

本文为 Salesforce 知名数据科学家、机器学习工程师 Anmol Rajpurohit 对开发者的建议。对算法进行并行处理,是业内常见的加速方式,但不少开发者对它的认识存在误区。因此,Anmol Rajpurohit 用本文向大家说明,到底什么时候才应该并行执行代码、以及它的前提是什么。

Anmol Rajpurohit
Anmol Rajpurohit :当一件任务能被分割为多个独立处理(不必进行信息沟通与资源共享)的子任务,并行执行会是一个绝佳选择。
即便这样,效率,即如何高效地执行,仍是一个关键问题。这关乎能否真正实现并行化理论上的优点。
实际情况中,绝大多数代码都有需要串行执行的部分。可并行的子任务,也需要某种形式的数据传输同步。因此,相比串行而言,预测并行化到底能否让算法运行地更快是一件十分困难的事。
相比按序处理任务所需要的计算周期,并行执行总是有额外代价——起码包含把任务分割为子任务,以及把它们的结果整合起来。并行计算相比串行的性能,在很大程度上是由一个因素决定的:上述额外步骤耗费的时间,与并行执行节省的时间这两者之间的差。
值得注意的是,并行化的带来的额外步骤并不局限于代码运行之时,还包括编写并行计算代码所需的额外时间,以及修复漏洞(并行 vs. 串行)。
有一项评估并行化表现的理论方法广为人知——Amdahl’s law。它用下面的公式来度量并行执行子任务带来的加速(多处理器) vs. 串行运行(单个处理器):
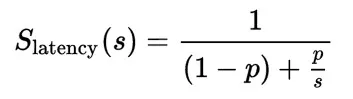
Slatency 是执行整个任务的理论加速;
s 是任务里受益于额外系统资源那部分的加速;
p 是受益于额外系统资源那部分所占的执行时间的比例。
为认识到 Amdahl’s Law 的意义,请看下面的图表。它展示了不同处理器核心数对应的理论加速。当然,这是基于所执行的任务所能达到的不同并行化程度。
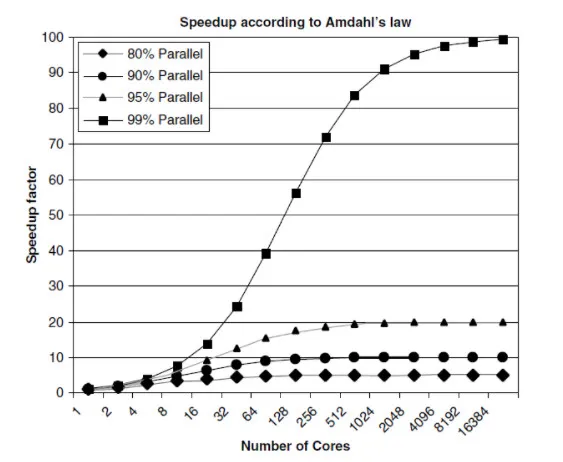
有一件事雷锋网需要提醒诸位:并不是所有代码都能被高效地并行。能在多处理器核心上实现理论上的加速水平,这样的代码可谓是凤毛麟角。这是由于串行部分、内部信息交换成本等天然限制。通常,大型数据集才是并行执行的理想情形。但开发者不应该摄像并行化能带来性能提升,而应该在搞并行化之前,先在任务的子集上对并行和串行谁优谁劣做一个比较。
via kdnuggets