
本文由微信公众号“机器之心”(ID:almosthuman2014)编译,选自 Apple,参与:机器之心编辑部;
从 CoreML 到自动驾驶汽车,苹果的新技术探索在形成产品之前通常都会处于接近保密的状态,直到去年 12 月底,他们才以公司的名义发表了第一篇机器学习领域里的学术论文,介绍了自己在改善合成图像质量方面的研究。最近,这家以封闭而闻名的科技巨头突然宣布将以在线期刊的形式定期发表自己在机器学习方面的研究,而这份期刊的第一篇文章主要探讨的依然是合成图像的真实性,让我们先睹为快。(苹果机器学习期刊)
现在,神经网络的绝大多数成功实例来自监督学习。然而,为了达到高精度,数据训练集需要大且多元,并经过精确标注,这意味着高昂的成本。标注海量数据的一个替代方案是使用来自模拟器的合成图像;这很廉价,并且没有标注成本,但是合成图像缺乏逼真度,导致泛化到实际测试图像时效果欠佳。为了弥补这一性能差距,我们提出了一种新方法,可以改进合成图像使其看起来更逼真,并在不同的机器学习任务中取得了显著的精度提升。
概览
通过标准合成图像训练机器学习模型存在一定的问题,因为图像逼真度不够,导致模型只学习到了合成图像的细节,却无法很好地泛化到真实图像上。缩小合成与真实图像之间差距的一个方法是改善模拟器,这通常很昂贵和困难;即使最佳的渲染算法仍然无法对真实图像中存在的所有细节进行建模。真实度的缺乏导致模型对合成图像中的非真实细节产生了过拟合。我们可否不建模模拟器中的所有细节,而是直接从数据中学习呢?为此,我们提出了一种改善合成图像以使其看起来更逼真的方法。
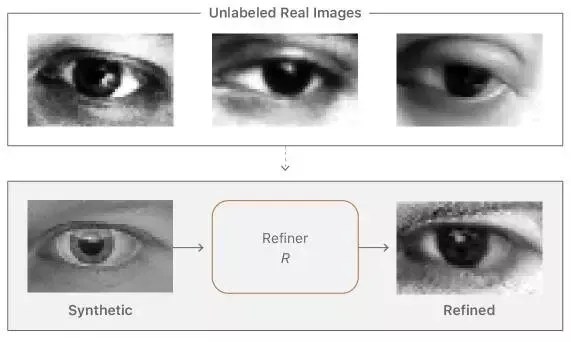
图 1. 该任务是借助非标注的真实数据学习一个模型,从而提高来自模拟器的合成图像的真实度,同时保留其注解信息。
提高真实度的目标是使图像看起来尽可能地逼真从而提高测试的精度。这意味着我们要为机器学习模型的训练保留注解信息。例如,图 1 中的注视方向应该被保留,同时不生成任何伪影,因为机器学习模型可能对它们产生过拟合。我们训练了一个深度神经网络——「改善器网络(refiner network)」,用来提高合成图像的真实度。
为了训练改善器网络,我们需要一些真实图像。一个选择是需要若干对真实与合成图像,且二者之间的像素相对应,或者带有注解的真实图像,如上图中的注视信息。这无疑降低了问题的难度,但是这样的数据对很难收集。为了实现像素的对应,我们要么渲染一张合成图像以对应于一张给定的真实图像,要么反之。我们可以无需像素的对应或者不对真实图像做任何标注而习得两者之间的映射,从而降低成本使其易于推广吗?
为了以无监督的方式训练改善器网络,我们借助鉴别器网络(discriminator network)来分类真实与改善的(假的)图像。改善器网络试图愚弄鉴别器网络,使其相信改善的图像是真实的。两个网络交替训练,当鉴别器网络无法区分真实与虚假图像时,则训练停止。鉴别器网络的对抗式使用和生成对抗网络(GAN)原理相类似。我们的目标是训练一个改善器网络——一个生成器——从而把合成图像映射到逼真图像。图 2 给出了该方法的概述。
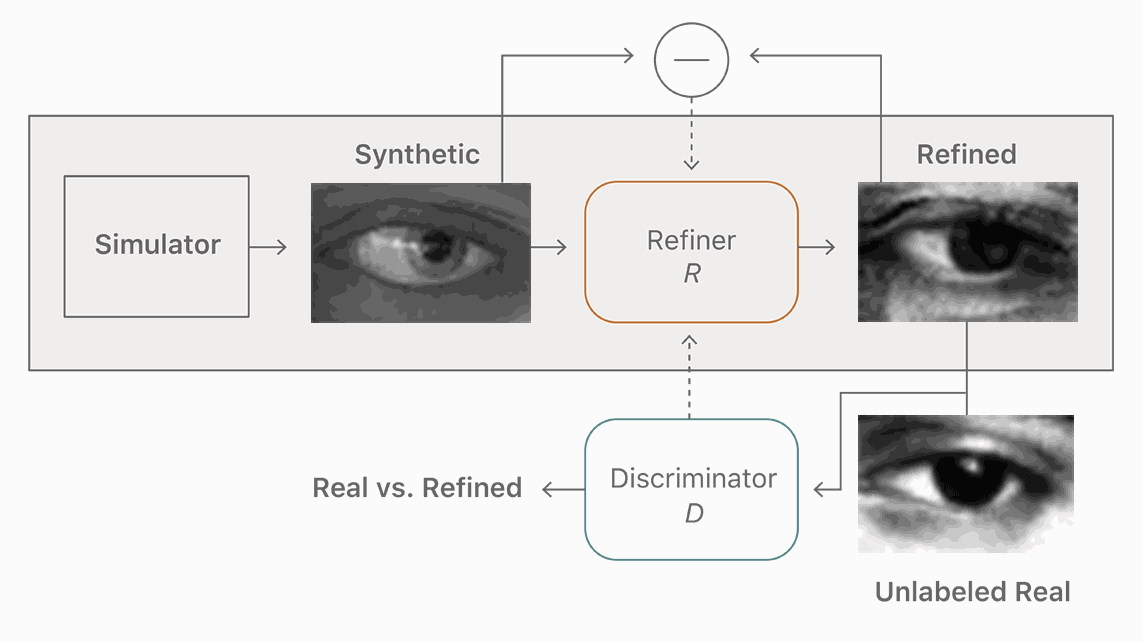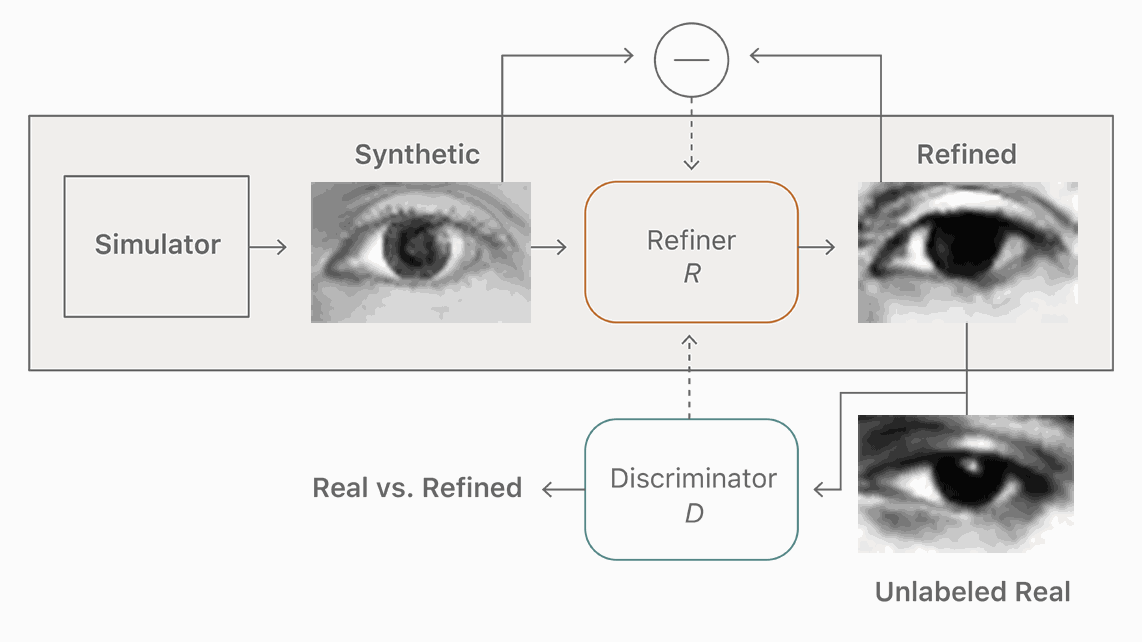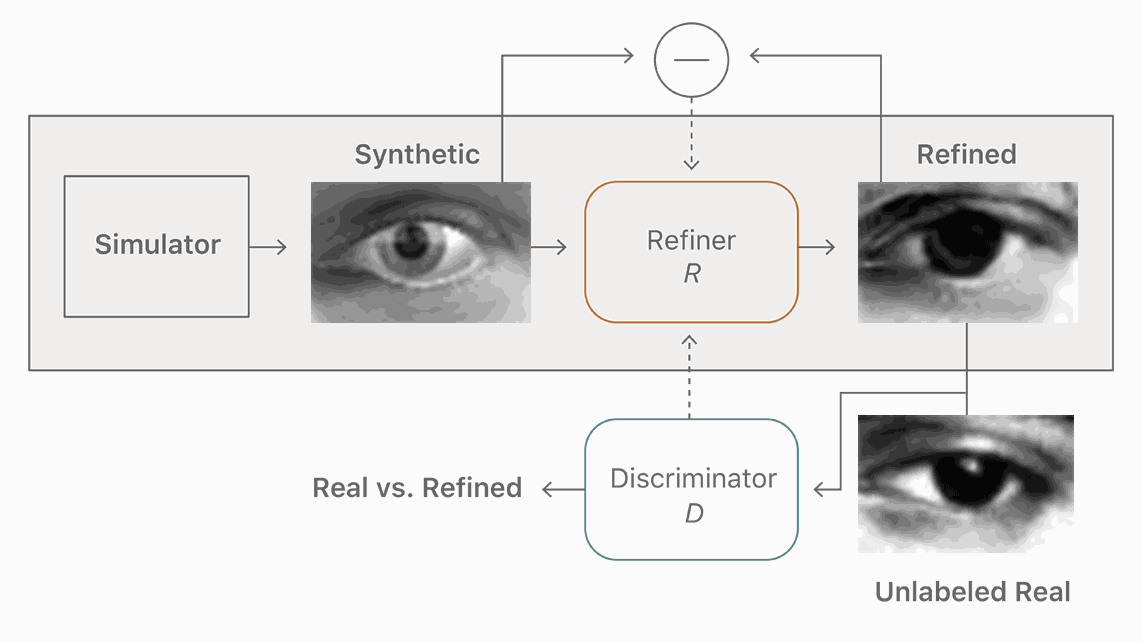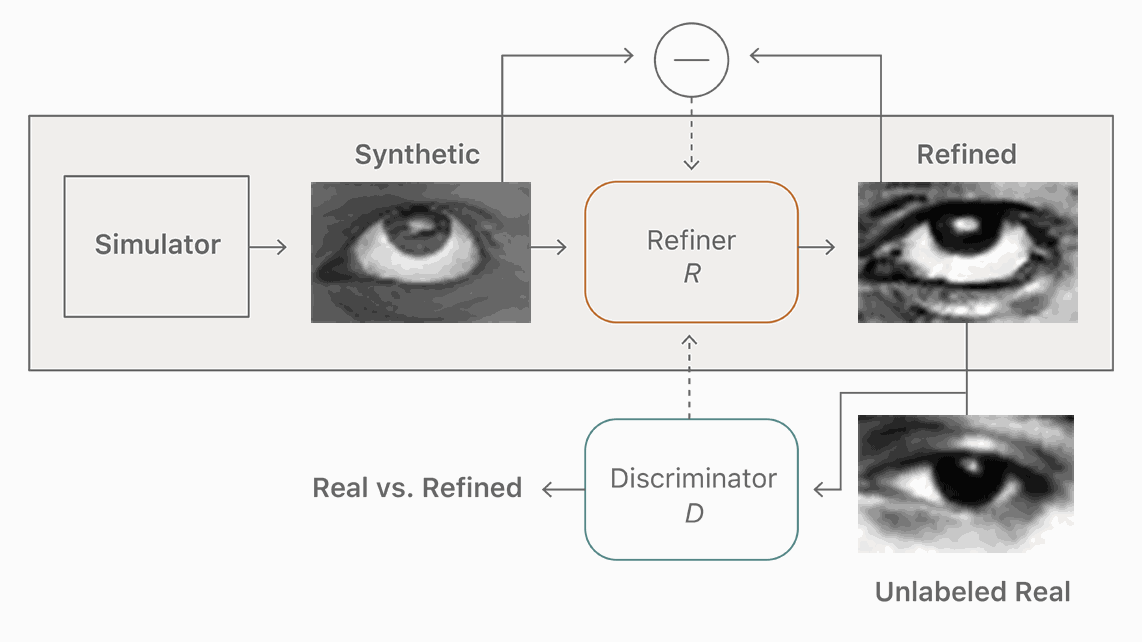
图 2. 我们的改善器神经网,R,最大限度地减少了局部对抗性损失函数与一个「自正则化」项(『self-regularization』 term)的结合。对抗性损失函数「愚弄」鉴别器网络,D,后者负责区分一张图片的真假。自正则化项最小化了合成与改善图像之间的差别。改善器网络和鉴别器网络交替更新。
我们如何保留注解?
除了生成逼真图像,改善器网络还保留模拟器的注解信息。比如,对于注视的评估,习得的变换不应该改变注视的方向。这一限制很关键,使得可以使用带有模拟器注解的改善图像训练机器学习模型。为了保留合成图像的注解,我们使用自正则化 L1 损失函数补充了对抗性损失函数,从而惩罚了合成图像与改善图像之间的大变化。
我们如何避免伪影?
制造局部变化
改善器网络的另一个关键需求是它可以引入任何伪影而学习建模真实图像的特征。当我们训练一个单一的强鉴别器网络时,改善器网络倾向于过度强调若干个图像特征以愚弄当前的鉴别器,导致了伪影的飘移和产生。一个关键的观察是,从改善图像采样的任何局部图像块应该具有与真实图像图像块相似的统计。因此,我们没有定义一个整体的鉴别器网络,而是定义了一个独自分类所有局部图像块的鉴别器网络(图 3)。该划分不仅限制了接收域(进而限制了鉴别器的能力),还为每张图像提供了很多样本以学习鉴别器网络。改善器网络也通过拥有每张图像的多个真实损失函数值而获得了提升。
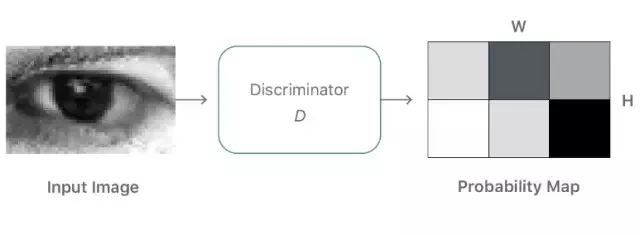
图 3. 局部对抗性损失函数的图式。鉴别器网络输出了一个 w × h 概率图。对抗性损失函数是局部图像块之间的交叉熵损失之和。
使用生成器的历史信息来改善鉴别器
生成器可以用一个新型分布或目标(真实数据)分布的样本来「愚弄」生成器。直到鉴别器学会那个新分布以前,新分布的生成结果都会对鉴别器进行「欺骗」。生成器愚弄鉴别器的更有效的方式则是通过目标分布(target distribution)来生成结果。
要想使这两种方式进化,通常最简单的方法就是生成一个全新的输出,也就是当我们用相互对抗的方式来训练当前生成器和鉴别器的时候所观察到的结果。这种无效序列的简单情况如图 4 左手边所示。生成器和鉴别器分布分别以黄色和蓝色区域来表示。
通过引入历史信息,即从先前生成结果中存储的生成器样本(图 4 右手边),鉴别器就不太可能会忘记它已经学习过的部分信息了。更强大的鉴别器帮助生成器更快地靠近目标分布。然而实际上,一个简单且随机的替换缓冲器(replacement buffer)可以从先前生成器的分布中采集足够的多样性。我们的观念是,在整个训练过程当中的任意时间,通过改善器网络生成的任何改善的图像实际上对鉴别器来说都是一个「假」的图像。我们发现,使用从历史信息缓冲器采集到的样本作为一半,以及把当前生成器的输出作为另一半,来给 D 建造一个 mini-batch,我们就可以实现对训练的改进。
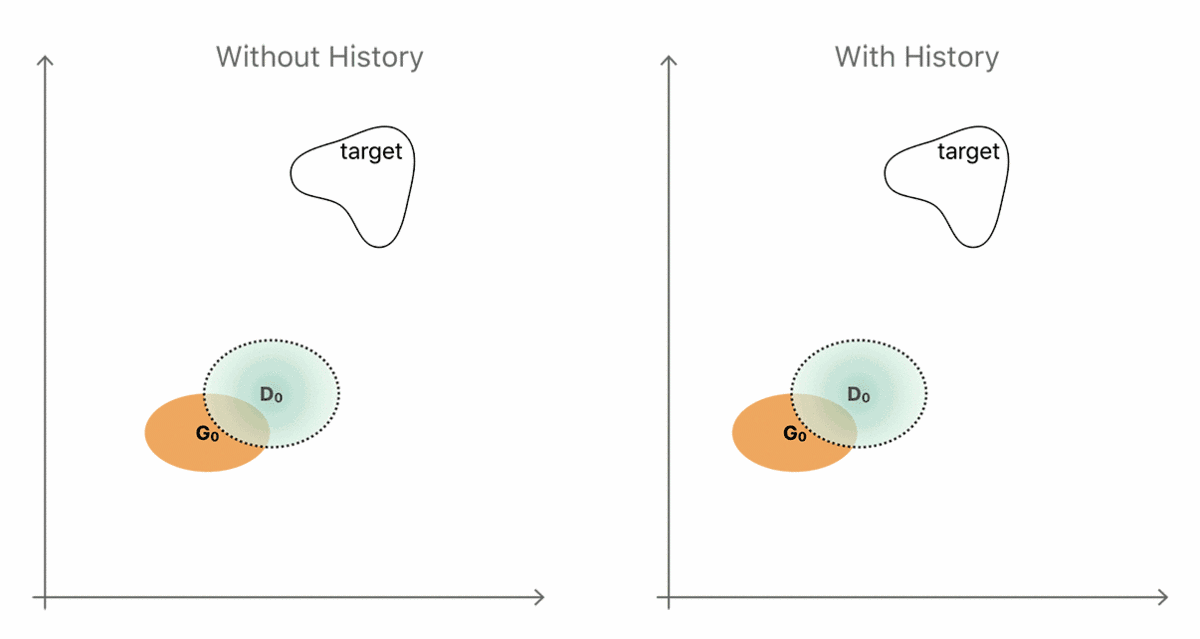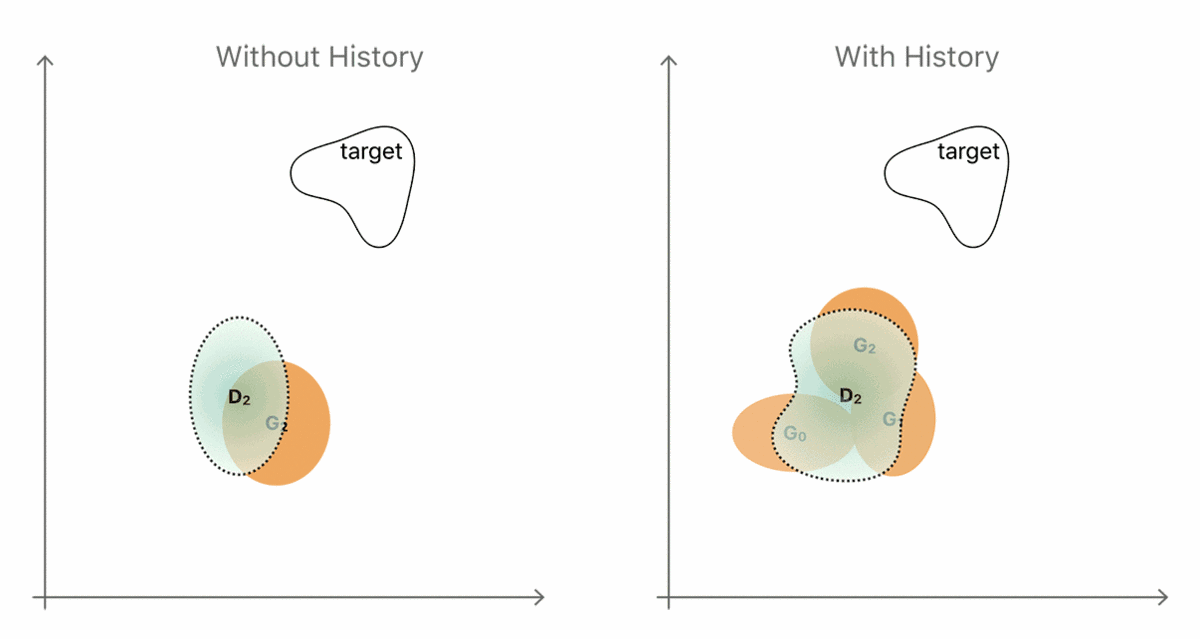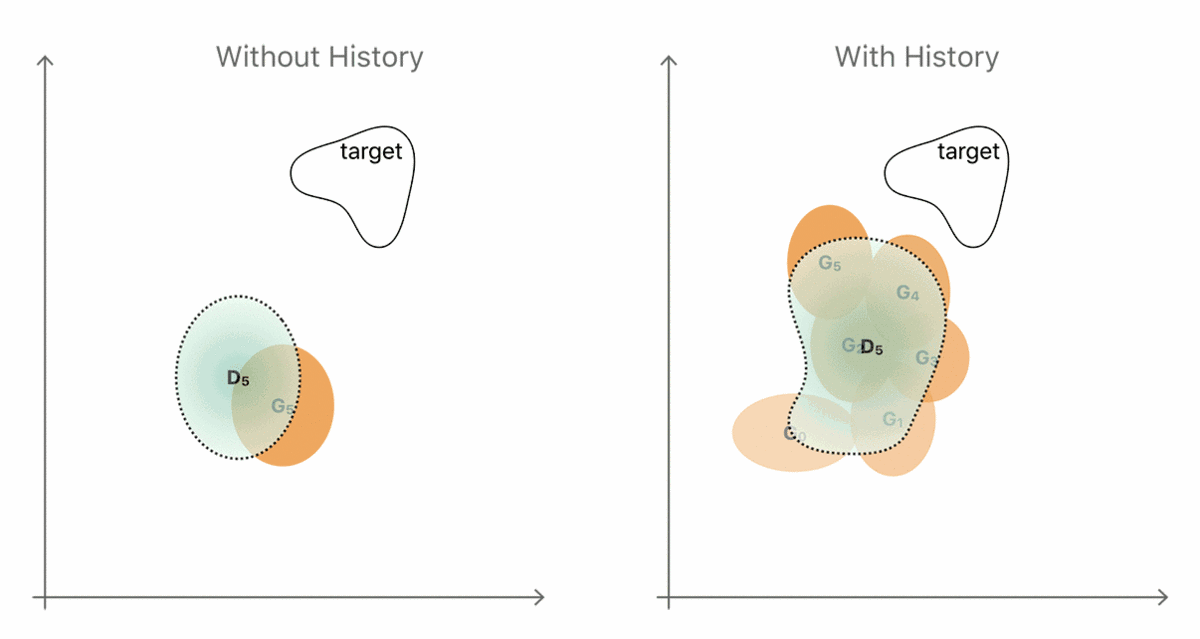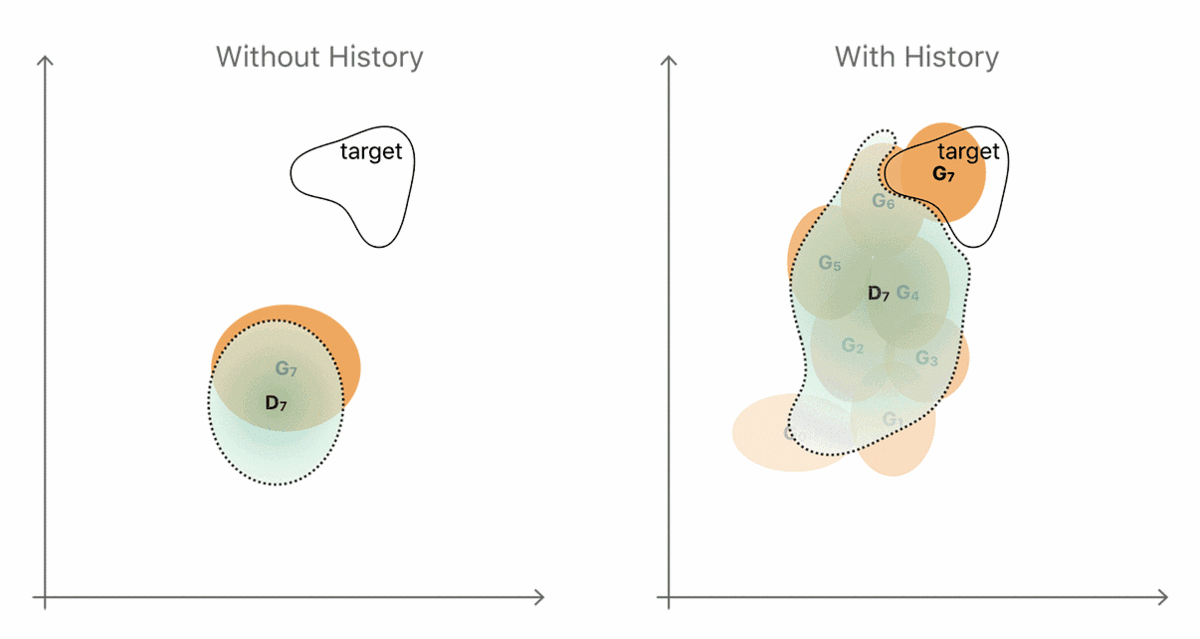
图 4. 使用图像历史信息提升鉴别器的直觉例证。
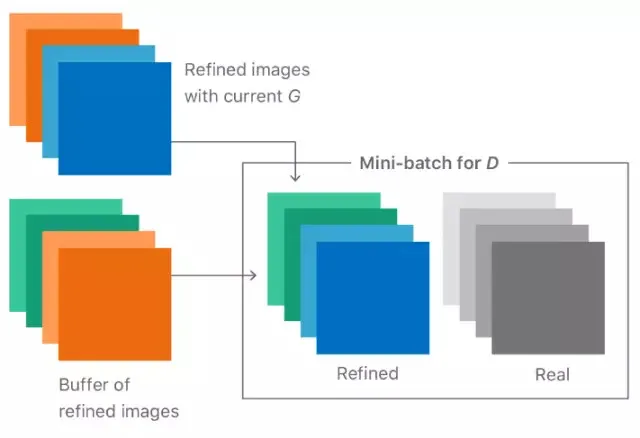
图 5. 带有 D 的历史信息的 mini-batch 例证。每个 mini-batch 包括来自生成器当前迭代的图像以及先前假图像的缓冲器。
训练过程如何展开?
我们首先训练改善器网络的自正则化损失函数,在改善器网络开始输出输入合成图像的模糊版本后引入对抗性损失函数。图 6 是改善器网络在每个训练步骤的输出结果。随着训练过程的进行,改善器网络输出的模糊图像越来越真实。图 7 是鉴别器损失函数生成器损失函数在不同训练迭代阶段的变化趋势。需要注意的是,一开始鉴别器损失较低,这说明该网络可以轻松区分真实图像和改善图像。随着训练过程的进行,鉴别器损失逐渐上升,生成器损失逐渐下降,改善器网络生成的图像也更加真实。

图 6. 改善器网络在训练过程中的输出结果。最初输出的图像比较模糊,随后改善器网络学习对真实图像中的细节进行建模。
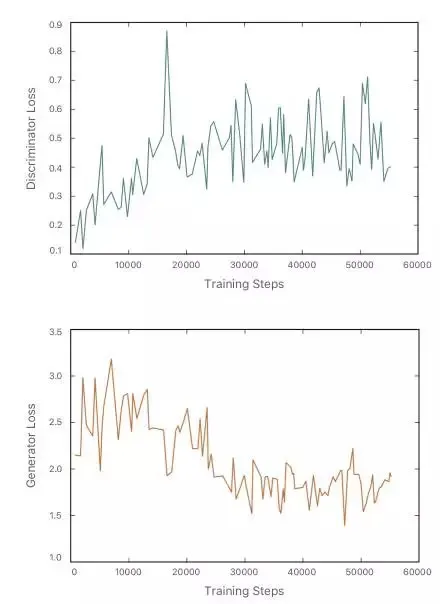
图 7. 训练过程中的鉴别器损失和生成器损失
自正则化 L1 损失有限制性吗?
如果合成图像和真实图像在分布中存在显著差别,那么即使是像素级 L1 的不同也会带来限制。在这种情况下,我们可以在特征空间上使用自正则项,用替代性特征变换(alternative feature transform)来替代标识映射。这些是手动调整的特征,或者习得的特征,如 VGGnet 的中层。如图 8 所示,RGB 通道可以生成真实的图像颜色。
图 8. 在特征空间中使用自正则化损失的实例。
生成器会改变标签吗?
为了保证标签不被大量改变,我们在合成图像和改善图像上手动画椭圆,并计算中心之间的距离。图 9 是 50 个此类中心区距离的散点图。合成图像和对应改善图像的瞳孔中心的绝对距离非常小:1.1 /- 0.8px(眼睛宽度 = 55px)。
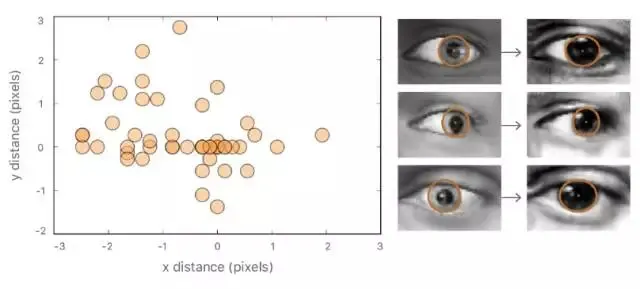
图 9. 合成图像和真实图像瞳孔中心距离的散点图。
如何调整超参数
G 的初始化
首先我们只在自正则损失中初始化 G,这样它就可以生成模拟版本的合成输入。通常 G 需要 500-2000 步(在没有训练 D 的情况下)。
在每个训练迭代中 G 和 D 的不同步骤
我们在生成器和鉴别器每一个训练迭代中使用了不同的训练步数。对于手势估算使用深度,我们在每个 D 的步数中使用 2 个 G 步数;而对于目视估计任务,我们最终找到在每个 D 步数中使用 50 个 G 步数能达到最佳性能。我们发现鉴别器与生成器相比,前者能更快地收敛,部分原因是鉴别器中有 batch-norm。所以我们将 #D 的步数修改为 1,并从小数字开始变化 #G 的步数,根据鉴别器损失值缓慢增加。
学习速率和 stopping 标准
我们发现让学习速率保持在非常小的数值上(约 0.0001)并训练很长时间能达到最好的效果。该方法有意义的原因可能是这样可以让生成器和鉴别器不会发生突变,让其中一个甩开另一个。我们发现很难通过可视化训练损失来停止训练。取而代之的是,我们保存训练图像作为训练进度,并在改善化图像看起来与真实图像相近时停止训练。
定性结果
为评估改善图像的视觉质量,我们设计了一个简单的用户调查,请参与者将图像按真实图像和改善合成图像进行分类。调查发现参与者很难区分真实图像和改善图像。经过综合分析,10 名参与者在 1000 次试验中选对标签的次数是 517 次,即他们不能确切地辨认出真实图像和改善合成图像的区别。但是,在对原始合成图像和真实图像进行测试的时候,我们向每位参与者展示真实图像和合成图像各 10 张。在 200 次试验中,参与者一共选对了 162 次。图 10 展示了一部分合成图像和对应的改善图像实例。
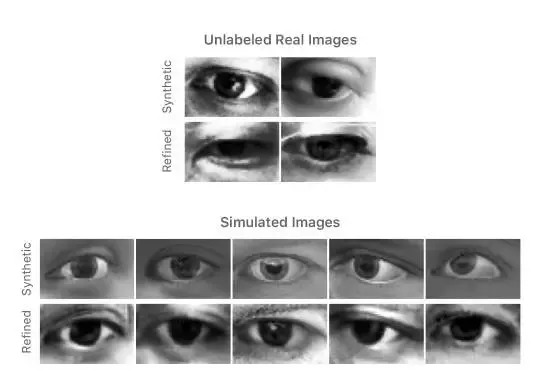
图 10. 使用上文所述方法改善后的眼睛图像实例。
定量结果
图 11 展示了使用改善数据的性能提升,与使用原始合成数据的训练效果相比。在下图中有两个重点:(1)使用精细图像进行训练优于使用原始合成图像的训练;(2)使用更多合成数据可进一步提高性能。在图 12 中,我们将目视估计误差与其他目前最好的方式进行了比较,展示了提升测试数据的真实性可以显著提高模型生成质量。

图 11. 使用合成和改善化图像进行注视估计的性能对比。评估使用了真实图片。
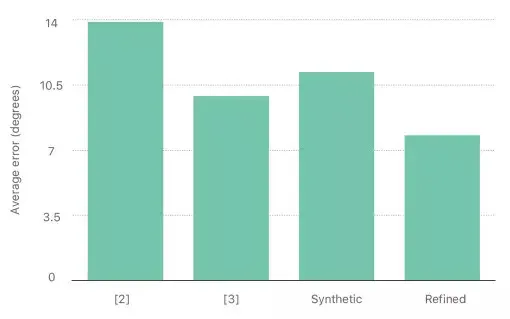
图 12. 在 MPIIGaze 数据集中不同方法之间的注视估计性能对比。
相关工作
近年来,使用对抗性训练方式的研究正在变得越来越流行。Isola 等人的图像到图像(image-to-image)转换论文 [4] 解释了一种将图像从一种形式转换为另一种的方法,但它需要像素级的对应。随后,该研究组又提出了非配对的图像到图像转换方法 [5],讨论了放宽对像素关联的限制,并根据我们的策略使用了生成器历史来提升鉴别器的能力。英伟达 5 月份提出的无监督图像到图像转换网络 [6] 使用 GAN 和变分自动编码器的组合来学习源域和目标域之间的映射。Costa 等人随后受我们的启发展示了生成眼底图像的研究 [7]。而 Sela 等人也使用了类似的自正则化方法来进行面部几何重建 [8]。Lee 等人从局部关键图像块上使用鉴别器来学习合成新的图片 [9]。若想获知有关本研究的更多细节,请查阅苹果的 CVPR 论文《Learning from Simulated and Unsupervised Images through Adversarial Training》[10]。
论文:通过对抗性训练从模拟和无监督图像中学习(Learning from Simulated and Unsupervised Images through Adversarial Training)

随着图像技术的最新进步,在合成图像上对模型进行训练也变得更加易于处理,一定程度上避免了对昂贵标注的需求。然而,由于合成图像分布和真实图像分布之间存在差距,从合成图像中进行学习往往可能不会达到所期望的性能表现。为了减小这一差距,我们提出了模拟 非监督学习方法(Simulated Unsupervised learning,S U),任务就是通过使用非标注的真实数据来学习一个模型,从而增强模拟器输出的真实性,同时保留模拟器中的标注信息。我们开发出了一种 S U 学习方法,使用类似于生成对抗网络的对抗型网络,用合成图像作为输入(而不是随机向量)。
我们对标准 GAN 算法进行了几处关键性的修改,从而来保存标注,避免失真以及使训练稳定化:(i)一个「自正则化」项,(ii)一个局部对抗损失(local adversarial loss),以及(iii)使用改善图像的历史信息来对鉴别器进行更新。
我们通过定性说明和用户研究,展示出了此结构能够生成高真实度的图像。我们通过训练视线估计(gaze estimation)和手势估计(hand pose estimation)的模型对生成图像进行了定量评估。我们在使用合成图像方面展现出了显著的提升效果,并且在没有任何已标注的真实数据的情况下,在 MPIIGaze dataset 数据集上实现了一流的结果。