
雷锋网 AI 科技评论消息,腾讯的高性能分布式计算平台 Angel 1.0 自去年公开宣布后,今天已经正式开源。发布地址为 https://github.com/Tencent/angel,感兴趣的开发者可以下载或者贡献源码。

用于支持大规模机器学习模型运算
据雷锋网 AI 科技评论了解,腾讯 Angel 1.0 是腾讯数据平台部与香港科技大学合作、北京大学参与共同开发的分布式计算框架,它的主要设计目标是为了支持超大维度的机器学习模型运算。
Angel 的核心设计理念围绕模型。它将高维度的大模型切分到多个参数服务器节点,并通过高效的模型更新接口和运算函数,以及灵活的同步协议,实现机器学习算法的高效运行。
在去年公开消息时,Angel 已经支持了 SGD、ADMM 优化算法,同时提供了一些常用的机器学习模型,现在开源的 Angel 1.0.0 正式版也新增了 Logistic Regression、SVM、KMeans、LDA、MF、GBDT 等机器学习算法的集成。用户可以方便地在最优化算法上层封装自己的模型。
根据腾讯数据平台部总经理、首席数据专家蒋杰的介绍,Angel 还可以支持运行 Caffe、TensorFlow、Torch 等深度学习框架,实现这些框架的多机多卡的应用场景。
Angel 基于 Java 和 Scala 开发,能在社区的 Yarn 上直接调度运行,并基于 PS Service,支持 Spark on Angel,未来将会支持图计算和深度学习框架集成。
根据腾讯大数据部的说法,Angel 自去年以来已经在千万级到亿级的特征纬度条件下运行 SGD 用于实际的生产任务,已经在腾讯视频推荐、广点通等精准推荐业务上实际应用。他们还在扩大腾讯内部的应用范围,未来目标是支持包括腾讯在内多家公司的大规模机器学习任务。
Angel 主要技术特点
- 整体架构
Angel 的整体架构参考了谷歌的 DistBelief,这是一种最初为了深度学习而设计、使用了参数服务器来解决巨大模型在训练时更新问题的架构。参数服务器同样可用于机器学习中非深度学习的模型,如 SGD、ADMM、LBFGS 的优化算法在面临在每轮迭代上亿个参数更新的场景中,需要参数分布式缓存来拓展性能。
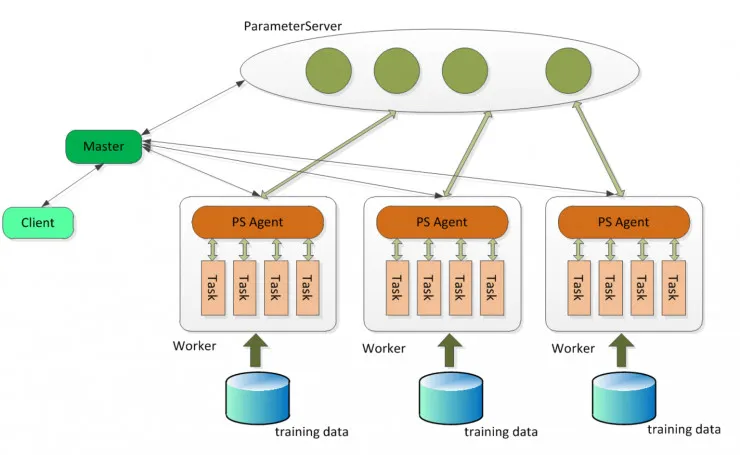
如这个系统框图,Client 作为客户端可以发送启动或停止、加载或存储模型命令,可以获取运行状态;具体的任务分配、协调调度、资源申请由 Master 完成;Parameter Sever 复杂存储和更新参数,一个 Angel 计算任务中可以包含多个 ParameterSever 实例,随着任务启动而生成,随着任务结束而销毁;Work 实例负责具体的模型训练或者结果推理,每个 Worker 可以包含一个或者多个 Task,这样的 Task 可以更方便地共享 Worker 的公共资源。
机器模型运算中需要反复迭代更新参数。Angel 采用的 Parameter Sever 架构相比其它类型的架构更适合解决巨大模型中的参数更新问题;实际运行中相比参数更新方面有单点瓶颈的 Spark 平台,Angel 能够取得成倍的性能优势,而且模型越大优势越明显。
Angel 与 Spark 做了如下比较:在有 5000 万条训练样本的数据集上,采用 SGD 解的逻辑回归模型,使用 10 个工作节点(Worker),针对不同维度的特征逐一进行了每轮迭代时间和整体收敛时间的比较(这里 Angel 使用的是 BSP 模式)。
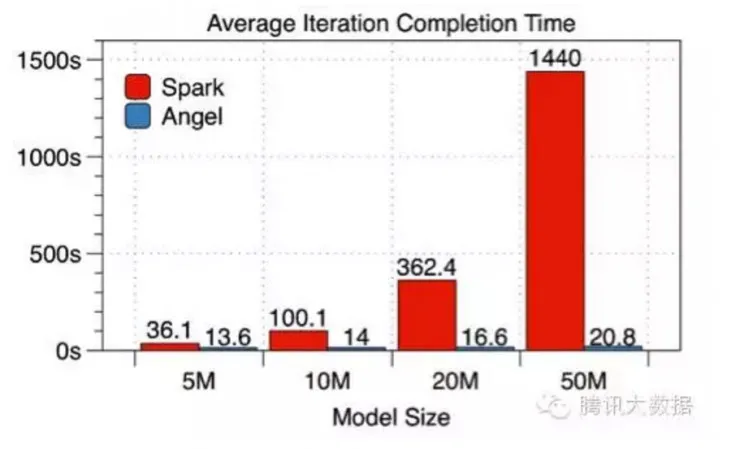
通过数据可见,模型越大 Angel 对比 Spark 的优势就越明显。
- 网络优化
Angel 的网络解决方案使用的是香港科技大学的 Chukonu。借助 Chukonu,Angel 可以通过网络流量再分配的方式,解决半同步的运算协调机制 SSP 中可能出现的快节点等待慢节点的问题,减少了窗口空闲等待时间。
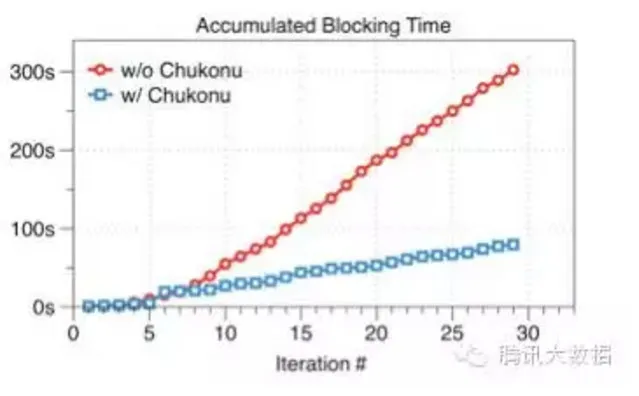
如下图所示,在 1 亿维度、迭代 30 轮的效果评测中,可以看到 Chukonu 使得累积的空闲等待时间大幅度减少,达 3.79 倍。
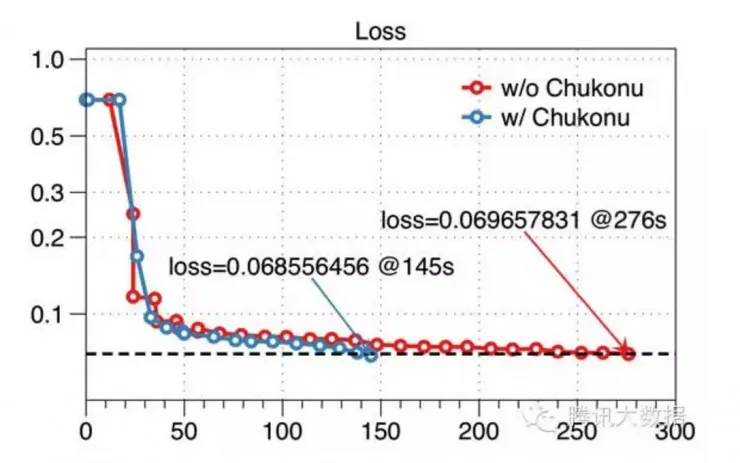
以及,Chukonu 配合参数服务器,可以让慢的节点有更大的可能获得最新的参数,因此对比原始的 SSP 计算模型,算法的收敛性得到了提升。下图所示,同样是针对五千万维度的模型在 SSP 下的效果评测,原生的 Angel 任务在 30 轮迭代后(276 秒)loss 达到了 0.0697,而开启了 Chukonu 后,在第 19 轮迭代(145 秒)就已达到更低的 loss。
快速发展的腾讯计算平台
雷锋网 AI 科技评论了解到,去年 Angel 发布时,腾讯平台部总经理、首席数据专家蒋杰对腾讯计算平台的发展历程做过介绍。2009 到 2011 年的第一代平台主要目标是规模化,形成了 TDW(腾讯分布式数据仓库)这样的架构;2012 到 2014 年第二代平台主要是实时化,把大规模计算搬到平台上,支持了实时性强、规模大的业务需求,但是基于 Spark 的数据训练就遇到了超大维度时出现瓶颈的问题。
这样,腾讯开始建设新的高性能计算框架,要能支持超大规模数据集,能完成十亿级别维度的训练。这就是腾讯的第三台计算平台 Angel。围绕 Angel,腾讯还建立了一个小生态圈,可以支持 Spark 之上的 MLLib,支持上亿的维度的训练;也支持更复杂的图计算模型。
也就是依靠 Angel,腾讯获得了 2016 年的 Sort benchmark 的排序的 4 项冠军,用 98.8 秒时间完成了 100T 数据的排序,刷新了四项世界纪录。2015 年的这项排序时间还高达 329 秒。
腾讯开源的 Angel 给头疼于大规模机器学习模型计算的业内人员提供了一个新选择。发展自己技术、扩大自己的平台的同时,腾讯也承诺未来的开源力度只会越来越大。