
Attention 模型是近些年来自然语言处理领域重要的进展之一。注意力模型是从认知心理学中人脑注意力模型中引入的概念,在人观察世界时,对不同对象的关注程度是不同的,比如你在看书仔细品味文章中的一句话时,虽然你能看到整页的文字,但是注意力的焦点集中在这个句子上,其他文字虽然还在你的眼中,但是实际分配到的注意力是很少的。自然语言处理中也是同理,输入文本的不同部分对输出的贡献是不同的,即需要分配的注意力权重不同。使用注意力模型能够得到更好的生成结果。
由于标准的基于内容的 attention 机制主要应用在 sequence-to-sequence 模型中,由于该方法需要在每个时间状态下大量比较编码器和解码器的状态,因此需要大量计算资源。Google Brain 的研究者 Denny Britz, Melody Y. Guan 和 Minh-Thang Luong 提出了固定尺寸记忆表示的高效注意力模型,能够将翻译任务推理速度提高 20%。
以下为雷锋网 AI 科技评论据论文内容进行的部分编译。
论文摘要:
Sequence-to-sequence 模型在许多任务得到了最好的效果,例如神经机器翻译(Neural Machine Translation,NMT),文本概括(text summarization),语音识别,图像配字幕,以及对话建模等。
最流行的 attention 方法基于编码器-解码器架构,包含两个循环神经网络和 attention 机制使得目标与源符号对齐。在这种结构中使用的典型 attention 机制计算在每个解码步骤中基于解码器当前的状态计算新的 attention 上下文。更直观的说法是,这对应于每个单个目标符号输出之后查看源序列。
受人类是如何处理句子的启发,研究者认为在每个步骤中可能没有必要回顾整个原始源序列。因此,研究者提出了一种替代 attention 机制,可以使得计算时间复杂度的降低。该方法在读取源数据时,预测 K attention 上下文向量。并学习在每个解码步骤中使用这些向量的加权平均值。因此,一旦编码了源序列,就避免回头看。结果显示,这可以加速推理。同时,在玩具数据集和 WMT 翻译数据集上,该方法达到了与标准 attention 机制相若的性能。结果还显示,随着序列变长,该机制能够实现更多的加速。最后,通过可视化 attention 分数,研究人员验证了该技术能够学习有意义的对比,并且不同的 attention 上下文向量专注于源的不同部分。
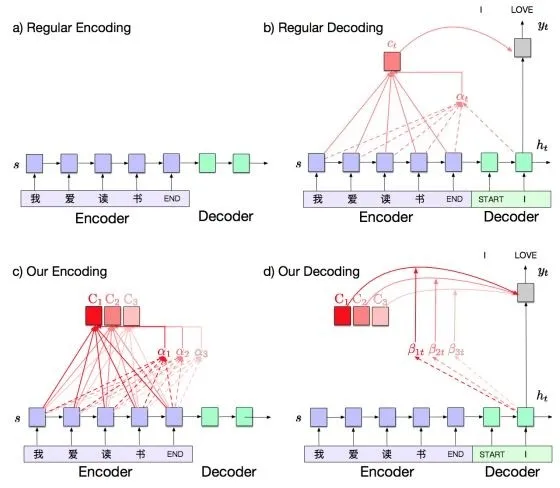
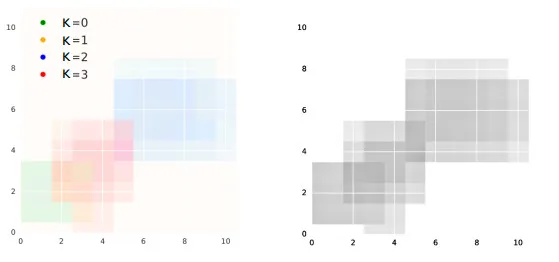
上图为该方法与标准注意力模型的结构对比。在编码阶段预测K个 attention 向量,在解码阶段线性组合这些预测。在上图中K=3。可以将基于记忆的注意力模型解释为“预测”编码期间由标准 attention 机制产生的一组注意上下文。如上图,K=3,在这种情况下,在编码阶段预测所有 3 种 attention 上下文,并在解码过程中学习选择合适的 attention 上下文,进行线性组合。这中方法比基于解码器编码内同的诸葛计算上下文更加节省计算量。
实验结果
玩具数据集结果:
由于计算时间复杂度的下降,该方法能够得到更高的性能表现,尤其是对于那些较长的序列,或者那些能够被紧凑表示为一个固定尺寸记忆矩阵的任务。为了研究速度和性能之间的权衡,研究者比较了该方法和标准模型在具有和不具有 attention 的情况下在 Sequence Copy Task 上的表现。
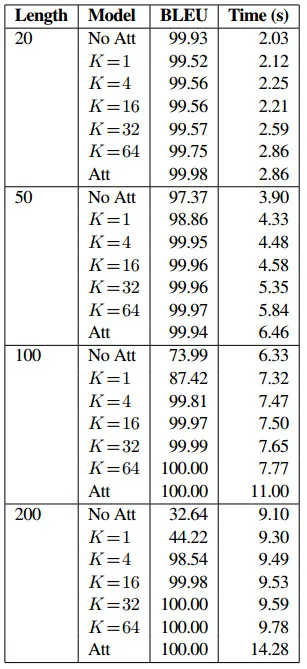
下表展示了该模型在不同序列长度和K的情况下的 BLEU 分数。较大的K可以计算复杂的源表示,值为 1 的K限制了源表示为单个向量。可以看到,性能一直随着K的增加而增加,这取决于数据长度,更长的序列需要更复杂的表示。无论是否具有位置编码,结果在玩具数据集上几乎相同。尽管表示能力较低,但该方法仍与标准 attention 机制模型一样能够拟合数据。两者都以显著的差距击败 non-attention 基线。最后一列表明了该方法能够极大的加速推理过程,随着序列长度变长,推理速度的差距越来越大。
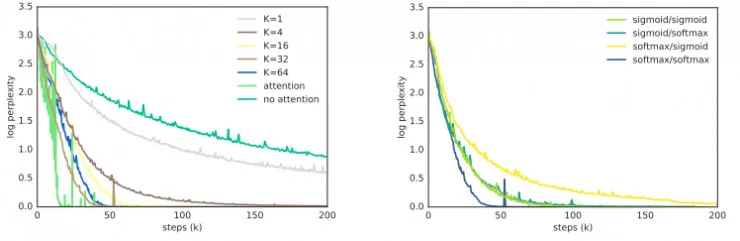
下图左侧展示了序列长度为 200 的学习曲线。可以看到K=1 不能拟合数据分布,而K∈{32,64}几乎与基于 attention 的模型一样快。越大的K能够导致更快的收敛速度,较小的K的性能与 non-attention 基线相似。右图展示了在 softmax 和 sigmoid 之间改变编码器和解码器评分函数的效果。所有组合都可以拟合数据,但有些收敛速度比其他更快。
机器翻译数据集结果:
接下来,研究者测试了基于记忆的 attention 方法能否拟合复杂的真实数据集。研究人员使用了 WMT’15 的 4 个大型机器翻译数据集:English-Czech, EnglishGerman, English-Finish, 和 English-Turkish。
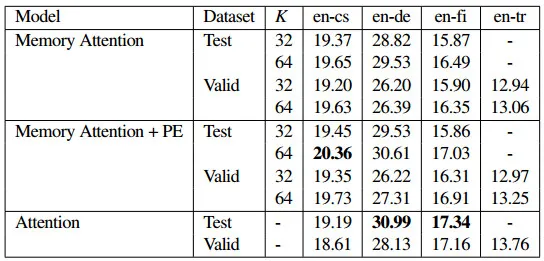
上表展示了该模型即使在拥有 16K 词汇的大型复杂数据集上仍有更快的解码速度。该时间实在整个验证集上测量的解码时间,没有包括模型设置和数据读取的时间,为运行 10 次的平均时间。数据中平均序列长度为 35,对于其他有更长序列长度的任务,该方法应该会有更显著的速度提升。
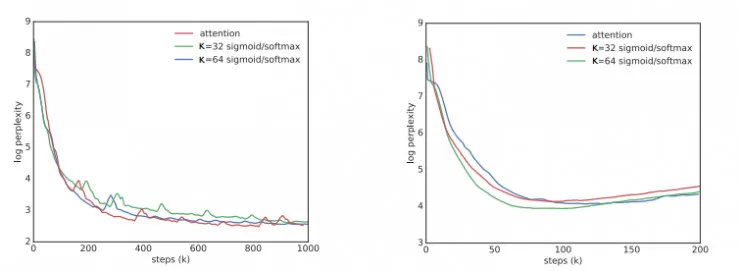
左:en-fi 的训练曲线 右:en-tr 的训练曲线
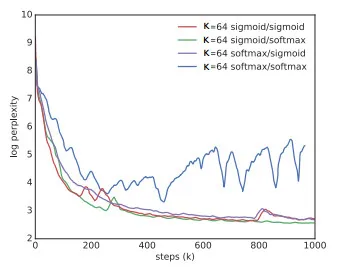
上图展示了在编码器和解码器中使用 sigmoid 和 softmax 函数的效果。Softmax/softmax 的性能表现最差,其他的组合表现几乎相当。
可视化 Attention:
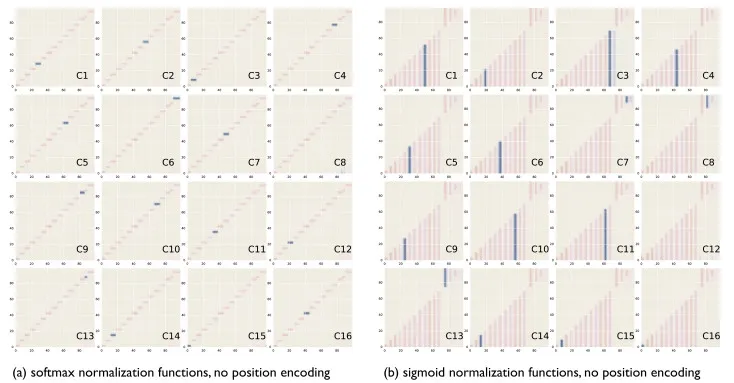
上图为在序列长度为 100 的玩具数据集中对每个样本进行解码的每个步骤中的 attention 分数。(y轴:源符号; x 轴:目标符号)
上图为在序列长度为 11 的样本上的K=4 的解码的每个步骤的 attention 分数,(y轴:源; x 轴:目标)
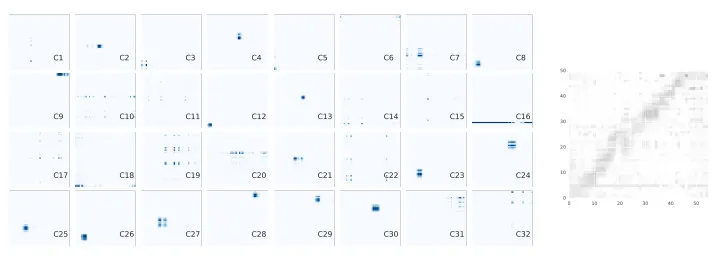
上图为在使用 sigmoid 评分函数和K=32 的模型下,对每个步骤进行解码的 en-de WMT 翻译任务的 attention 分数。左侧子图分别显示每个单独的 attention 向量,右侧子图显示 attention 的完整组合。
想要深入了解该方法的请阅读原论文:https://arxiv.org/abs/1707.00110,雷锋网编译