

该讲座主题为 Facebook 机器翻译的两代架构以及技术挑战。
雷锋网消息:在昨日的 F8 会场,该讲座吸引了众多开发者到场,主讲者是 Facebook 语言翻译部门技术负责人 Necip Fazil Ayan。
Necip Fazil Ayan 首先介绍了 Facebook 翻译业务的使命和愿景,以及对机器翻译的应用。
使命与愿景
Necip Fazil Ayan:Facebook 希望推动建立一个真正的全球社区,即“连接世界”:每个人都能与全世界任意国家的人、任意语言内容自如交互。翻译,便是其中最关键的一环。

使命:通过打破语言障碍,让世界更开放、更紧密联结。
愿景:每一名用户都能用其语言无障碍的使用 Facebook。
Facebook 是怎么应用机器翻译的
有两种途径。
“See translation”:当 Facebook 系统判断用户无法理解某个帖子时,便提供“翻译”选项。
系统判断的依据很简单:对贴子的语言识别和对用户的语言预测。
“Auto translation”: 当系统判断翻译质量很高时,会自动显示翻译结果,而不是原始语言。 这背后,是 Facebook 对平台上的每一条翻译都计算 confidence score(置信度),并据此预估翻译质量。这靠另一个单独的机器学习模型来实现。
Facebook 机器翻译的两代架构
目前,Facebook 绝大部分的翻译系统,仍是基于 phrase-based machine translation 架构,即“基于短语的机器翻译”。
在过去的十到十五年中,该架构被行业广泛采用。但在最近的几年,Facebook 正转向 neural net machine translation 架构,即神经网络机器翻译。据雷锋网了解,去年 6 月,Facebook 部署了第一个基于神经机器翻译的产品——德译英;拉开了从“基于短语”切换到神经机器翻译的大幕。至今,已有 15 个不同语言的翻译系统,迁移到了新的机器翻译架构;Facebook 平台上,超过 50% 的翻译出自基于神经网络的系统。
那么,为什么 Facebook 要转移至神经网络机器翻译?或者说,新架构的优点是什么?
首先,Necip Fazil Ayan 表示,神经机器翻译为 Facebook 带来翻译质量的大幅提升:
精确度(是否清楚表达了原句的意思)提升 20%,通顺程度(翻译语句听起来是否正常)提升 24%。
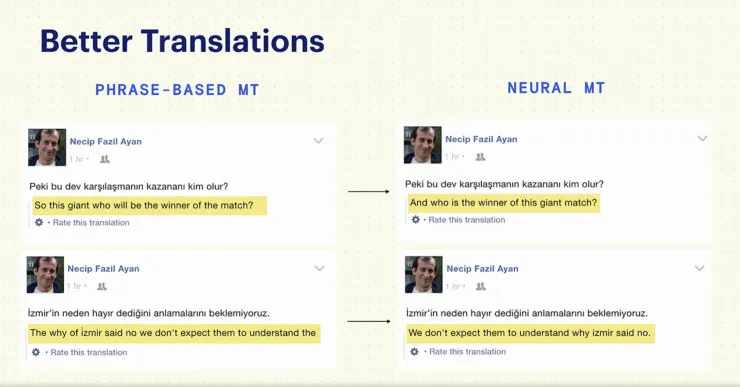
这是两代架构的翻译结果对比(土耳其语到英语)
左边是基于短语的机器翻译,大多数词语的意思是对的,但顺序不对劲。右边是神经网络机器翻译,大多数词语的意思也是对的,但语序更加自然。翻译出来的句子更容易理解、更通顺。
底层发生了什么?
我先谈谈基于短语的机器翻译。该系统学习词语之间的对应关系,然后把这些对应关系泛化到成串词语上,即短语。这些短语是从海量的句子翻译(原句 译句)中得来。给定一个新句子,该系统会根据已学到的短语翻译,试图找出一个最优分段方案。
短语越长,我们越不担心重新排列词序问题(local reordering)。数据越多,学习长短语的效果越好。
基于短语架构机器翻译的缺陷:
缺乏语境。短语一般最多只有 7 到 10 个单词的长度
短语的重新排序问题很大,尤其对于词序差异很大的语言,比如英语和土耳其语
其统计模型难以扩展新功能
泛化效果不好,非常依赖学习过的数据
再来看一看神经网络机器翻译系统。
神经机器翻译系统会考虑原句的整个语境,以及当次翻译过程中此前翻译出的所有内容。它的优点有:
支持大段的语序重排(long distance reordering)
连续、丰富的表达。我们把词语映射到矢量表示(词向量)。它们不再是独立的词语,而是一维空间中的点。不同点之间的距离,可被用来代表不同词语之间的语义相似性
神经网络的扩展性非常好。我们可以把不同来源的信息整合进去,使我们得以很容易的把不同类型的表达结合到一起
更通顺
至于为什么更多语境能起到积极作用,我想多解释一下:这里的任务,是根据语境预测下一个词语。当语境信息越丰富,预测就更准确。借助递归神经网络(RNN),我们的语言建模能力获得了无限制的提升。通过更大的视野,我们可以做出更好的决策。
对于翻译系统本身,我们也是用 RNN with attention。我们的架构包含编码器以及解码器。编码器的作用是把原语句转化为矢量表达;随后,解码器把后者转为另一个句子,这就是机器翻译的过程。
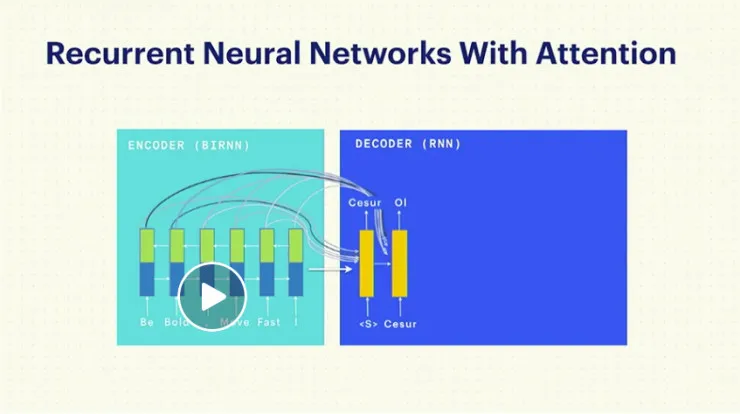
对于原语句,我们用的是一个双向的神经网络。这意味着,我们既利用了前文中的词语,也用到了后文的词语。所以,编码器的输出,是一个利用了前后文所有语境的、对原句的表示。目标句子也使用 RNN 来生成。在生成过程中的每一步,我们均充分利用了此前生成的词语,以及语境的某部分。重复这一步骤,我们便得到了最终的机器翻译结果。
挑战
1. 网络语言
首先是网络语言,我们称之为“Facebook 语言”。人们在社交网络上会使用俚语、造出来的动词,以及奇奇怪怪的拼写;还有用标点符号表情的,这直接让 Facebook 的语言识别和机器翻译系统失灵。
解决该问题的一个方案,被我们成为 sub-word units。
神经网络受到特定词汇量的限制,通常是训练阶段遇到过的词汇。对某些语言而言,这造成了非常大的麻烦,尤其是那些可以对现有词汇添加新成分、以生成一个新词汇的语言,比如土耳其语。由于这一点,我们不可能知道一个高质量翻译所需的全部词汇。
解决办法是把词汇分拆为更小的、更凝聚的单元。举个例子,可把单词 being、moving 拆成动词 ing 的形式。这种方式,可用 sub-word 模型来生成新动词,比如 ing 生成其它动词的进行时。对于 low resource 语言(LRC),这大幅提升了翻译效果,并且还能对非正式语言进行标准化。
2. low resource 语言
另一项主要挑战是 low resource 语言。正如我提到了,Facebook 支持超过 45 种语言,超过 2000 种翻译方向。训练一个翻译系统需要大量数据,不幸的是,对于许多语言我们并没有很多数据。
一个解决方案被我们成为 back translation。我们一般使用平行数据(parallel data)来训练这些系统。当我们只有少量平行数据,我们会用它来创建一个小型的翻译系统。另外,对于多门语言,我们有许多单语言数据(monolingual data),即只以一门语言表示的数据。所以我们把该数据填入这一小型机器翻译系统,然后获得翻译。很显然,翻译结果并不完美。
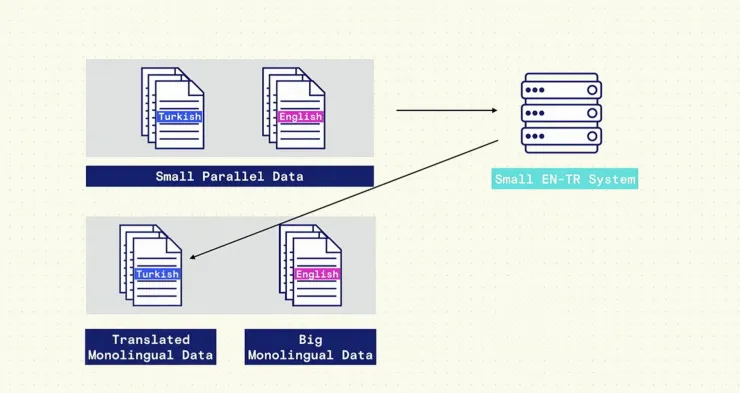
但把它们结合起来,我们可以训练更大的机器翻译系统。这种方法十分吸引人的一点,是它有两个翻译方向:它不仅生成英语到土耳其语的翻译系统,还能生成土耳其语到英语的翻译。另外,由于目标语句基于单语言数据,它会更加通顺。
3. 大规模部署
一项比较艰巨的挑战,是大规模部署机器翻译以及应用研究。我们需要训练非常多的翻译系统,并且快速地训练、快速地解码、快速地生成翻译。
一项加速计算过程的方案,名为 online vocabulary reduction (在线词汇缩减)。正如我之前提到的,在神经网络架构中,目标词汇是受限制的。词汇量越大,计算成本越高。
于是我们尽可能减小 output projection layer 的规模。
当你需要翻译一个特定语句,你可以观察句子中所有词汇的出现频率、排在最前的翻译选项,以对词汇进行筛选。
在这个例子中,你可以在活跃词汇库中忽略 and 和 move,因为对于该翻译,它们并没有对应到任意一个词汇。这使得计算时间大幅缩短,而并不牺牲翻译质量。

最后,我想说我们实现了许多提升,但仍有很长的路要走。对于 low resource 语言,我们需要做得更好,这是一个非常艰巨的挑战。我们需要开始翻译图像和视频。我们需要找到更高效地使用图像、视频中语境信息的方法。我们需要开发出私人订制的、符合语境的翻译系统。我对加入这趟“连接世界”的旅程感到万分激动并自豪。
谢谢。