
2016年1月28日,谷歌围棋程序AlphaGo以5:0战胜职业棋手的消息,震动了围棋圈。这两天有很多的讨论,主要是新闻性的。我也在第一时间进行
了常识性的介绍。本文进一步从围棋和人工智能技术的角度,深入分析AlphaGo棋艺特点,评估其算法框架的潜能,预测与人类最高水平棋手的胜负。下文中出现的策略网络、价值网络、蒙特卡洛法请参考前文,理解具体围棋局面也需要一定的棋力,但是与算法推理相关的内容理解起来并不难。

AlphaGo是如何下棋的
所有人,包括职业棋手,看了AlphaGo战胜樊麾二段的五盘棋,都说这程序下得像人了,和以前的程序完全不同。柯洁九段(公认目前最强棋手,一年获得三个世界冠军,对李世石6:2,古力7:0)的看法是:
“完全看不出来。这五盘棋我也仔细地看了一眼,但我没看名字,不知道谁执黑谁执白,完全看不出谁是AI。感觉就像是一个真正的人类下的棋一样。该弃的地方也会弃,该退出的地方也会退出,非常均衡的一个棋风,真是看不出来出自程序之手。因为之前的ZEN那样的程序,经常会莫名其妙的抽风,突然跑到一个无关紧要的地方下棋。它这个不会。它知道哪个地方重要,会在重要的地方下棋,不会突然短路。这一点是非常厉害的。”
 连笑七段让四子对DolBaram,看看电脑是如何搞笑的。
连笑七段让四子对DolBaram,看看电脑是如何搞笑的。
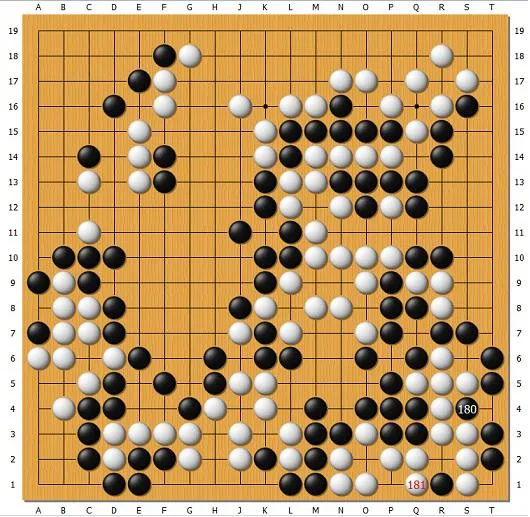
先来看我上一篇文章中提到的DolBaram被连环劫搞昏的局面。右下角白是连环劫净活,电脑却不知道,耗费了很多劫材来回打。这是因为电脑是用蒙特卡洛树形搜索(MCTS)下的,一直模拟下到终局,看各个选择的获胜概率。人一眼就知道打劫是没用的,你提这个我必然提回那个。电脑模拟时的选点却不会只有那一招,就会发现,如果对手不提另一个劫走了别的,那电脑就能吃角了,所以就去提劫。直到劫材损光,电脑才会恍然大悟,吃不掉,但这已经过去几十手,超过电脑的搜索能力了。

看到电脑被连环劫搞昏,乐开花的连笑
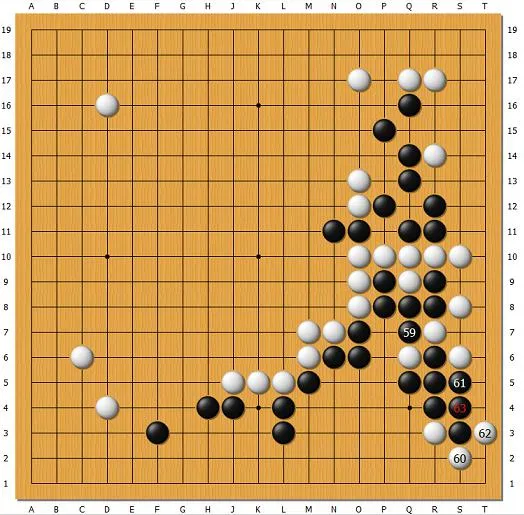
2014年日本UEC杯软件决赛,Zen执黑对CrazyStone。
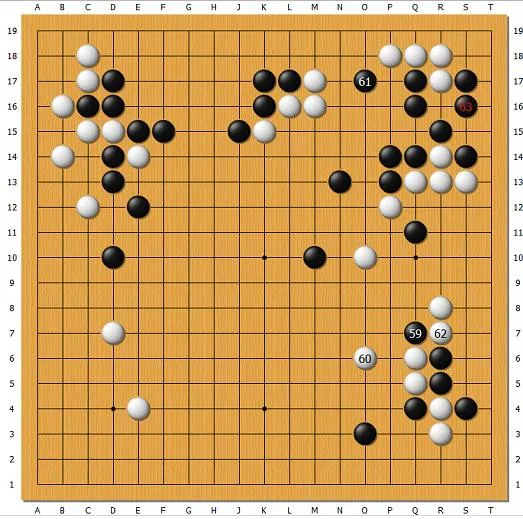
再来看Zen和CrazyStone两个过去最强的程序间的一个局面。黑61威胁白右上角和中上,白却不应,在下面62切断,黑继续63吃掉右上角。最后白在上面损失惨重,为了救中上几个白子,下面又被黑先动手,没有收益。为什么CrazyStone不应上面?因为程序没有价值的概念。白不应上面,黑要把白右上吃掉,还需要很多手,中上的白子活不活更不好说,这已经超出了电脑蒙特卡洛模拟的能力。因为电脑不知道要对着上面猛算,它不知道上面是焦点,可能花了很多计算在下面或者其它地方,认为62手下面切断胜算更大,上面的损失它模拟得不对。这个局面能说明蒙特卡洛树形搜索法(MCTS)的局限性,这个弱点很要命。
那么AlphaGo会如何解决这两个问题?连环劫问题,DolBaram可能得打个补丁。AlphaGo也是基于MCTS的,但是它的策略网络是深度学习高手对局的招法训练出来的,更为准确,有可能提劫这手就不会给多大概率,因为高手们面对这个局面不会去提劫。另一种可能是,AlphaGo有一个价值网络,不用来回打一堆劫就能直接判断下一招后,获胜机会如何。由于价值网络是训练出来的,包含了3000万局的最终结果,对于右下那块白棋的死活是有判断的。当然也可能AlphaGo针对连环劫有补丁。
CrazyStone犯错这个图,假设AlphaGo执白,在考虑第62手。61、62、63这些着手显然都会在AlphaGo的策略网络的选点中。你要让它用MCTS模拟出右上和中上白棋几个子是怎么回事,估计也是不行的,手数和分支太多。因为这不是一个简单的死活问题,白可以不要一部分甚至都不要,只要在其它地方有足够的补偿。但是AlphaGo有价值网络,它会在模拟到63手时,用价值网络快速评估一下,发觉白必败,于是迅速否定62这手棋,在上面下棋。因为价值网络的3000万个样本中,上面这种白棋类似棋形导致失败的棋局会有一些。
这里我们看出来,AlphaGo相比前一代软件的革命性进步,是有了一个价值网络。实际上,AlphaGo可以不用搜索,直接用策略网络给出一些选点,用价值网络判断这些选点的价值,选一个最好的作为着手,就可以做出一个非常厉害的程序。这个简单程序就可以打败其它软件,达到KGS(一个围棋网,人工智能程序一般在上面打级) 7D,这是非常惊人的。Facebook的Darkforest也可以不搜索,用策略网络给出一些选点,选其中概率最大的点(最像是高手下的那招棋),这样可以达到KGS 3D。在此基础上再加上MCTS,把Darkforest提升到了5D。这说明AlphaGo的价值网络对棋力提升的价值,可能比MCTS还要大。
有了高效的价值网络,AlphaGo就容易知道局面的焦点在哪,不会在非关键的地方走。可以预期,其它软件开发者要跟上AlphaGo,就得把价值网络搞出来。但是这非常难,需要模拟海量的对局,对局水平还不能低,需要的投入很大。
AlphaGo想要战胜业余高手,策略网络、价值网络就够了。但要战胜业余顶尖,就还得加上MCTS。这相当于对策略网络、价值网络的选择,进行验算。策略网络有两个,一个是给出当前局面的选点,一个是在MCTS模拟中快速给出一些选点。价值网络给出判断,有价值的搜得深。整个决策过程非常象人类高手的思维过程了:面对局面,给出一些选点;然后对各个选点推演下去,有的推几步就判断不行终止,有的会推得很远;有时算不清,就根据感觉下;有时没时间,直接感觉,都不推理了。
所以AlphaGo的算法框架很强大,和人类高手很像。而且它没有情绪波动,每一步都会稳定地用MCTS进行验算,人类不一定做得到。樊麾二段就是败在这上面,不少着都没有仔细验算,冲动地下了被AlphaGo反击吃大亏。
AlphaGo还不如人类高手的地方
分析AlphaGo的弈棋算法,可以相信,AlphaGo到了一定的局面以后就是必胜,因为它不会在此后犯错。实际之前的Zen、CrazyStone也是这样,到了后盘必胜局面,就靠MCTS,它们都能知道必胜了。这时电脑会下得特别猥琐,“赢棋不闹事”,胜多胜少一样。而人类高手后半盘胜局被翻盘很常见,官子没时间算清楚,稳定性比电脑差得多。
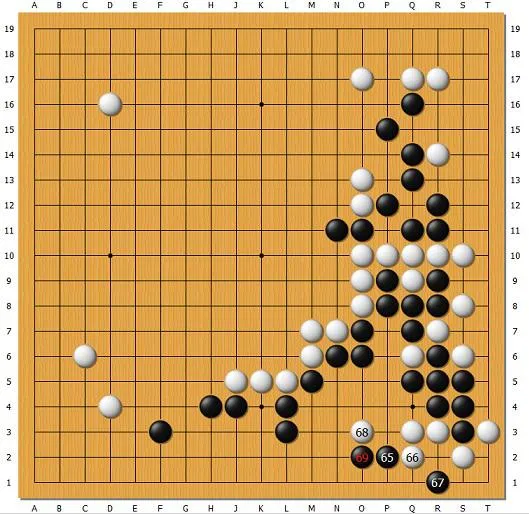
樊麾对AlphaGo的第二局就有这样一个局面。AlphaGo执黑,由于在右下角大占便宜,这时已经必胜了。黑下135,放白136活(如破上面的眼,白借O16的连出再做出一眼)。中韩职业高手刘星七段和金明完四段都指出,黑135右移一路,下在O18,是能够杀死白棋的。
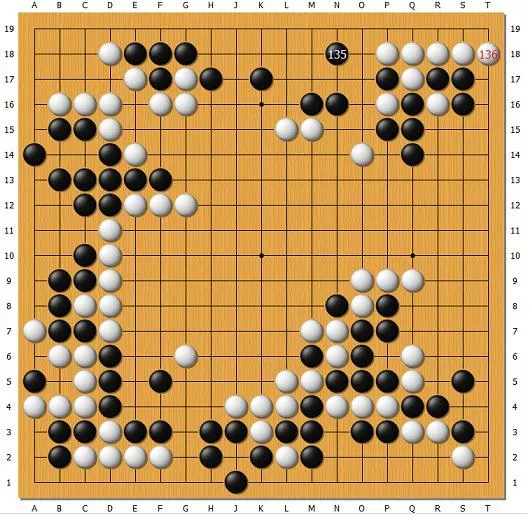
参考图
但是AlphaGo为什么不下?我们可以试着推理一下,如果黑强杀,接下来局面会是这样:
黑135下三角一着强杀,白提一子,黑137退。白138先手切断右上黑棋,虽然是靠劫。接下来白有ABC甚至更多“捣乱”的方法,但职业棋手一眼就能看出来,白的捣乱必然失败,因为白角也没几口气,还要撑劫,黑肯定能对付。但是AlphaGo作不出这种推理!
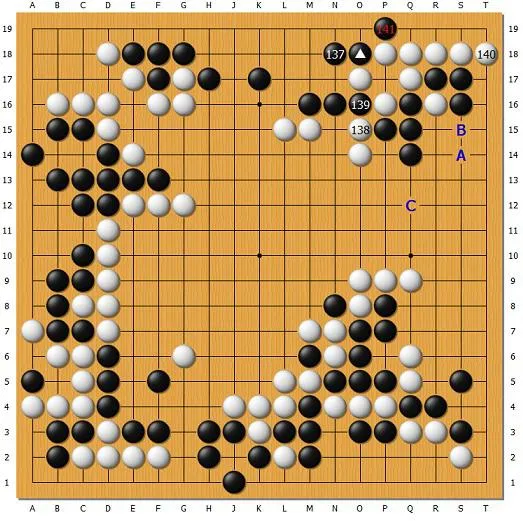
参考图
刘星说,AlphaGo肯定知道白是死的,但选择了稳当的下法。笔者认为恐怕不是这样。AlphaGo的搜索框架里,并不一定能断定白是死的,因为需要的手数不少,打劫虽然更不利于白,但增加了推理手数。它并没有一个搜索任务叫“杀死白右上角”。如果硬要去这么搜索是做得到的,但是如果它这样去想问题,棋力反而会下降,因为围棋很复杂,杀棋付出代价太多会败。AlphaGo推理时会发现,放活白,100%胜,杀白,有风险(虽然实际没风险,但它很可能没去算)。所以AlphaGo集中搜索放活的必胜下法,最后选择是放活。如果局面是不杀不胜,那AlphaGo就会发现其它招不行早早放弃,就会去集中算杀棋的那些招。
也就是说,一些对于人类非常明显的死活,对AlphaGo反而是麻烦的。人类高手在这个局面很可能就去吃棋让对手早点认输,因为没有任何风险。AlphaGo就不行,它没有分配足够的计算资源去算这个死活,而是去算它认为胜率更高的分支,这些分支要消耗非常多的MCTS局面。人类一眼能看出来的死活,AlphaGo却需要“足够”的计算资源才能算出来。有时因为局面的焦点问题,它还真就分配不出来。只有其它分支不行,被价值网络与MCTS早早砍掉,这块棋的死活才会获得足够资源算个通透。
这不会影响AlphaGo的胜利,但已经可以看出,它的思维其实和人不一样。它并不是一定能算清的,只有你逼得它没办法了,它才会去算清。但是人就有优势了,人看一眼就知道结果,AlphaGo以及基于MCTS的这些程序,都得去算不少步才知道。程序并不像人一样,对于棋块能给出结论。人给出结论需要计算,但是算一次就行了,然后就一直引用那个结论,直到条件变化。但是程序得去算,算到死了才是死,有一些局面计算甚至是活的,它只是概率性地在那选择,并没有给出确定性的结论。
再看一个局面,第三局樊麾执黑对AlphaGo。金明完四段指出白60扳,62打,都是走在黑空里的损着。还不只是亏空,本来白不走,右中的白棋粘在S7位,是有一个眼的,现在没有眼了,对中间的攻防战影响不小。
参考图
这是AlphaGo确定无疑的亏损错着。但是证明这个结论,需要黑能够对付白Q3长捣乱,要杀掉白右下。职业棋手也要花一点时间,但不难。结论是,因为中下的黑子够厚,所以没有棋。要是没有H4J4这两个黑子,就有棋了。这里涉及到的手数和分支是不少的,虽然结论是明确的。下面是一个白捣乱失败的参考图。
参考图
对于AlphaGo来说,这个局面就很麻烦了。如果逼得它不得不做活,它会用MCTS一直模拟下去,最后认为还是死。但现在局面还很空旷,局面选点很多,它并不知道去开一个“任务”算右下角的死活。
在很多高手对局里,类似这个角的局面就是有棋的,甚至没有棋,高手也会下类似60这样的棋“留余味”,例子很多。所以AlphaGo的策略网络会给出60这个选点。但是高手会迅速否定掉60,因为做不活,而且会损右中白棋的眼。
AlphaGo不会有“损眼”这种概念,它得模拟到很多步以后,才能知道右中的后手眼很关键。60提出来以后,MCTS救不了它,因为手数和分支太多。价值网络也救不了它,因为这里死了,白也只是吃了亏,并不是明显败局。价值网络背后的3000万局里,60及其后续捣乱手段可能出现过不少胜局,会给60这招一个好分。
这里我们能看出来AlphaGo的巨大不足了,它对于围棋中的很多“常识”其实是没有概念的,例如“后手眼”、“先手眼”,“厚薄”。有一定水平的人类棋手都明白围棋概念很多,开发者根本就没有准备去建立这些概念,而是自己想了一个决策过程。表面上看AlphaGo和人类高手一样先选点,再推理验算,但这只是表面的相似,内在机理是完全不同的。
AlphaGo的策略网络可能和人类最高手没有水平差别,甚至更厉害都可能,因为可以考虑更多选择。但是接下来的价值网络和MCTS验算的区别就大了。人类高手是进行复杂的概念推理,大多数情况下可以把“棋理”讲清楚,为什么这么选择,几个变化图就够了,高手们就取得了一致。但AlphaGo是不行的,它只能死算。在封闭局面,死算表现是很稳定,超过人类高手。但是在前半盘的开放局面,它不知道去算什么,其实也是东一下西一下没有逻辑地在那撞运气地推理。
由于围棋的复杂性,它增多推理的局面数并不能带来多高的棋力提升。Distributed AlphaGo(1202个CPU,176个GPU)的计算能力是“单机版”AlphaGo(48个CPU,8个GPU)的很多倍,但互下只有78%的胜率。
我们可以得出一个重要结论:
在早期的开放局面或者中间复杂局面中,AlphaGo的算法有时会走出明显吃小亏的错招,如果“思考”时需要较多的手数与搜索分支,就可能超过它的搜索能力。而人类高手能看出来程序的错误,有能力避免这类错,因为会进行高级的概念推理。这是人类高手的巨大优势。
为什么AlphaGo的这个弱点表现得并不明显?这是因为开发者用各种办法进行了“掩盖”,而且对手必须很强才行。这个弱点只对高手才存在,甚至象樊麾这样的职业二段都无关紧要。这局樊麾根本没利用白棋损了一眼这个错误,自己先在中间行棋过分被抓住。人类对手面对的各种考验更多,局部出了错被AlphaGo一通死算抓住就锁定败局完蛋。人类对手需要自己先稳住,不能出“不可挽回”的错着。就算是顶尖职业高手也不一定做得到,之所以出了错在职业圈里胜率还可以,是因为对手又送回来了。
AlphaGo开发者没有在程序中提出围棋常识概念,甚至所有开发者都不是高手(只有第二作者Aja Huang是弈城8d,高手让三四子都可能),很多高深的棋理不明白。但是他们用深度神经网络的办法,隐性地在多层神经网络中实现了很多围棋概念。为什么一个13层的神经网络,几百万节点系数相乘相加,就能预测高手在19*19的棋盘上的行为?通过训练,这些神经网其实已经隐含了很多概念,一层层往下推。所以它下的很像人,确实和人的神经系统类似。
机器用多层神经网络识别图片的能力,甚至超过了人。但在围棋上,这其实是一种“掩盖”。人识别图片时是没太多概念的,直接看出结果,机器也这样。但在下棋时,其实不是在识别棋局,还是有明确的建立在“常识”基础上的概念,越是高手概念越多,而且说得清,能教给学生,是一个知识系统。
AlphaGo的策略网络和价值网络,那些神经网络各层里,是些什么“概念”没人说得清,也不好控制。DeepMind小组其实也不想去搞清楚,就是暴力堆数据,信奉大数据暴力破解。
但围棋是很精微复杂的。某种概念,可能用几百个棋局能说明清楚。但是一大堆概念混在一起,有些概念还没有明确结论,怎么训练?比如前面的“后手眼”概念,人一解释很清楚,DeepMind的人想去改进程序让AlphaGo减少这类失误,就很麻烦。可能要去堆一大堆这类棋局进行训练。先不说能不能找到足够的棋局,在3000万个棋局里,加进一些棋局进行训练会产生什么影响,就很难控制。
AlphaGo的策略网络、价值网络、MCTS三大招数确实很强大,但也存在很不好解决的内在矛盾,就是没有概念推理的能力,很简单的都做不到。
AlphaGo与人类棋手对局预测
假设AlphaGo仍然维持现有的算法框架,但在持续的研究中,增加CPU,增加训练局数,打些小补丁,不断提升能力,那么可以对它的棋力进行推测。
这些改进就是让强的越强,但是本质的弱点无法消除。也许可以加一些程序代码,处理连环劫、多劫之类的bug型局面。AlphaGo的策略网络和价值网络已经很好了,对人类有优势或者不吃亏。AlphaGo的MCTS能力对于锁定胜局、抓对手大错误足够了,但还不足以消除自身的错误,增加CPU也不会有本质提高。虽然锁定胜局时,这种死算比人类更靠谱,但对于开放式局面仍然远不够用,这是算法本质的问题。
对于大多数业余棋手,AlphaGo只用策略网络和价值网络,连MCTS都不用,就能轻松获胜了。而且下棋速度特别快,只是算神经网络的输出值,0.1秒就可以,对人类等于不花时间。这个版本可以很容易放到手机上。
对于强业余五段、六段高手,PC版的AlphaGo可以一战了,需要用上MCTS,但不需要好到48个CPU。
对于顶尖业余棋手、冲段少年、等级分不高的二三线职业棋手,AlphaGo会有相当高的获胜概率,48或者1202个CPU只会在概率上有些小差别。当人类棋手在中后盘出小错,或者局部出恶手时,立刻就会输掉,无法翻盘。
对于顶尖职业棋手,AlphaGo会有较低的获胜概率。当顶尖职业棋手发挥好时,是可以做到没有明显错着的,甚至有个别方向性大局性的错误也不要紧,只要不是局部恶手被抓住。但是顶尖棋手状态不好或者心理波动的可能性是有的,甚至不小,所以AlphaGo也是有胜机的,甚至在三番五番棋中取得胜利都是可能的。
但是如果AlphaGo获胜,职业棋手们的评价会是人类出了明显的错着,而不是机器压倒性的胜利。反过来,人类顶尖高手如果发挥正常,可以对AlphaGo压倒性地全盘压制。
三月李世石与AlphaGo的对局,如果李世石输掉,一定是因为他出了恶手。而机器也会被多次发现明显的问题手,因为李世石总有能力在五局中表现人类的高水平。
这个情况有点类似于1997年深蓝战胜卡斯帕罗夫。卡斯帕罗夫输了,但当时不少舆论认为是他发挥不佳甚至收钱放水,后来直到2006年都有人类在比赛中战胜了程序。当然后来国际象棋程序越来越强,真正全面碾压人类棋手,甚至可以让人类一个兵或者两先,等级分比人类最强者高几百分。从当时的机器算法框架看,国际象棋程序彻底战胜人类只是个时间问题。
围棋的格局会有不同,不会被机器打得这么惨。如果开发者不提出新的算法框架,AlphaGo这样的人工智能程序无法战胜状态良好的人类最高水平棋手,甚至能看出明显的棋力短板。当然由于围棋人工智能不犯大错,抓错的水平很高,对职业棋手群体胜率会比较高,甚至参加世界大赛都有夺冠可能。但职业棋手们仍然掌握着最高水平的围棋技术,这些技术具有真正的艺术性,如果在和人工智能程序的较量中让世界认识到这一点,也有利于提高围棋的影响力。
AlphaGo已经取得的成就,无疑是非常了不起、令人震惊的。但通过仔细分析它的算法框架,人类棋手也不需要恐慌,它还达不到人类棋手的最高水平。当然不排除人工智能又搞出另外的高招取得突破,但这不好预测,而且会是非常困难的。
分析清楚AlphaGo的强大与不足,有利于破除迷信,“祛魅”。这也引出了更多哲学性的问题,例如:概念是什么?人工智能的极限在哪里?如何把人类积累的智慧和洞察力用到未来的人工智能科研中?
作者简介:笔名陈经,香港科技大学计算机科学硕士,中国科学技术大学风云学会研究员,棋力新浪围棋6D。21世纪初开始有独特原创性的经济研究,启发了大批读者。2003年的《经济版图中的发展中国家》预言中国将不断产业升级,挑战发达国家。2006年著有《中国的“官办经济”》。