
最近,中科院计算所发布了 BDA 大数据分析平台,并开源了全部 API 和一项 Easy Machine Learning 技术。Easy Machine Learning 系统通过交互式图形化界面让机器学习应用开发变得简单快捷,系统集成了数据处理、模型训练、性能评估、结果复用、任务克隆、ETL 等多种功能,此外系统中还提供了丰富的应用案例,可供开发者们下载使用。
随着人工智能发展,机器学习成为越来越多大数据应用的选择,不仅节省人力,准确率也有很大的提升。但是机器学习的使用却并不简单,复杂的算法、繁琐的配置等等问题让技术人员头疼不已,以至于在很多大数据平台上,机器学习的作用并没有被很好的发挥出来。
据官方资料,中科院发布 BDA 平台的 Easy Machine Learning 系统提供了一个通用的数据流系统,可以降低将机器学习算法应用于实际任务的难度。
什么是 Easy Machine Learning 系统?
最通俗的翻译就是:简单机器学习系统。
在该系统中,一个学习任务被构造为一个有向非循环图(DAG/directed acyclic graph),每个节点表征一步操作(即机器学习算法),每一条边表征从一个节点到后一个即节点的数据流。
任务可被人工定义,或根据现有任务/模板进行克隆。在把任务提交到云端之后,每个节点将根据 DAG 自动执行。图形用户界面被实现,从而可使用户以拖拉的方式创建、配置、提交和监督一项任务。
系统包含三个主要组件:
分布式的机器学习库
不仅能实现流行的机器学习算法,也能实现数据预处理/后处理、数据格式转变、特征生成、表现评估等算法。这些算法主要是基于 Spark 实现的。
基于 GUI 的机器学习开发环境系统
能让用户以拖放的方式创造、安装、提交、监控、共享他们的机器学习流程。机器学习库中所有的算法都可在此开发环境系统中获得并安装,它们是构建机器学习任务的主要基础。
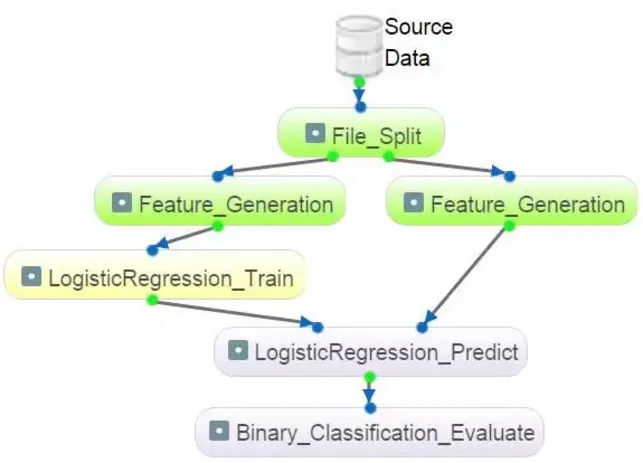
执行任务的云服务
该服务基于开源的 Hadoop 和 Spark 大数据平台建立,在 Docker 上组织了服务器集群。从 GUI 上接受一个 DAG 任务之后,在所有的独立数据源准备好时,每个节点将会自动安排运行。对应节点的算法将会依据实现在 Linux、Spark 或者 Map-Reduce\cite 上自动安排运行。
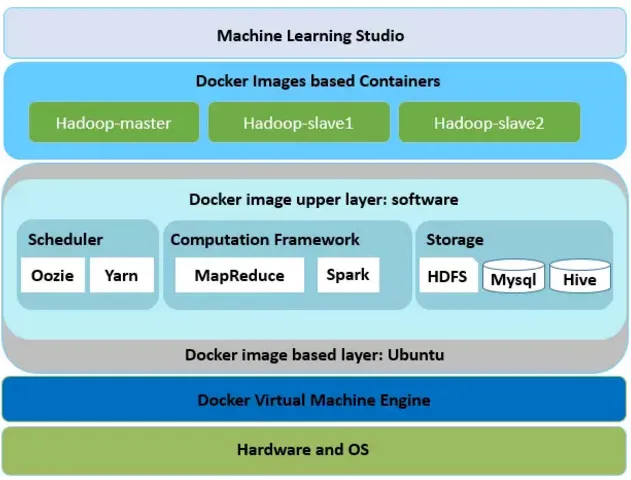
为什么要使用 Easy ML?
总结起来,Easy ML 的优势主要有三点:
降低定义和执行机器学习任务的障碍 ;
共享和重用算法的实现,作业 DAG 和实验结果 ;
将独立算法和分布式算法无缝集成在一个任务中。
从官方资料可以看到,BDA 平台包括两大组件:
一个是分布式大数据分析函数与算法库 BDA Lib,基于 Spark 内存分布式计算框架,具有强大的大数据处理能力。提供丰富的机器学习算法可供选择,涵盖分类聚类、文本分析、个性化推荐等方向;可运作于单机环境,实现数据分布式和模型分布式;提供极简的 API 接口 / 支持命令行运行。
另一个是可视化任务构建与管理平台 BDA Studio,拥有可拖拽式图形化操作界面,可以支持 MapReduce/Spark/ 单机混合执行,具有强大的数据处理能力;集成了丰富的系统分析程序,支持私有数据 / 自定义数据分析算法模块,支持程序模块 / 应用发布与共享,提供大数据分析样例模板。
两大 BDA 平台组件与三大 Easy ML 组件优势互补,可大幅度提升用户对大数据分析的效率和体验。
Easy ML 和 Azure ML
Microsoft 也有一款图形化界面的机器学习产品:Azure ML。
Microsoft 的 Azure ML Studio 提供了一个快速的学习曲线,它不需采取深层数据或编码的方式来启动运行。
Microsoft Azure 机器学习是一种用于执行价值预测 (回归),异常检测,聚类和分类的云服务。Azure 机器学习是微软 Cortana 分析套件产品的一部分,Azure ML Studio 图形化、模块化的方法将让你快速了解机器学习模型。
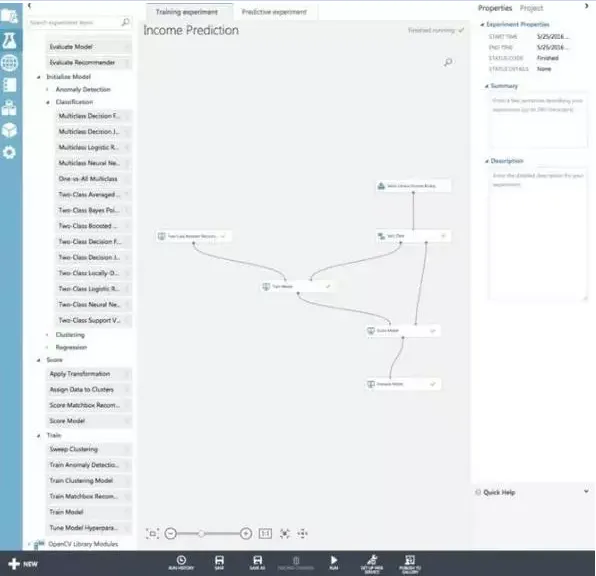
Azure ML Studio
Azure 提供了三个级别的工作空间和四种机器学习工作区,而不同级别的工作空间拥有的功能也均有不同,同时使用的价格也有差异。
不同于商业化的 Azure ML,Easy ML 系统已经完全开源,开发者可以获得全部源代码,并对源代码进行研究和修改。
开源也好,商业也罢,不论是微软的 Azure ML,还是国产的 Easy ML,共同目的都是为了让开发者能够更好地理解机器学习,更加轻松的进行开发,其实对于大部分的开发者来说:适合自己的,就是最好的。
如何使用 Easy ML?
安装
在使用之前,用户需要对自己计算机的环境变量进行配置。配置教程地址如下:
https://github.com/ICT-BDA/EasyML/blob/master/QuickStart.md
使用
根据官方 GitHub 的 README 文档,在运行 Easy ML 之后,可以使用官方账号 [email protected]、密码进行 bdaict 登录使用,地址如下:
http://localhost:18080/EMLStudio.html(建议使用 Chrome 浏览器)
登陆成功后,可以看到正常运行界面如下:
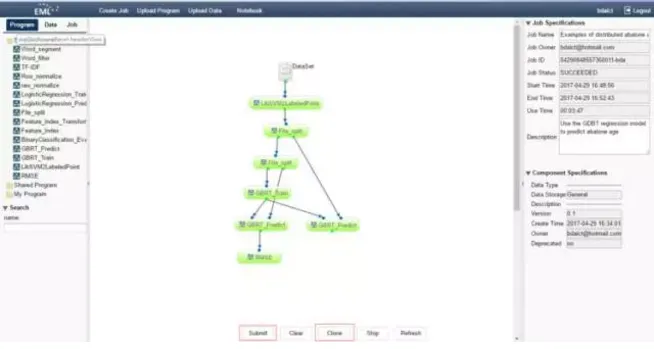
用户可以根据左边菜单的选择算法和数据集创建一个机器学习任务(一个数据流 DAG)。用户可以点击选择在 Program 和 Data 菜单项下面的算法和数据集,同样也可以点击 Job 菜单项选择现存的任务,并复制和做一些必要的修改。用户同样可以在右边的菜单修改任务信息和每一个结点的参数值。任务中的结点可以对应于单机 Linux 程序或在 Spark、Hadoop Map-Reduce 上运行的分布式程序。
更详细的使用教程请访问:
https://github.com/ICT-BDA/EasyML
参考资料:
论文:
http://www.bigdatalab.ac.cn/~junxu/publications/CIKM2016_BDADemo.pdf
GitHub: