

雷锋网AI科技评论按:用网络上现成的语言资料训练机器学习模型已经是现在主流的做法。研究者们希望人工智能从其中学到对人类自然语言的理解,但是人工智能所能学到的内容还远不止语法规则和词语意思。普林斯顿大学博士Aylin Caliskan等研究者已经在这方面做出了一些研究,以下是他们的发现,雷锋网编译。
关于未来的AI会是什么样子的讨论从未停止过,有一些专家认为这些机器会具有很强的逻辑性,而且非常客观非常理性。但是普林斯顿大学的研究者们已经证实了,人工智能其实也会学到创造它们的人的坏习惯。
机器学习程序通常是用网络上就能找到的正常人类对话进行训练的,那么它们在学习语言的过程中,也能够同步学到隐藏在字面意思后面的文化偏见。
4月14日的《科学》杂志刊登了研究者们的这项发现。Arvind Narayanan是这篇论文的作者之一。他担任着普林斯顿大学和CITP(信息技术政策研究所)的副教授职位,同时他还是斯坦福法学院网络与社会研究中心合作学者。在他看来,“机器学习在公平和偏见方面表现出的问题会对社会产生极为重要的影响。”
论文的第一作者Aylin Caliskan在普林斯顿大学的博士后工作站进行着研究,他同样加入了CITP。论文还有一位参与者是英国巴斯大学的学生,也加入了CITP。
Narayanan说:”我觉得目前的状况是,这些人工智能系统正在给这些曾经存在过的偏见一个持续下去的机会。现代社会可能无法接受这些偏见,我们也需要避免出现这些偏见。“
研究人员用内隐联想测验(IAT)的方法来测试机器学习程序的偏见程度。自从上世纪90年代华盛顿大学开发出了这套测试以来,它作为人类偏见的试金石,被运用在无数的社会心理学研究中。它的测试过程中会要求人类被测者把电脑屏幕上的单词根据意思进行配对,并以毫秒为单位记录下所花的时间。这项测试也反复证明了,如果被测者觉得两个单词的意思越匹配,他所花的时间就越会明显地短。
比如,“玫瑰”、"雏菊" 这样的单词就可以和正面的词汇 "爱抚"或者“爱情”配对,而"蚂蚁"、"飞蛾"这样的单词就会和“肮脏”、“丑陋”这样的单词配对。人们给描述花的单词配对的时候,会更快地配对到正面词汇上去;同样地,给描述昆虫的单词配对的时候,就会更快地配对到负面词汇上去。
普雷斯顿团队用机器学习版的IAT测试程序GloVe设计了一个实验。GloVe是斯坦福大学的研究者编写的热门开源程序,单独看甚至可以作为一个初创机器学习公司产品的核心功能。GloVe的算法可以算出一段话中指定的单词一同出现的概率。那么经常一同出现的单词之间就有更高的相关性,不经常一起出现的单词的相关性就较低。
斯坦福大学的研究者们让GloVe从网络上广泛获取了大约8400亿词的内容。在这样的词汇库中,Narayanan和他的同事们查看了很多组目标词汇,比如“程序员、工程师、科学家”,或者“护士、老师、图书馆员”,然后跟两组属性词汇比如“男的、男性”和“女的、女性”进行交叉对比,看看人类在这些事情上会有怎样的偏见。
然后结果展示出,既有“对花的喜欢多一些、对昆虫的喜欢少一些”这样比较单纯、无攻击性的偏好存在,也有跟性别、种族相关的严重偏见出现。普林斯顿的机器学习测试与人类参与对应的IAT测试体现出了如出一辙的结果。
具体举个例子,这个机器学习程序会更多地把带有家庭属性的单词和女性相关联,比如“父母”和“婚礼”;跟男性相关联更多的则是与事业相关的单词,比如“专业性”和“薪水”。当然了,这种结果很大程度上是对不同性别有着不对等的社会职能的真实、客观反映,正如现实世界中确实有77%的美国计算机程序员都是男性。
这种社会职能的偏见最终可能会带来有害的男权主义影响。比如,机器学习程序有可能在对句子做翻译的过程中体现出、甚至加强了对性别的刻板印象。用到土耳其语中的不区分性别的第三人称代词”o”的时候,翻译却会把性别无关的”o bir doctor”和”o bir hemsire”(医生和护士)翻译成带有明显性别区分的“他是医生”和“她是护士”。
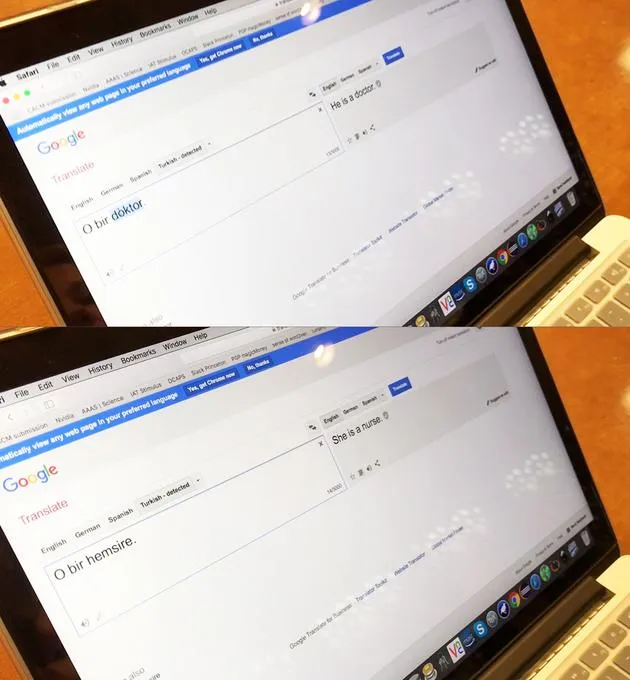 谷歌翻译会把性别无关的”o bir doctor”和”o bir hemsire”(医生和护士)翻译成带有明显性别区分的“他是医生”和“她是护士”。
谷歌翻译会把性别无关的”o bir doctor”和”o bir hemsire”(医生和护士)翻译成带有明显性别区分的“他是医生”和“她是护士”。“机器学习并不会因为它们的设计和运行依靠数学和算法就变得客观和公正,这个观点在这篇文章中得到了重申;”纽约研究院的高级研究员Hanna Wallach这样说,她虽然没有亲身参与这项研究,但是她很清楚状况,”相反地,只要机器学习的程序是通过社会中已经存在的数据进行训练的,那么只要这个社会还存在偏见,机器学习也就会重现这些偏见。"
研究者们还发现,机器学习程序更容易让非洲裔美国人的名字和不愉快的词语产生关联;这种事情就不怎么会发生在欧洲裔美国人名字上。同样地,这些偏见在人类中也大规模存在。芝加哥大学的Marianne Bertrand和哈佛大学的Sendhil Mullainatha在2004年合作发表过一篇著名论文,其中他们向1300个招聘职位发送了接近5000封简历,而这些简历间的区别仅仅在于求职者的名字是传统欧洲裔美国人的还是传统非洲裔美国人的。结果是惊人的,前者得到面试邀请的概率要比后者高50%。
通过给底层的AI系统和机器学习程序开发明确的、数学性的指导规范,有可能可以避免让电脑程序把人类文化中的刻板性别观念一直延续下去。就像爸爸妈妈或者老师们给小孩逐渐灌输公平公正的观念一样,人工智能的设计者们也可以努力让人工智能更多地反映出人性中更好的那一面。
Narayanan最后总结说:“我们在这篇文章中研究的偏见确实很容易在人工智能系统的设计过程被忽视,这些社会中的偏见和刻板印象以复杂的方式反映在我们语言中,而且难以去除。相比于减少甚至完全消除这些偏见,我觉得更好的方式是先接受这些偏见是我们语言习惯的一部分,然后在机器学习方面建立明确的标准来区分哪些偏见是我们可以接受的,哪些是不允许出现的。”