
微软研究院对 MRC 领域迁移进行了首次尝试。他们最新提出的 SynNet 模型能在一个新的领域获得更准确的结果,而不需要额外的训练数据,并且网络性能接近全监督 MRC 系统。
雷锋网 AI 科技评论将其编译如下:
对人类来说,阅读理解是每天都在进行的基本任务。早在小学的时候,我们就能在阅读文章后,回答与文章的中心思想和细节相关的问题。
但对 AI 来说,完美的进行阅读理解仍然是一个难以实现的目标,但如果我们要评估和实现通用人工智能,就必须让 AI 达成这个目标。
实际上,许多现实生活中的场景,包括客户服务、建议、问答、对话和客户关系管理,都需要用到阅读理解。如果 AI 能完美的进行阅读理解,它将在一些情况下有惊人的潜能,比如在成千上万的文件中,迅速帮助医生找到重要的信息,让他们把时间用在更有价值的、可能会挽救生命的工作上。
因此,构建出能够进行机器阅读理解(MRC)的机器很有意义。比如在执行搜索请求时,机器理解将给出一个准确的答案,而不是抛给你一个网址,你需要点开之后在冗长的网页中找到答案。此外,机器理解模型能够理解狭窄和特定领域的文章中的知识,在那些领域中,支撑算法的搜索数据很少。
微软专注于机器阅读,目前正引领着该领域的竞争。微软的多个项目,包括用于机器理解的深度学习项目,也把目光投向了 MRC。尽管取得了很大的进展,但微软还是忽视了一个关键问题,这个问题直到最近才被注意:怎样针对一个新的领域构建 MRC 系统?
最近,微软 AI 研究院的 Po-Sen Huang、Xiaodong He 等多名研究员和来自斯坦福大学的实习生 David Golub 针对这个问题开发了一种迁移学习算法。他们将在 2017 年的顶尖自然语言处理会议——EMNLP 上介绍这种算法。这是开发出可扩展解决方案的关键步骤,可以将 MRC 扩展到更广泛的领域。
微软在朝着更大的目标在迈进,这种算法是他们取得进步的一个例子。他们想要用更复杂和微妙的能力来创造技术。
Rangan Majumder 在机器阅读博客上说过:“我们的目的不是建立一堆解决理论问题的算法,我们正在用这些算法解决实际问题,在实际的数据上测试他们。”
目前,大多数最先进的机器阅读系统都是建立在监督训练数据的基础之上,这些模型已经在样例上进行过端到端的训练。训练样例不仅包括文章,还包括与文章相关的手动标签的问题和问题相应的答案。
通过这些示例,基于深度学习的 MRC 模型学会理解问题并从文章中推断出答案,这包括多个论证和推理步骤。
然而,对于许多领域或行业而言,这种监督训练数据并不存在。例如,如果要建立一个新的机器阅读系统,来帮助医生找到与新疾病相关的重要信息,问题是:可能会有很多可用的文档,但是我们缺少与文档相关的手动标签的问题以及问题相应的答案。
这一挑战正在变大,因为我们需要为每种疾病建立一个独立的 MRC 系统,此外文献的数量正在急剧增加。因此,至关重要的是,要弄清楚如何让一个领域的 MRC 系统在另一个领域也能适用。在后面那个新的领域中,没有手动标签的问题,也没有问题相应的答案,但是有大量的文档。
微软的研究人员开发了一种新的模型——两级综合网络(SynNet),可以用来解决上面的问题。在这种方法中,基于一个领域中的监督数据,SynNet 首先学会一种通用模式,这种通用模式能识别文章中可能的关注点。这些关注点指的是关键知识点、命名实体或语义概念,通常是人们可能会问到的问题的答案。然后,在第二级,模型会学着根据文章内容,围绕可能的答案,形成自然语言问题。
训练好的 SynNet 可以应用于新的领域。它可以在新的领域中阅读文档,针对这些文档生成伪问题和答案。然后,针对那个新的领域,生成必要的训练数据来训练 MRC 系统。这个新的领域可能是一种新的疾病,一本新公司的员工手册,或是一份新的产品手册。
产生合成数据来对不足的训练数据进行补充,这种想法在以前就有过研究。例如,针对于翻译任务,Rico Sennrich 和他的同事们在一篇论文中提出了一种方法:根据真实的句子生成新的句子,用来完善已有的机器翻译系统。然而,与机器翻译不同的是,对于像 MRC 这样的任务,一篇文章需要既生成问题,又生成答案。此外,即使问题在语法上是流利的自然语句,答案通常是段落中某个突出的语义概念,例如一个命名实体、一段情节或是一个数字。由于答案与问题有不同的语言结构,因此将他们视为两种不同类型的数据可能更合适。
微软的新方法将产生问题-答案对的过程分成两步:先通过段落来生成答案,再通过段落和生成的答案,来生成问题。因为答案通常是关键的语义概念,所以会先生成答案。问题可以被看作组合起来的完整句子,用来询问前面的概念。 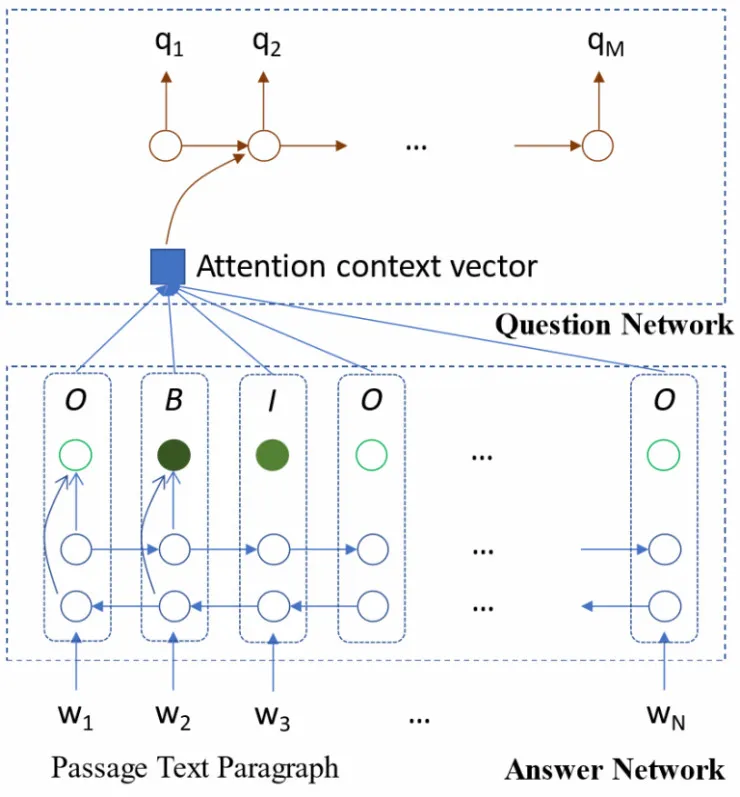
图:训练好的 SynNet 可以用于合成关于给定段落的答案和问题。模型的第一级是回答合成模块,使用双向长短时记忆网络(LSTM)来预测关于输入段落的输入、输出和开始(IOB)标签,这些标签标记出可能为答案的关键语义概念。第二级是问题合成模块,使用单向长短时记忆网络(LSTM)来生成问题,也生成段落中的嵌入词和 IOB ID。段落中的多个 span 标签会被识别为可能的答案,但在生成问题时,他们只选择一个 span 标签。
两个从文章中生成问题和答案的例子,如下图所示:


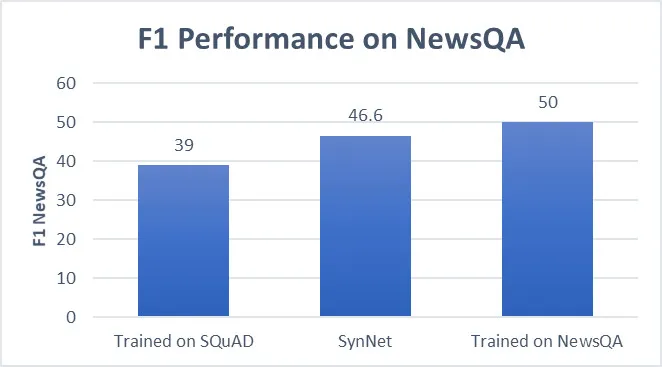
使用 SynNet 后,能在一个新的领域获得更准确的结果,而不需要额外的训练数据,并且网络性能接近全监督 MRC 系统。
SynNet 就像一名教师,根据她在以前的领域中学到的经验,从新的领域的文章中创造出问题和答案,并利用她的这些创造来教学生在新的领域中进行阅读理解。相应的,微软的研究人员也开发了一组神经机器阅读模型,包括最近开发的很有潜力的 ReasoNet 模型,这些模型就像是从教学资料中学习的学生,可以根据文章来回答问题。
据微软所知,这是进行 MRC 领域迁移的首次尝试。他们期待着开发可扩展的解决方案,快速扩展 MRC 的能力,进而释放出机器阅读颠覆性的潜力!