

“还有 30 秒。”汤姆·克鲁斯扮演的未来警察跳下直升机后,耳边响起同事的最后一次提醒。
此刻,一位男子在卧室里拿起床头的剪刀,面前是他出轨的妻子。在他来得及做任何事之前,一众警察冲进屋子,将他按住。
“看着我,看着我”汤姆·克鲁斯用虹膜识别设备扫描了男子的眼睛,“就是你了,霍华德·马克思。我要以‘即将谋杀罪’逮捕你,你本来要在 4 月 22 日,也就是今天 8 点 04 分谋杀你的妻子。”
“但我什么都没做!”男子辩解道,但警方已经铐上他的手腕。城市里的城市谋杀案数量依然保持为零。
这是斯皮尔伯格 2002 年的科幻电影《少数派报告》,片中的警察可以预测犯罪细节,提前赶到现场,制止犯罪。
今天还没有人能精确预测未发生罪案的细节。但预测哪里会发生罪案、谁更有可能犯罪是已经被用在执法、乃至定罪上。
人工智能已经在决定数十个城市的警察去哪儿巡逻、找谁“聊天”
意大利的 KeyCrime 是一家软件预测公司。他们目前主要服务米兰警方,针对商店的抢劫和偷窃做地区预测,目前这套系统已经用了 9 年了。
创始人 Mario Venturi 告诉《好奇心日报》,他们的逻辑是已经有很多的经验和数据支持:犯罪者有他们行动的一套范式——如果他们在某一地区进行了抢劫犯罪并且得手了,他们更倾向于在该地点附近的再次作案。
今年 3 月,米兰的警察通过 KeyCrime 的指引做到了“预防犯罪”——在一个超市门口,在两个罪犯正准备抢劫超市,警察抓住了他们。

KeyCrime 调用的是警方的犯罪嫌疑人的数据,配合被抢劫的商店地点、摄像头里拍摄的犯罪嫌疑人的动作,携带的武器,来分析这个罪犯的危险程度,更重要的是,分析他跟附近犯罪案件有没有什么别的关系,如果有——他下一宗犯罪可能会在什么时间和区域。
最近几年,有了大量的数据和神经网络学习算法之后,KeyCrime 在不同罪案中建立联系变得方便起来。
像 KeyCrime 这样的犯罪预测软件已经有很多家警局在使用。
今年 5 月,芝加哥警局局长 Jonathan Lewin 开了一个人工智能的沟通会:警局在城市里安装了可以检测枪声的声音感应器收集数据,加上城市路边的摄像头数据,通过机器学习算法做了一个“罪案预测系统”,能预测抢劫、枪击案的罪案地点,还能预测什么人可能会犯罪,让警方可以提前找嫌疑人聊聊天。
现在芝加哥警员巡逻时,会在手机和平板上用这么一个应用:地图上显示着一个个红色的小方块,那里就是下一次犯罪可能发生的地方。
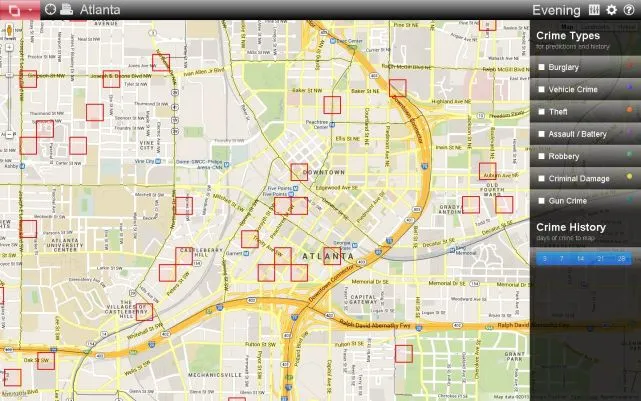
不同犯罪行为的热点图,来自 PredPol 公司的软件
警方使用技术分析和预测犯罪地点,已经有很多年了,而原因也很好理解:效率。
著名犯罪学家 Lawrence W. Sherman 曾总结过“减少犯罪的八个原则”:
1. 更多的警员数量;
2. 更快的 911 反馈;
3. 从接报到出警响应时间更短;
4. 更多随机巡逻;
5. 更多对于犯罪热点地区有目的巡逻;
6. 更多逮捕;
7. 更多和有犯罪前科的嫌疑人交流;
8. 更多和社区沟通;
这些原则当中有不少都是跟怎么调派警力到某一位置相关。现实当中,地方警局的人手和工作时间都是有限的。而算法和机器学习在这当中的作用,就是帮警局提升效率。如果一个警员每天只有 8 小时的巡逻时间,到处乱走看看有没有撞见罪犯,并不是一个很高效的行为模式。
洛杉矶警局的警长 Charlie Beck 说法也是类似,“我要不来跟更多的经费,也要不来更多的人手。我只能把我有的资源用得更好,如果巡警能对这种技术改变看法,那么管理者也会这么做。” 洛杉矶表示,使用这套提高效率的模型,一年光一个分局就能省下 200 万美元。

背后有不少技术公司在帮忙。刚刚我们谈了那么多洛杉矶和芝加哥警局使用的预测犯罪的软件,背后就是加州圣克鲁兹的警力软件公司 PredPol。
芝加哥警局表示,用了 PredPol 的算法短短几个月后,枪击案件等发生几率已经下降了 13%,预计谋杀案件的数量将降低 49%。
芝加哥其实在 2009 年开始就在犯罪分析系统 PredPol,而被证实有效的 KeyCrime 也已经在米兰警局使用了 9 年。
只是最近几年,在有了更多数据之后,警方开发重心,从分析到预测“地点”,再从预测地点升级到预测“嫌疑人”上。
去年很受争议的就是芝加哥警局的“预测罪犯热点名单”,他们会告诉警员,附近街区最有可能犯罪的前 20 名嫌疑犯名字和照片,具体到这样的程度:“此人可能在 18 个月内有 25% 的可能性参与暴力事件。”
根据芝加哥警局透露的信息,这个名单已经有 400 人。上榜的人不一定有犯罪史:住在罪案高发地地区,或者朋友、家人有人犯罪……都是这个名单背后算法考虑的因素。
警方还会提前给这些算法挑选出来的“未来罪犯”提前做心理建设。Jonathan Lewin 把这套提前干预犯罪的机制叫做“定制化提醒”,提前去找嫌疑人聊天:
“我们注意到你了,我们想把你从犯罪圈里解脱出来,这些是我们准备的社会服务项目。”而所谓的“社会服务项目”,可能是从清理社区、志愿者活动到职业培训,到底是要嫌疑人自己去做还是全家都要换地方,也没有说清楚。
如果这位嫌疑人不同意继续要留在算法设定的高犯罪地区,警方就会发出警告,“如果你在此区域犯罪,你可能会被处以更严重的惩罚。”
怎么定罪,人工智能也会参与其中
2013 年,艾瑞克·卢米斯因为偷车被美国威斯康辛州的法院判处了 6 年的有期徒刑。
他偷来的车曾经参与过一场枪击案,车尾箱里还有枪。警方原本以为是人赃并获,结果查清楚是误判,卢米斯其实并没有参加持枪犯罪,只是刚好偷了一辆有过犯罪记录的车。如果只是犯了偷车,根据威斯康辛州的法律,刑期最多是入狱三年,然后还有三年是出狱监视。
但法院还是给卢米斯判了更重的刑罚。法庭的量刑参考的是一套名为 COMPAS 的人工智能算法。这个十分制的“打分”机制被美国司法部用于判断有过犯罪纪录的人未来犯罪的几率。
卢米斯在偷车之前,曾经因为性犯罪入狱。上次入狱的时候,COMPAS 算法当时给他打了一个高分。这次,这个分数被威斯康辛州法院当作参考数值了。
卢米斯提起上诉,要求公开算法是对他评分的机制,他认为评分细则里有性别等参考因素。
这个要求遭到了法院的拒绝:他们认为给罪犯做打分分析是自从 1923 年就开始有的事情,而且这个算法是开发方 Northpointe 公司的知识产权,所以不能公开。而对于卢米斯的考量除了算法还有别的机制,所以是公平公正的,就在今年 5 月 23 日,法庭驳回了上诉,维持原判。
如果在美国犯罪进了监狱,COMPAS 这个人工智能算法很可能就会接管你的个人数据。入狱者填写一份个人情况调查问卷,综合犯罪的严重程度,COMPAS 会计算出一套“未来罪犯”的评分机制。为避免歧视,这份问卷里并没有问种族、收入等敏感的维度,但会有这么一些类似问题:
你在什么地方居住?
你的教育程度?
你中学之前有坐过飞机旅行吗?
你的亲人、朋友有人曾经参与犯罪吗?
去年,非盈利调查机构 ProPublica 从警方处拿到 1.8 万 COMPAS 评分数据,然后做了一份调查报告,追踪这些人在两年来的再犯罪的记录。

最后出来的结果是:
穷人更容易犯罪;
教育程度低的人更容易犯罪;
黑人更容易再犯罪;
男性更容易犯罪。
从统计数字看,这些可能都是事实。但这样的数据被反过来用在判断一个个体未来犯罪的可能性,并就此量刑的时候,就有问题了。
这和前段时间被开除的那位美团点评人事在招聘信息里写的“不要黄泛区及东北人士”没什么本质区别。
在美国,COMPAS 是从 2000 年初就开始在全国的司法机构使用,这个算法已经修改到第四版。在各个州法官量刑或者警察盘查疑犯的时候,会把 COMPAS 分数作为参考。
2014 年,时任司法部长 Eric Holder 公开表示,美国法庭依赖算法来判定罪行,预测再犯罪是有风险的。Holder 表示,美国的法官量刑过于依赖这套评分算法。
看起来公平的算法,背后依然受设计者的偏见影响
有一个关于科研的比喻,说科学家在研究新东西的时候容易过度分析自己已经有的信息,强行从中获得结论,进而忽视了未知因素的影响。
一个人在室外停车场丢了钥匙,他首先会去看路灯照耀下的路面。
这不是因为钥匙更可能丢在路灯下,而是因为这里比较容易找。
人工智能算法判断一个人的犯罪可能也差不多。
MIT 教授 Ethem Alpaydin 曾经这么解释现在最新的机器学习的原理:
以前你需要知道特定的数据要来实现什么,于是雇佣一个程序员来编写程序。机器学习就是,现在计算机自己学会处理和识别这些数据,程序也是自己写的,然后导出你所需要的结果。
要做一个判定谁是罪犯的系统。首先,是这个机器学习算法的设计者在判断“什么样的人更容易犯罪?”然后再把不同原因分解开来,去搜集数据。
一个人犯罪的可能性有千千万万,而算法设计者输入进去的维度,就好像路灯下的路面。计算机强行在设计者觉得重要的维度里判断一个人犯罪的可能性。
更糟糕的是,今天的机器学习算法基本是黑盒子——输入了数据,等待输出结果。但当中机器是怎么识别的,即使是算法的设计者,也不能肯定。
上个月,上海交大教授武筱林和博士生张熙的论文引来争议。他们的论文《基于面部图像的自动犯罪性概率推断》用机器学习算法和图像识别技术扫描了 1856 张中国成年男子的身份证照片,让算法来判断这个人是不是罪犯,称成功率达到了 90%。
武筱林和张熙还总结了这些罪犯的面相特点:内眼角间距比普通人短 5.6%,罪犯的上唇曲率不一样,罪犯的鼻唇比非罪犯角度小 19.6%,罪犯跟普通人相比,面部特征来的更明显。
这篇文章在发布之初就惹来了一些种族歧视的争议。5 月初,Google 和普林斯顿大学的三位研究人员写了一篇反驳文章,名为《相面学的新衣》。他们在文章中认为武筱林的研究方法跟 150 年前的意大利的“医学相面术”类似,只是使用了机器学习算法:
“1870 年意大利医生龙勃罗梭(Lombroso) 打开了意大利罪犯维莱拉尸体的头颅,发现其头颅枕骨部位有一个明显的凹陷处,它的位置如同低等动物一样。这一发现触发了他的灵感,他由此提出‘天生犯罪人’理论,认为犯罪人在体格方面异于非犯罪人,可以通过卡钳等仪器测量发现。龙勃罗梭并认为犯罪人是一种返祖现象,具有许多低级原始人的特性,可被遗传。”

来自 Google 的研究者 Blaise Aguera y Arcas 解释,神经网络算法“判断”图片的方式跟人不太一样:给数百万个学习参数加不同的权重。比如让算法判断一张图片是来自什么年代,机器学习很可能学到了发现各种细微线索,从比较低层次的“胶片颗粒和色域”到衣服和发型,乃至车型和字体。
所以机器学习到底从这 1000 多张身份证照片中学到的规律是什么?
不一定是罪犯的面部都有什么独特的特征,可能是图片的颗粒度,也可能是其他一些共同特点——例如衬衫。例如,武筱林论文中的 3 个“非罪犯”图像中都穿着白领衬衫,而另外 3 名被判别为“罪犯”的都没有。当然,只有 3 个例子,Blaise Aguera y Arcas 写到,“我们不知道这是否代表整个数据集。”
而在我们都不知道机器学习的做判断的方式时,作为算法的设计者,我们人类给出的“假设”,以及我们给出的数据,可能决定了算法的走向。
《相面学的新衣》的第三作者,普林斯顿大学法学系教授 Alexander T. Todorov 告诉《好奇心日报》,“有些人认我们的文章是在攻击武筱林,但并不是有意如此。我们想做的是展示这个结果并不如他们展现的那样‘客观’,武筱林进行的假设是未经检验的。”
这事情在 1980 年代也发生过——对,今天每个科技公司都在炒的机器学习那时候就有了。
当时,美国军方想要设计一套算法,想让计算机自动从照片里分辨美苏两国的坦克。
经过一段时间训练他们的算法,识别准确率已经很不错了。
但后来工程师们发现,这不是因为计算机真的认出了两国坦克的设计不同。
事实上计算机认为像素更高的图片等同于“美国坦克”。
这是因为那会儿还在冷战中,输入资料库的照片里,俄罗斯坦克的照片更模糊。
“新技术有为善和作恶的潜在力量。如果你的假设没有被仔细考证,那么机器学习技术只会带来更多的不公平和加速现有的不平等。” Todorov 用这句话结束了我们的采访。
而如果你觉得这件事只是美国警方的才会有的问题。那么也可以看看彭博社早前的一篇报道。
政府直接管理的技术公司“中国电子科技集团”也正在开发软件,整理公民的行为数据,包括工作,兴趣,消费习惯等等,以便在恐怖袭击之前就预测罪犯的行为。军事总承包商总工程师吴曼青说:“在恐怖行为之后的检查很重要, 但更重要的是预测。”
这篇报道对于这个新系统的信息非常含糊。具体会从什么地方收集数据,算法是谁来编写,是否已经上线,其实很难被公众所知。
算法和人工智能技术,只是目前这些人类社会的司法机构问题的一个数字化的版本而已。尽管提高了效率,但它可能更能免除普通执法者对于地区、人群、种族的偏见的责任:因为这是一个客观机器学习算法的选择。
预测犯罪的算法也会影响到日常生活
“你雇用的人,真的可以信任吗?”
今年 5 月,在加州桑尼维尔一个金融科技(FinTech)创业分享会上,侯赛因·何塞从这个问题开始,介绍起自己的公司 Onfido。
侯赛因·何塞在现场用图片演示,可以用算法来帮企业确定雇佣的人是否“靠谱”。
使用方法和滴滴司机上传拿着身份证的照片的过程有点类似,让人拿着证件拍一张照片。
之后 Onfido 会扫描雇员照片,做人脸识别、背景调查,几十秒之内可以确认这个人是不是他声称的人、有没有犯罪前科、是不是非法移民。

Onfido 最开始也是做 Uber 的生意,但自从去年开始 Uber 增长放缓,侯赛因就开始让公司转型,从识别共享经济的顾客有没有犯罪记录,变成了给银行做贷款人的背景调查。“其实我们更像是 RegTech 公司(政策科技公司)了,因为数据要跟政府有一定合作。”
Onfido 去年一下拿了接近 3000 万美元,最新投资者有红杉、Saleforce。他们的竞争对手 Checkr 的投资者来头更大,Google Venture、YC、Accel……去年已经拿了 5000 万美元了。
Onfido 的网站上,识别之后数据会用在什么地方并没有清楚的解释。雇主获得信息之后怎么办也不在它关心的范围内。
我在现场问了侯赛因数据隐私保护以及怎么获取第一笔数据,他的回答却很含糊:跟银行、政府等本身拥有大量数据等机构合作是最快的训练算法的方式,他们也想要让那些普通人更快通过审核,获得他们想要的贷款和工作机会。
更多的,他怎么也不愿意说了。
这样的谨慎态度能在许多销售犯罪分析相关产品的公司身上看到。
给罪犯打分的 COMPAS 算法背后的 Northpointe 公司在被《纽约时报》、ProPublica 等多个媒体报道后,改了新品牌 Equivant 重新卖服务。
今年 5 月,在美国加州山景城举行了一场名为 SVOD 的创投大会。
刚离职没多久的人工智能专家,前百度人工智能实验室负责人的吴恩达在台上说:“人工智能就是 21 世纪的电力设施,抓住这个新技术的公司,将会在下一轮的竞争中跑得更快。”
一个一个初创公司走上台,介绍自己的项目。当中有给企业做脸部识别方案的、做语音识别系统的。台下投资人们抛出一个又一个问题。
“你们识别率有多准?”
“你们考虑怎么退出?”
……
公平和隐私,可能并不一定在他们的考虑范围。在台上的创业公司展示结束后,一个专门给儿童做人工智能助手的创业者 Ivan Crewkov 跟我聊起人工智能的未来,我问如果机器学习算法一个从小就知道小孩是谁,优点缺点是什么,不会觉得担心吗?
他说,“我是个乐天派,即使有更多监管,我想商业上一定会向前走的。”
大会结束后,吴恩达对《好奇心日报》谈到了自己的对于监管人工智能的态度,这也是业内的典型态度:“我觉得现在太早了。技术还没完全发展起来,太多设限会阻碍发展。”