
【环球智能7月13日报道 记者 心月】一年前,围棋人机大战AlphaGo击败人类,让人工智能正式进入大众视野。而开发出AlphaGo的人工智能公司 DeepMind也被众人所熟知。继围棋之后,DeepMind又有哪些新动作呢?
在上个月最新发布的论文中,DeepMind提出了一种基于认知心理学来研究深度神经网络的新方法。DeepMind 表示,对 AI 来说玩 Atari 的游戏或者下围棋,程序需要被设置的目标很简单,只要赢就行。但如果是让 AI 完成一次后空翻呢?你要怎样向机器描述后空翻的标准?于是他们开始研究训练 AI 穿越各种各样的地形,完成跳跃、转向、屈膝等相对复杂的动作。

模拟的“平面”无头步行者反复尝试翻墙
DeepMind 的研究人员已经训练了多个模拟机体,包括一个无头行者,一个四足蚂蚁和一个 3D 的模拟人体,通过完成不同的动作任务来学习人类更加复杂的行为。
在 DeepMind 的另一 篇论文中,阐述了如何通过运动捕捉数据来构建一个模仿人类行为的政策网络,需要预先学习一些技能,例如步行、起步、跑步和转弯等等。目前,模拟人已经产生了类似人类的行为,可以通过重新调整这些行为来完成其他任务,比如爬楼梯,通过导航绕过围墙等等。

DeepMind 还提出构建一种最先进的生成模型的神经网络结构,它能够学习不同行为之间的关系,并模仿它所显示的具体动作。经过训练之后, DeepMind 的系统可以编码观察到的动作,还可以创建新的小动作。尽管模拟人并没有看到动作之间的过渡,依旧可以在不同类型的动作之间切换,例如在行走风格之间的转换。

加强学习技术(reinforcement learning)是对 AI 深度学习实行干预的一个系统,通过使用这种技术,人类可以根据自己的意愿引导 AI 完成深度学习,在 AI 达到自己想要的效果时给以算法意义上的奖励,这样深度学习最后达成的结果就更接近人类最初所设想的。
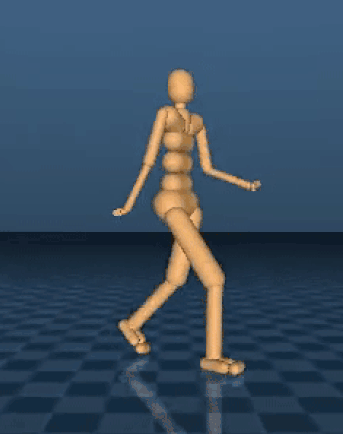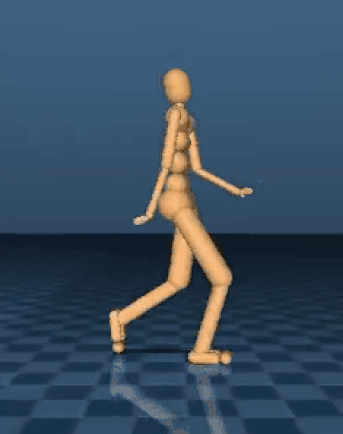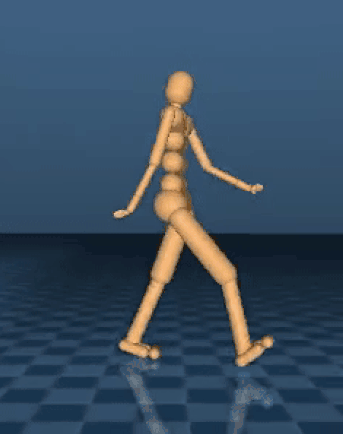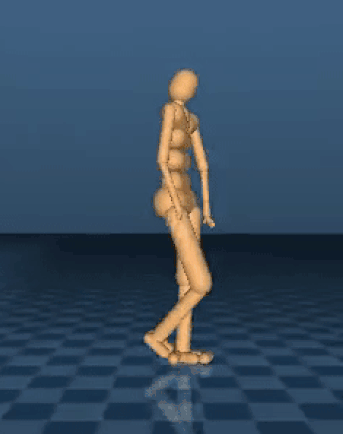

DeepMind 就使用了这种技术,并教会了 AI 模拟机体完成了一条跑酷路线。DeepMind 想知道这种简单的奖励机制能否在复杂的环境中使用,他们设计了一系列的跑酷路线,有落崖,有障碍,还有墙壁,每一次完成关卡都会赢得系统奖励。基本规则如下:最快突破障碍物的 AI 模拟机体将得到最大的奖励,更加复杂的项目将会得到额外的奖励和惩罚。


“结果显示我们的行动主体在没有收到特定指示的条件下学会了这些复杂的技能,证明了这种训练多种不同模拟机体的方法是可行的。”
事实上,目前市面上的机器人能做的事情还非常少,单是倒下后重新站起来就难倒了许多机器人研发机构。所以,虽然动图看起来有点蠢,但 DeepMind 的这项研究成果还是很有意义的。