被收购的公告,同时宣布免费和个人服务 2016 年 4 月 31 日关闭。
在 Sense 上,用户可以直接用 Python、R、Julia 编写代码,进行算法实验,构建模型,然后根据算法需要和成本综合考虑,选择具有合适运算能力的云计算平台(虚拟 CPU、内存)运行,然后输出、保存结果。运行的程序,可以是一次性的函数,也可以使用一种类似 Jupyter 的交互式执行环境来单步执行,分别看输出的结果。输出的结果可以是数据文件,如 CSV,可以是 png、jpg 等格式的图片,又或者可以用 javascript 动态图表展示出来。最后也可以生成 markdown、pdf 的报告。
我曾经用 Sense.io 进行过一些数据分析。其最大的优点就是运算能力可配置的特性。在进行实验的初期,使用稍小的运算能力,用单 CPU 检查数据,调试算法,检验假设。当实验流程比较清晰明确,代码跑通之后,就可以换用大运算能力,用 16、32、64 核和大内存载入所有数据进行运算,尽快获得实验结果。尤其是同一方向的实验,可以简单地通过复制项目,修改参数、添加函数或者调整流程,迅速并行展开多种实验。数据可以上传到同机房的 AWS 数据服务器,如:S3、DynamoDB、或者 Redshift,以方便不同项目共享访问或者同一项目的多次快速存取(sense.io 是搭建在 AWS 基础设施之上的)。
其实,做科研或者做商业数据分析都会遇到这样的问题,在构思算法或实验初期,并不总是在编程和运算,检查、清洗数据与思考占用前期大量时间。
直到有了比较清晰的方向,需要用数据和结果来验证想法的时候,才需要大量甚至是海量的运算。当然,两种情况是经常是交替进行的,一段时间慢慢思考调试;一段时间跑大量的数据来看整体的输出。在进行批量运算的时候,甚至会去抢别人的电脑来跑实验。使用 Sense.io 这种方案,可以有效充分地利用运算能力。一方面不至于在概念验证的初期就浪费大量的运算能力;另一方面,在需要的时候,可以迅速拓展克隆,在短时间内调动大量的运算能力迅速得到结果。
与现有的其他网站相比,Sense.io 更为灵活与已用。其预先配置好了编程环境,包括 Python、R 和 Julia 等数据分析最为常用的开源语言的开发环境,可以直接上手工作。不需要配置虚拟机、配置虚拟网络、安装系统、安装软件环境等一整套繁复的环境配置工作。
同时,协作与共享也变得相当简单。直接登陆在线帐户,进入同一个工程项目,就可以进行协作。或者直接克隆一个当前工作的镜像工程交给他人接手开发。
从服务器运营角度上看,这也是比较合理的方案。每个用户的使用峰值不同,不同用户错峰使用更能提高服务器的利用率。甚至,可以通过调整峰谷运算能力的价格,来进一步的平谷抑峰。
但可惜,被 Cloudera 收购后,Sense 已经对个人用户关闭,不知道 Cloudera 未来会不会开放 Sense 动态调整运算能力的技术。
DataJoy —— 学术文档与代码的融合
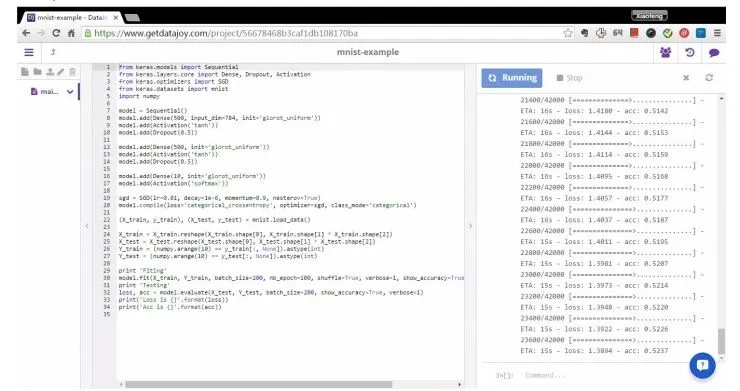
在 DataJoy 上运行基于 Keras 的全连接深度网络学习识别 MNIST 手写字符的例子。
2016 年 8 月 3 日,DataJoy 联合创始人 James Allen 和 Henry 向所有用户发送关站预告。宣布网站将于 2017 年 1 月 2 日关闭,届时账户将不再能登录,已付费用户账户余额将会退回。
DataJoy 是 ShareLaTeX 团队两年前上线的云计算项目。在 DataJoy 网站上,可以使用 Python 和 R 进行数据分析和编程学习。任何电脑,只要打开浏览器登录 getdatajoy.com 这个网站,就可以立即进行 Python 和 R 编程、调试、分析数据、输出结果,便于程序设计教学,免去了所有编程课程第一课安装软件配置环境的混乱场面,可以直接上手干活。而且一套稳定、随时随地可以访问、还可以简单克隆的环境,为从业人士提供了一个稳定、容易拓展和分享的标准工作环境。
DataJoy 团队在给用户发送的关站预告 email 里面说,市场上本已有很多成功竞品,所以竞争激烈。过去两年来,虽然 DataJoy 对少数用户很有帮助,但并没有大规模的流行起来。虽然,有些老师用 DataJoy 来进行 Python 和 R 的教学,但这并不足以支撑 DataJoy 的持续发展。商业上无法取得成功,技术团队还要维护 ShareLaTeX,就只能选择关闭 DataJoy 了。
简单来说,就是商业模式无法持续,没有盈利与投资,因此不得不关站。这其实也可以从一些侧面得到验证。在中文科技媒体上,完全没有任何相关新闻,只有一个旅欧学者的博客提到了这次关站事件。因此不得不说,DataJoy 在推广上确实还是做得很不够。
我也曾使用 DataJoy 进行过数据分析实验,甚至在其上跑通过 Keras 深度学习识别 MNIST 字符代码例子。但在进行我自己的卷积神经网络实验的时候,DataJoy 的运算能力就远远不够了。本身 DataJoy 服务器的运行速度相对就比较慢,又设置了单个项目的运行时间的限制,即使我付费购买延长项目运行时间之后,也远远不够进行实验所需的运算能力。这里可能也是与 DataJoy 网站的市场定位有关。DataJoy 与 Sense 的定位不同,不是专门针对数据分析,而是针对编程入门教育。但其实也很有可能是因为 DataJoy 的运算能力有限,使得其只能被限制在教育和运算能力有限的应用上。但 DataJoy 的界面与交互确实还是非常贴心的,毕竟有 ShareLaTeX 维护的经验。
单纯从站点本身的功能来看,DataJoy 并不突出,但考虑到其运营是 ShareLaTeX 团队,它的成长本是非常令我期待的。个中原因有一点复杂,涉及到一个复杂的问题。
在学术领域,科研结果的可重复性,一直是一个令人头疼的大问题。在计算机领域,经常是在发布论文的同时,再发布一份相关方法的代码。但毕竟是两个不同种类的工作,学术文档的撰写和代码的编制,确实很难对照。同时在科研进行的过程中,实验代码的编制与学术文档的撰写截然分开,也造成了科研进程的反复打断与切换的问题。
在R语言方面,近几年出现了一个革命性工具 knitr。
knitr 是由谢益辉博士在统计学博士在读期间业余开发的开源 R 代码包。谢博士毕业后进入 RStudio 公司专职进行 R 语言工具开发。使用 knitr,可以直接撰写带有 R 代码的实验记录、报告和演示文档。文档中的 R 代码,可以直接执行,并将结果输出到文档中,例如实验结果的数据、根据实验所花的折线图和对比实验的结果表格等等。这个流程与程序语言中的 Jupyter 有些类似,代码与文档交替撰写,源代码、数据分析结果与文档交替展现。
不同的是,knitr 可以把 Rmd(R 语言增强的 markdown 变种)编译生成为 text 文档,最终生成学术水准的可出版 PDF 文档。这个方案,使得学术写作、数据分析源代码和实验结果、甚至图表展示都融合到同一个流程中。首先,对于科研结果的可重复性,读者可以直接运行文档中的代码,重现实验结果。其次,对于科研流程也是极大的简化,科研工作流程及学术写作流程合而为一,得到了极大简化。
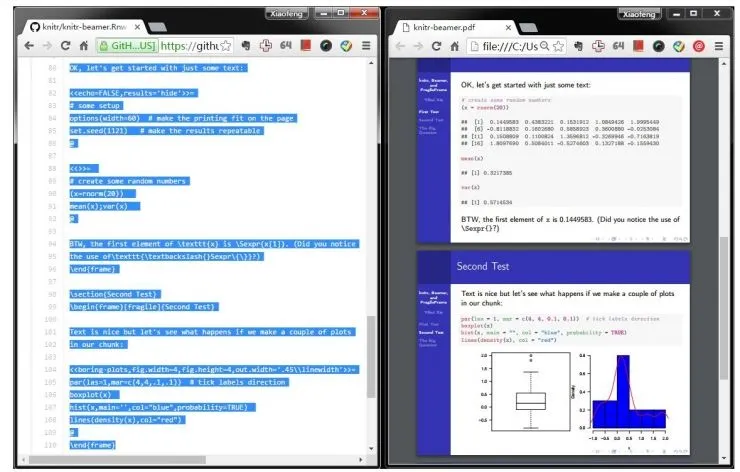
knitr 在 Beamer 中嵌入实验代码输出结果的例子。左侧蓝色的是 Rmd 文件原文,右侧是生成的 PDF 演示报告文档。由 `<<>>=` 开始,到 `@` 结尾的 R 代码块会自动运行。其中 `<<>>` 中可以写入对于放入文档的内容的输出控制参数。例如:`<<echo=FALSE,results='hide'>>` 就是抑制 R 环境的输出,完全隐藏运算中间步骤的结果。实验结果也可以直接用 R 语言分析后,直接绘图,并输出到文档中。注:Beamer 是 LaTeX 语言中常用来生成演示报告的宏包。
而 DataJoy 这个支持 Python 和 R 代码运行的云计算平台,由于其 ShareLaTeX (专业的在线 LaTeX 文档撰写平台)背景,给用户极大的想象空间。毕竟 Python 比 R 的普及程度高得多,各种数据分析、深度学习的代码库极为丰富,而且 DataJoy 的基础运行方式是非常容易进一步拓展支持更多程序设计语言的(参见 Beaker Notebook 支持几乎所有语言)。ShareLaTeX 与 DataJoy 如果能够有效的融合,学术出版、技术文档撰写、数据科学教学、程序设计教学、大数据以及人工智能的科研与教学会被全部打通。
可惜的是, DataJoy 完全没有走到这一步。不知道是团队对于 DataJoy 的定位问题,还是近期的资本寒冬造成这个概念无法继续执行下去。本来充满想象的大平台,就此走向孤立。
面向协作的云计算平台
云数据分析平台中除了开源的 Jupyter 和 beakernotebook.com 这种开源工具之外。商业运营的网站主要是面向大企业商业智能分析、金融量化分析和数据分析竞赛等少数站点取得了成功。主要原因就是数据分析虽然在相关行业内热炒,其实还是一个相对小众的领域。尤其在这少数业者之间,对于数据和算法的泄漏的担忧又加重了使用开放平台的疑虑。
只有在教育、学术、招聘等领域,由于其内生的开放特性,使得相关平台有一定的市场。但这就有了一个人口基数的问题。Facebook 的目标用户可以是世界上所有的人,现在月活达到十七亿;GitHub 的目标用户可以是世界上所有程序员,现有月活约百万;一个数据分析平台的目标用户,只是程序员中做数据分析方向的,又会有多少?该类网站相对来说难以成功就不难解释了。
但在中国,这又是另一个故事了。2016 年 7 月 15 日,汤森路透公司将知识产权业务和科学信息业务以 35.5 亿美元的价格出售给 Onex Corp 和霸菱亚洲投资。SCI 科学引用指数服务被母公司卖掉,为中国敲响了一个警钟。国智之依赖,举国学术科研的评估标准,不仅孤悬海外,更是被东鬻西卖搞商业开发。国家科研成果评估与选题导向被掌握在商业公司手里,国内的学术出版的发展刻不容缓。然而长期选用 SCI 作为评估标准又是有着不得已的苦衷。其客观、同行评议机制是长久以来中国学术科研的必要依赖。因此,客观、中立、公开的国内学术出版解决方案其实是有着强烈的需求的。
在计算机视觉、机器学习、人工智能的学术研究领域,近几年的学术文章流行这样一个套路:
PDF 文本发布在 arXiv;代码发布在 GitHub,以至于有专门的 GitXiv 提供此种论文和代码的索引。
由此推广开来,如果有足够资源的话,通过收购或者协作来打通一系列网站,来建立一个通用平台,来实现完整的科研、技术、产业生态链,包括: 一个类似 OverLeaf 或者 ShareLaTex 的在线学术文档协作撰写平台、一个类似 Sense.io 或 DataJoy 的协作云计算平台、极视角(extremevision.mo)算法变现平台、一个类似 Kaggle 的算法竞赛平台和一个数据托管平台。
国内的人工智能、机器人、机器学习、计算机视觉的学术科研与创业,都需要这样一个通用的云计算平台,来打通学术科研、学术出版、学术成果评估、在线数据分析竞赛与协作、科技人才选拔、学术成果转化等各个领域。在此,强烈建议有识之士建立一个这样的在线云计算协作平台。
结语
在云计算的时代,如何在“云”上攒一整套学术科研或者说数据分析工具链,是我近几年的主要关注点之一。现有的各种云服务遍地开花,但一直没有一个强烈的推动力将这些云服务打通融合。现在这个资本寒冬,反而为各个创业企业报团取暖,打通生态链,协作创新,优化提升提供了机会。希望数据创业者们能变危为机,成功闯过寒冬,打造新的数字化未来。