
随着 Facebook 2017 年开发者大会 F8 的召开,Caffe2 框架开源,机器学习和深度学习开发社区再一次迎来兴奋时刻。在 F8 大会上,Facebook AML 实验室的 Andrew Tullock 和贾扬清上台介绍了 Caffe2 轻巧、易用和可扩展的特性。二人还强调了“unix 哲学”(即 unframework)的设计理念。
就像贾扬清在知乎上所说的:“framework 不重要,重要的是技术,这也是我一直主张把核心软件比如说 Gloo,NNPAXK,FAISS 这些单独放出来,不放在框架里面的原因--每个框架都可以拿这些软件来优化,这才是做 community 的道理。” 以下为 Andrew Tullock 和贾扬清演讲视频,另附文字版,由雷锋网编译。
视频地址:http://static.video.qq.com/TPout.swf?auto=1&vid=u0395bzan2k
Andrew Tullock:Caffe2 在移动端的开发和应用
大家好,我的名字是 Andrew Tullock,来自 Facebook AML 实验室,与我一起演讲的还有我的同事贾扬清。我主要讲一下如何将机器学习和深度学习模型装载到移动端上运行,包括 Caffe2 涉及到的一些开源的算法、软件和工具。扬清会谈一谈这些技术如何在移动端之外的设备上扩展。
这里是一个实时神经风格迁移的例子,已经在本周很多 Keynote 场合提到了。

一年半之前,当风格迁移的技术刚开始应用的时候,在大型 GPU 集群上处理一帧的图像,都要花费好几分钟的时间。经过我们和其他同仁在算法和软件上的改进,这项技术如今变成了可以“实时进行”,并且是在你的手机上实现实时风格转换,这比几个月之前进步了好几个数量级。
我们有一个图像数据库,里面有一些风格化的图像,比如莫奈或毕加索的画,拿来训练 CNN。训练目标是,输出的图片风格转变,但是图片内容不变,模型训练完成后,输入其它图像,就会发生风格相似的转变。一开始我们是在 Facebook 的数据中心的 GPU 上做离线的模型训练,后来就转移到手机上运行,这其中就涉及到 iOS 和 Android 系统上高度优化且开源的 Caffe2 框架。
为什么 Facebook 一定要在移动端建造深度学习?
Facebook 有数百万的移动端用户,但是现在大部分机器学习任务都只能在云上进行。但是,在移动端进行机器学习任务有以下好处:保护隐私,因为数据不会离开你的移动端;避免网络延迟和带宽问题;提升用户体验,比如优化 feed ranking 功能。所以我们开始着手,从底层建造一个专门为移动端优化的机器学习框架。
建造的过程中,有几个关键之处。首先一个关键,就是我们遵循“unix 哲学”,先建立轻巧的框架核心,之后再尽量完善整个生态。这个框架核心具有很强的扩展性,可以在小型的移动设备和大型 GPU 集群的服务器上运行机器学习和深度学习模型。
另一个关键之处,是性能。尤其是在运算能力不强的设备上,性能成为瓶颈,这就需要进行一些特殊的设计来改善。首先,在目标平台上使用最高效的底层函数库(primitive),这里面会涉及到在 GPU 上运行的 cuDNN、在英特尔 CPU 上运行的 MKL DNN 等等。
第三个关键之处,就是优化这个框架核心所占用空间(footprint)。这个涉及到代码尺寸(code size)以及模型尺寸,将代码尺寸最小化是围绕着极简框架核心(minimal core)展开的,极简框架核心是一个可以加入插件的架构。而缩小模型尺寸,涉及到便捷地使用最新模型压缩技术。
针对 CPU 的优化
Facebook 希望在多种类型的设备上快速运行机器学习和深度学习模型,但是并没有一个通用的模型尺寸适用于所有的设备的后端。我们基线单元(baseline unit)就是现今大部分手机使用的 ARM CPU,对于一些新型设备,我们也为 GPU 甚至是 DSP 做特定优化。ARM CPU 是目前手机上比较常见的进行浮点运算的芯片,其中的一个关键点,就是使用 SIMD 单元,所以我们写了一套定制的 NEON Kernel,这些已经在开源的 Caffe2go 项目里面了,这比现存其它的 NEON Kernel 性能有了大幅提升。
对于卷积而言,我们的一个团队成员和一位实习生,开发了 NNPack 库,包含了一系列先进的卷积算法(比如针对 3x3 的卷积的 Winograd's minimal filtering 算法),并且提供了大幅提升性能的工具。我们以上的这些工作,确实换来了性能的大幅提升,尤其是对于图像映射任务中的大型卷积的效果很好。

针对 GPU 的优化
再次强调,后端需要足够小的框架核心,因为我们想把它放到任何地方。我们做到了大约只需要几百 KB,就可以装载这个框架核心。针对高端的最新 iPhone,我们的机器学习和深度学习系统对于 GPU 的数据并行性是非常友好的。所以我们写了一套定制的 Metal Kernel,也使用了苹果的 Metal Shader 库,为 Caffe2 打造一个定制的 GPU 后端。这带来一系列好处,其中一个就是速度提升,比完全改造之前的速度提升了十倍;相比于已经优化过的 CPU 库,针对不同的问题,可以提升2-5 倍速度。同时能耗也有了本质提升,所以我们可以进行更多的计算。

Android 系统上的 GPU 也类似,我们与高通合作开发了“骁龙神经处理引擎”(SNPE),如今高通骁龙 SoC 芯片为大量的手机服务,现在是 Caffe2 的首要概念( first class concept),我们可以利用这些 CPU 和 DSP,从本质上提升能效和性能。

下图是一个性能提升的例子。
当我们将模型装载到数十亿移动客户端上时,最小化 overhead 就变得尤为重要。你可以把这些模型看做是数百万、数千万的浮点数字集合,我们使用模型压缩技巧,在保持原有质量的同时缩小模型尺寸。我们的工具,来自韩松(Song Han)在 2016 年 ICLR 的一篇论文,他曾经也是我们团队的一名实习生。压缩的过程分好几步,首先我们对这些模型进行剪枝(pruning),丢掉一些不那么重要权重。当我们进行剪枝的时候,我们可以应用一些标准的量化技巧。你可以把这个过程想象成,在数十万的浮点数字中应用了一个标准的聚类算法技巧,
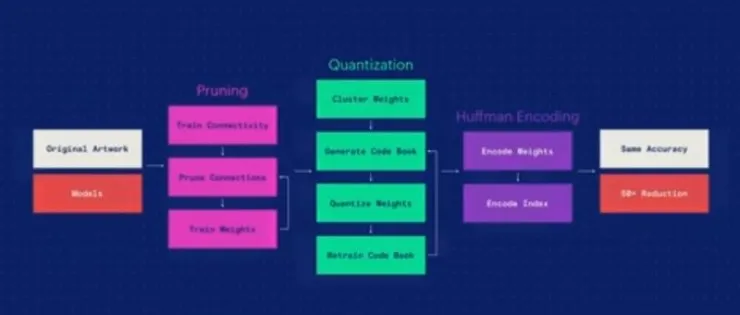
我们可以把每个 32 位的浮点数字都压缩到几个比特,代表其成本指数( cost index)。所以,这个过程大幅缩小了模型尺寸,之后可以经过重新训练,来弥补任何的量化损失,把精确度恢复过来。这当中,我们得到了一套码本(code book),代表了每一个权重的聚类分配。然后,我们可以应用标准通用的压缩算法,我们找到了一个最好用的“ZSTD 算法”,能够提供异常高水平的压缩性能。
综合以上工具,我们可以让机器学习模型在压缩5-50 倍的情况下,保持同样的精度。下面,让我的同事贾扬清给大家讲讲,这个系统如何应用到更广阔的机器学习生态里。
贾扬清:Caffe2 扩展到其它设备中
我们想要做的,是建造通用的机器学习和深度学习库,既可以扩展到数千种的云端设备中,也可以缩小至你手掌大小的移动设备里。
作为通用系统的 Caffe2
机器学习模型可以在很多设备上运行,包括手机、服务器、云端、Raspberry Pi 等,它也可以适用于工业级应用,比如自动驾驶。所有的这些应用场景特点不一,需求也不一样,开发出一套系统来适应这些不同的需求,是非常具有挑战性的。
Andrew 在前面提到了“unix 哲学”,这就是我们一直遵守的原则。我们打造非常轻巧便携的框架核心,可以适用于各种移动端平台。这个核心用来管理各种底层函数库,也就是一个机器学习系统涉及的各个方面(包括卷积、池化等等)。然后,我们根据不同的运行环境插入不同的组件,来运行这些底层函数库。在服务器端,我们使用 Gloo 来进行大规模的训练,在移动端用 NNPack 库,在其它设备上使用 Metal,等等。
Caffe2 的易用性
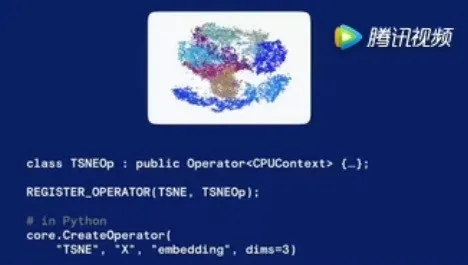
当然,我们意识到,光靠 Facebook 的力量,不可能将这个系统放到所有的设备中。所以我们要打造的平台系统,非常注重开发的易用性,来便捷地运行不同特色的代码。这里有一个例子,机器学习领域有一个应用叫做 TSNE(高维数据可视化工具)的工具,在 Caffe2 里使用这个非常简单,代码如下,体现出 Caffe2 的弹性和可定制化。
健康生态需要合作伙伴共同开发
以上我们提到的功能,已经应用到了 Facebook 的很多产品里,例如计算机视觉、机器翻译、语音识别和预测。如今移动设备、PC 机、可穿戴设备、云端等构成了大型生态,所以非常重要的一点是,整个行业伙伴合作起来构建一个联盟,创造健康的生态来持续推进深度学习的发展。
在这里,我们非常高兴地向大家展示一个产业线合作的成功案例。我想,大家应该都知道 GPU 对如今的机器学习发展很重要,我们与 Nvidia 进行多方位的合作,比如我们将 cuDNN 库整合进我们的系统中,打造成了可能是迄今为止最快的一个计算机视觉系统,可以将数百万的图像在几分钟内处理完。
另外一个例子,就是与英特尔合作。当进入部署的环节,将一个深度学习系统放到云端,非常重要的一点就是,有高性能的 CPU 库。其中有一系列的工作称为 MLP(多层感知),对于预测工作非常重要,我们与英特尔合作开发了一个 MKL DNN 库,整合进 Caffe2 当中。
前面我们谈到,在移动端与高通骁龙合作了 SNPE 库,可以运行机器学习模型,尤其是 CNN,往往能在非常优秀的能耗表现下,保持快 5 倍的速度。使用者不用担心具体的硬件,快速上手使用 GPU 和 DSP 等新型硬件。当然,如今离开云什么也干不了,或许你在用 PC 机运行机器学习模型的时候,会感到很困难,所以我们也与亚马逊及微软合作,将这些深度学习库部署在云上。你可以使用一个云端实例,从而集中于手头的研究和产品工作,而不需要越过重重关卡自己去编制一个库。
Caffe2 已经在 Facebook 内部进行了很多严格测试,现在能够跟各位合作伙伴一起共同推进 Caffe2 在深度学习里的应用,我们感到很激动,也很荣幸。以上谈到的工具和库都已经放到网上了,我们将会持续致力于社区的工作,让 AI 提升人们的生活水平,拉近人们之间的关系,创造一个更友善的世界。
注:恒亮和黄鑫对本文亦有贡献。