
英文原文:Overview of Changes in Tensorflow Version 1.3
距离 Tensorflow 的 1.2.1 版本发布才过去一个月,但新发布的 1.3 版本已经包含了诸多更新。开发者可以在 Tensorflow Github 页找到完整的发布报告。本文则会概述开发者在升级到 1.3 版本之前和之后应知晓的最重要变化。
从 cuDNN 5.1 到 cuDNN 6
开发者要从 1.2.1 升级到 1.3,还需要升级系统中的 cuDNN 版本。1.3 的编译版本是用 NVIDIA 的 cuDNN 6 编译的,而 1.2.1 用的是 cuDNN 5.1。不想升级的开发者还是可以从源代码创建自己的编译版本。cuDNN 新版显著提升了 softmax 层的性能。cuDNN 6 新增的一个有趣的功能是膨胀卷积(dilated convolution),Tensorflow 已经支持此特性。需要注意的是,从 1.1.0 版本开始,Tensorflow 不再支持 Mac 上的 GPU。虽然开发者还是能得到补丁,但不能保证它能正常运行。
tf.contrib.data.Dataset 类
tf.contrib.data.Dataset 类获得了一些重要更新。开发者可以使用这个类为自己在 Tensors 中的数据创建统一的输入流水线,输入来源可以是内存、文件或磁盘,支持多种数据格式。它还能用来对使用 Dataset.map ()的各个独立元素应用函数,或者对所有使用 Dataset.batch ()的元素应用函数。这个类中缺少嵌套结构的函数现在把列表隐式地转换成 tf.Tensor 对象。不想用它的用户可以使用元组来代替。Dataset 类中还提供了几个新函数:
- Dataset.list_files (file_pattern):返回一个 Dataset,包含了与 file_pattern 模式相匹配的文件名字符串。
- Dataset.interleave (map_func,cycle_length):赋予程序员更大的自由度来处理函数到元素的映射。它仍会对整个 dataset 应用 map_func,但会交叉结果,这样有助于同时处理多个输入文件。
- ConcatenateDataset:用于扩展了 Dataset 类的一个类。它的 init 函数接受两个 Dataset 作为参数,通过已有的 Dataset.concatenate ()函数将它们连接起来。
要了解更多信息,开发者应该参阅 Github 上的开发者指南中关于使用 Dataset 类的说明。
高级 API 函数和统计分布
虽然 Keras 和 TFlearn 用户已有很多高级 API 函数可用,Tensorflow 又在库中增加了下列函数:DNNClassifier、 DNNRegressor、LinearClassifer、LinearRegressor、DNNLinearCombinedClassifier、DNNLinearCombinedRegressor。这些 estimator 是 tf.contrib.learn 包的一部分,使用方法可参阅 Tensorflow 文档。
新增的一项内容是多重统计分布。使用一个类表示一个统计分布,并用定义这个分布的参数进行初始化。现有很多单变量和多变量的分布。开发者也能扩展已有的类,但是必须继续支持 Distribution 基类中现有的函数。为避免无效的属性,开发者可以让程序抛出一个异常,或者选择用 NaN 值处理。下面的例子展示了开发者如何从一个均匀分布中获取一个带有随机变量的张量:

已有函数的改动
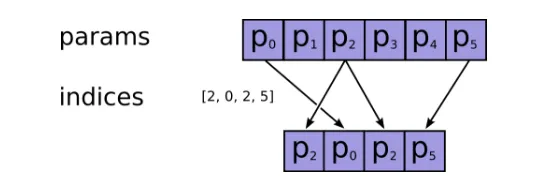
已有的函数也有一些改动。tf.gather 函数是用来在张量中选取变量的,现在加入了坐标轴参数,可以更灵活地收集数据。
tf.pad 函数用来在已有张量周围插入值,现在可支持“CONSTANT”实参。使用这个实参时,padding 到已有张量时会使用 0 来填充已有张量。之前已有的模式是“REFLECT”和“SYMMETRIC”。

留下你的反馈
虽然本文涵盖了多数重要更新,但开发者可能也想了解其他更新和功能。笔者请开发者们就 Tensorflow 1.3 版本补充更多内容,包括我忘记写上的内容、现有代码中发现的问题,或者其它任何内容,请在文后评论中留言。还没注册 InfoQ 的访客可以注册账号写下评论,为众多同行提供帮助。