
雷锋网 AI 科技评论按:相比于 Facebook 和谷歌时不时发出机器学习方面的论文,国内 BAT 要显得沉默一点,拿出的非常前沿的成果也不那么多。但这可丝毫不能抹杀他们以实际应用问题为导向做出的努力。雷锋网了解到,阿里的技术团队就刚刚在 arXiv 上公开了一篇论文,用他们设计的深度兴趣网络(Deep Interest Network,DIN)解决准确预测点击量的问题。

团队背景
这篇论文来自阿里妈妈(阿里巴巴集团的大数据营销推广平台)的精准定向检索及基础算法团队,团队负责人是清华博士盖坤。他们团队的目的是帮商家更准确地预测用户的行为,投放更精准的广告——也就让用户更容易踏上剁手的不归路,说起来真是让人纠结。

盖坤(靖世)
据了解,盖坤本科毕业于清华大学自动化专业,然后直博模式识别与智能系统方向,毕业后就加入了阿里巴巴任技术专家,花名靖世,现在已经是阿里妈妈事业部精准展示广告技术部 P10 级别的技术总监。
盖坤在顶级期刊和会议(NIPS/CVPR/AAAI / TPAMI 等)上发表过多篇论文,前几年就提出过 MLR(Mixture of Logistic Regression,分片线性学习)算法用来提高阿里巴巴对广告点击率预测的准确度。相比传统线性模型,MLR 可以自动挖掘数据中的非线性模式,避免了大量人工特征设计;同时 MLR 引入的范数正则可以使最终训练出的模型有较高的稀疏度,模型的学习能力和在线预测能力显著高于传统线性模型。盖坤本人也对 MLR 做过一份 PPT 介绍,可以看这里 海量数据下的非线性模型探索 - 盖坤。
新结构 - 深度兴趣网络
这篇名为「Deep Interest Network for Click-Through Rate Prediction」的新论文展示了盖坤团队在广告点击率预测方面利用深度学习达到的最新进展。
深度学习在模式识别、非线性关联方面的优势吸引到了盖坤团队的注意,但是他们发现直接把基本的多层全连接神经元用来做训练和预测的时候会出现对用户历史行为数据利用不够好的问题,他们认为准确率还有进一步提升的空间。
通过观察阿里巴巴采集的用户历史行为数据,盖坤团队发现有两个指标对广告点击率预测准确率有重大影响,一个是“多样性(Diversity)”,一个用户可以对很多不同品类的东西感兴趣;另一个指标是“部分对应(Local activation)”,只有一部分的数据可以用来预测用户的点击偏好,比如系统自动向用户推荐的太阳镜会跟用户买的泳衣产生关联,但是跟用户买的书就没什么关系了。
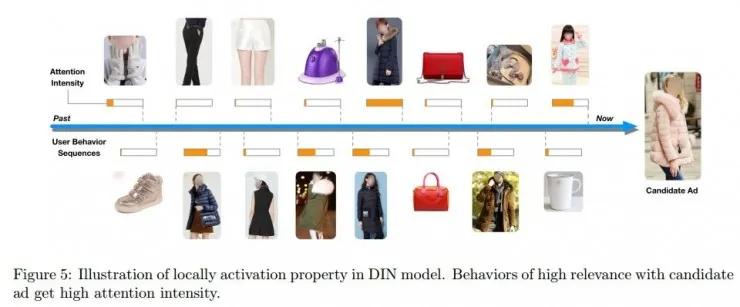
用户历史购买商品与广告中商品间对应程度的计算
基于这两个指标,盖坤团队受到用于机器翻译的注意力模型启发,对基本的多层全连接神经元架构(左图)进行了修改,从而提出了深度兴趣网络(Deep Interest Network,DIN,右图)的新结构。
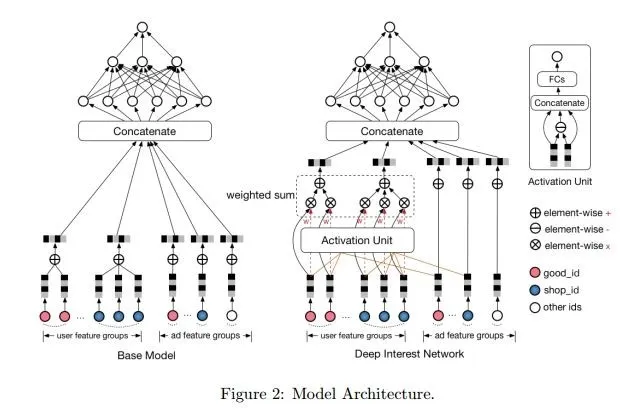
基本模型架构与 DIN 模型架构对比
DIN 把用户的兴趣看作一个分布,然后借助类似注意力模型的新增网络结构对用户的历史数据和待估算的广告之间部分匹配、计算权重,再输出给累加器和池化层,这样一来,匹配度越高的历史数据就对结果的影响越大。据论文介绍,这样的网络结构可以对多样性和部分对应两种指标都形成有效利用,而以往的网络模型是很难利用到部分对应这一指标的。
阿里巴巴在生产环境中测试了 DIN 模型,用 20 天的数据进行训练,用第 21 天的数据进行测试,使用的指标是论文中提出的泛化 AUC(基于用户的分组加权平均 AUC)。与基础模型对比,DIN 的准确性有可见提升,达到 1.08%。

基础模型与 DIN 测试结果对比
实现方法
除了新的网络架构本身,盖坤团队还在论文中介绍了一些为了顺利把模型用于生产所用到的方法。
把稀疏特征嵌入向量
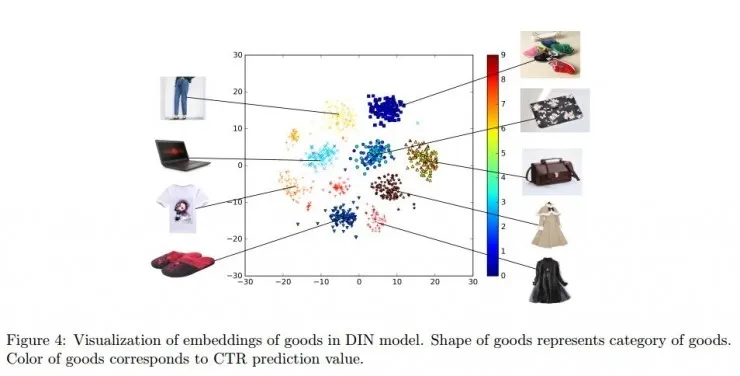
特征空间中的商品向量
如图,论文中随机选取了 9 个类别、各 100 种商品,每类商品用同样形状的点表示。展现在特征空间中的向量很好地展现出了 DIN 网络的聚类属性。另外,图中点的颜色代表了网络预测的用户购买的可能性,红色最高,蓝色最低。
处理过拟合
基础模型和 DIN 模型都遇到了大量参数、稀疏输入时过拟合的问题。所以盖坤团队设计了一个自适应性的正则化方法,它可以对出现频率不同的项目给予不同的惩罚,牺牲了一点训练速度避免了过拟合的出现。论文中对比了多种不同的正则化方法,这个自适应方法的表现还不错。
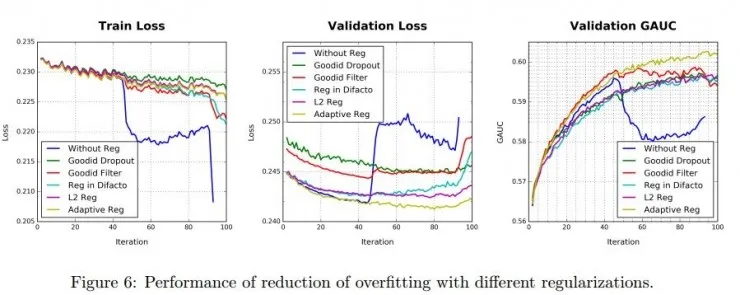
不同正则化方法间效果对比
基于 XDL 平台构建分布式系统
为了实现工业级的大规模稀疏输入、百亿级参数训练,盖坤团队基于 XDL 平台构建了多 GPU 的并行模型、并行数据平台。
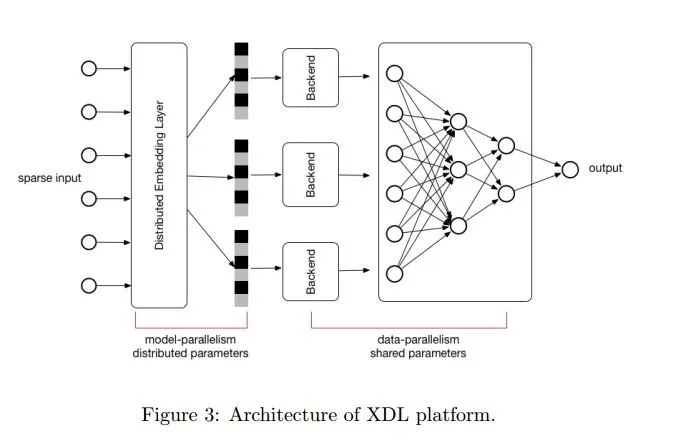
由于 XDL 平台高性能、高灵活性的特点,盖坤团队借助分布式嵌入层(Distributed Embedding Layer)、本地后端(Local Backend)、沟通组件(Communication Component)几个模块构建出的系统训练速度提升了 10 倍,调节参数的效率也提升了不少。
论文就介绍到这里,原文地址 https://arxiv.org/abs/1706.06978 。巧的是,盖坤博士也会亲临今年雷锋网与香港中文大学(深圳)承办的 CCF-GAIR2017 大会现场,并发表主题演讲。想了解盖坤博士最新研究动态的读者们,距离大会开幕只剩两周啦,抓紧购票,不要错过现场感受盖坤博士在内的大牛们学术风采的机会。