

这是 ONES Piece 翻译计划的第 119 篇译文。本文原载于 veekaybee.github.io,作者 Vicki Boykis,由 ONES Piece 翻译计划【方文溢】翻译。ONES Piece 是一个由 ONES Ventures 发起的非营利翻译计划,聚焦科技创新、生活方式和未来商业。如果您希望得到更「湿」的信息,我们也有播客节目「迟早更新」供您收听。
前言
隐私——有人觉得它至高无上,属于基本人权,受宪法保护;也有人觉得「我坦坦荡荡,没什么事情需要遮掩」;也有人始终搞不清楚它到底为何物。以研究都市问题而著名的作家 Jane Jacobs 曾经说过,「只有当城市是被所有人一起创造出来的时候,它才有能力为所有人都提供些什么。也只因为前者,后者才得以成立。」这个逻辑在互联网世界也说得通。只不过在实体的城市里,人们通过缴纳税收来补贴公用,而在虚拟空间里的「税收」,便是我们的隐私。
本期隐私专题的三篇文章,分别从历史、现状和未来,以不同的角度阐述、分析和想象了「隐私」这个概念以及它与我们的关系。但无论如何,大多数情况下,就像英超利物浦队的队歌所唱的那样,「你将永不独行(You’ll Never Walk Alone )」。你的身边,总有眼睛看着你。

TL; DR:Facebook 能千方百计来收集你的个人信息。完全避免使用 Facebook 是非常困难的;但通过了解它所收集的数据,你能明白使用 Facebook 的潜在风险,并在使用中更加谨慎。
目录:
- Facebook 如何收集数据
- 在你发布状态之前 Facebook 已经知道哪些信息
- 发帖之后,Facebook 收集哪些信息
- Facebook 内部如何使用你的信息:
影子档案
- Facebook 与广告商有着怎样的关系
- Facebook 把哪些数据给了政府
- 你离开 Facebook 后它还会追踪什么信息
- 使用 Facebook 时应该注意什么
- 如果不想 Facebook 掌握你的信息,你应该怎么做
Facebook 或多或少已经成了我们的虚拟客厅、线上第三空间。我们在此与朋友聊天、对新闻各抒己见、组织活动、哀悼离世的人,也在此庆祝新生婴儿、订婚、新工作、新发型以及假期。
作为社交平台,Facebook 已经占据了我们很大一部分注意力,甚至变成我们的冥想盆 。正因如此,一旦我们将自己的希望、梦想、政治声明以及孩子照片交给 Facebook,了解它作为一家商业公司是如何处理这些数据就显得至关重要了。
Facebook 确实在收集数据。2014 年,Facebook 的工程师自称每天大约能收集到 600TB 的数据。
作为对比,《战争与和平》的文本大小是 3.1MB。1966 年苏联版的《战争与和平》电影时长为 7 小时,大小为 8GB。
所以,每天 Facebook 用户上传的数据总量,相当于 19,000 万本《战争与和平》小说,或者 75,000 部《战争与和平》电影。
Facebook 的数据使用政策概述了数据收集的范围以及用途。然而,像大部分公司一样,政策里并没有清楚地告诉用户真实情况究竟如何。
我每发布一条 Facebook 状态更新,就在猜测每一次输入的信息去向哪里。持续的猜测让我困扰不不堪,于是我决定进行一番研究。以下所有信息都来自科技媒体、学术期刊,以及作为 Facebook 用户从客户角度获取到的信息。以从事十多年用户数据相关工作的数据专家角度出发,我在文章中加入了个人见解。
欢迎任何 Facebook 员工对本文提出指正。如果能知道你们没有收集和处理如下文指出的那么多数据,我将会非常高兴。
Facebook 如何收集数据
为了理解 Facebook 收集数据的过程,我做了如下的简易示意图。你从应用界面输入数据。这是属于前端的部分。
这些数据接着被纳入 Facebook 的数据库(Facebook 有很多数据库)。这是属于后端的部分。
你在前端看到的只是后端数据的一部分。

如果你对于技术细节感兴趣,Google 上能搜索到许多相关的架构示意图。Facebook 的大数据处理技术非常先进,他们工具栈包括 Hive、Hadoop、HBase、BigPipe、MySQL、Memcached 和 Thrift 等。所有这些都存放在 Facebook 众多大规模数据中心里,比如位于俄勒冈州普赖恩维尔市的数据中心。
在发布状态前 Facebook 所了解的
在你按下「发送」之前,Facebook 可能就已经开始收集数据了。你在遣词造句的时候,Facebook 已经收集了你输入的每个字符。
Facebook 曾使用这些数据来研究自我审查(Self Censorship)。
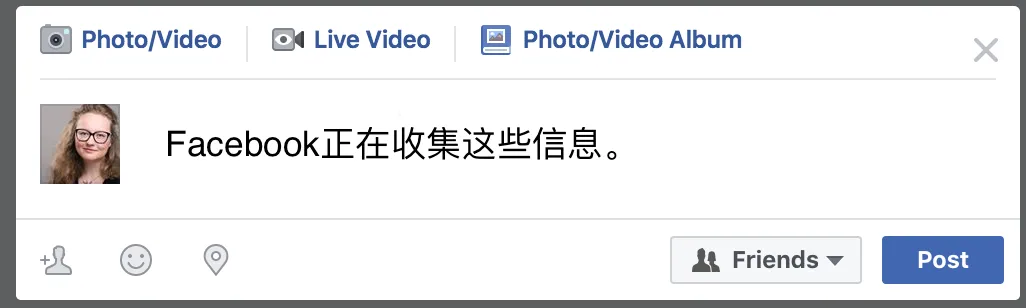
一位研究员写道:
我们的研究结果来自于一次探索性数据分析,研究的是 Facebook 里「最后时刻」的自我审查,或者被过滤后写下的内容。我们收集的数据,来自 17 天内的 3,900 万名用户。在研究过程中,我们还关联了用户的特征描述、社交图谱,以及两者之间的相互作用。
这意味着,假如你发布了一条「我恨我的老板,他快把我逼疯了」这样的状态,但在最后时刻改变了主意,「天呐,这工作真是疯了。」Facebook 仍然知道你在删除前输入了什么。
以下是一些他们用来进行研究的数据点:

这些是比较有趣的方面:删除的帖子、删除的评论,以及删除的签到。你没有写下的东西,不保证不会被 Facebook 储存;同样得不到保证的是,假如你删除了数据,它们真的能从系统中消失。
Facebook 通过跟踪元数据——即描述数据的数据——能够跟踪被删除的帖子。举个例子,一段通话的数据是你在通话期间谈论的内容,而元数据是指呼出电话的时间、地点以及通话时长等信息。
对于 Facebook 而言,元数据与原数据同等重要,也是推断你个人信息的依据之一。通过 Chrome 浏览器上的开发者工具,我们很容易看到以 xhr 形式从客户端传送到 Facebook 后端的大量数据。我并不是前端高手(但很乐意与任何一位交谈,探索其他可以提取到的数据),但从下图可以看出, Facebook 记录了你花费在某个未知动作上的时间,可能是如 Facebook 此前报告的,在网站停留的时间。
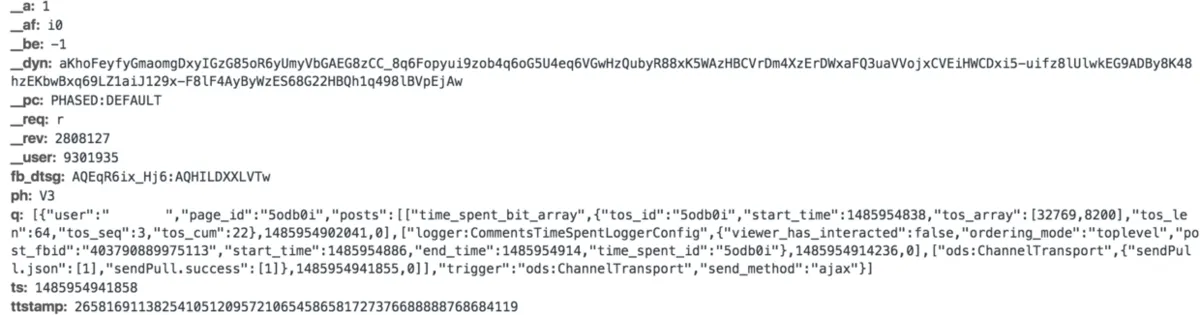
巧的是,这种情况也出现在删除账户的时候。
Facebook 有许多系统和数据汇集的地方。一名前 Facebook 顾问写道:
回答你问题的前面部分,「你是否可以有偿地让 Facebook 严格删除你所有的信息?」假设严格是指完全擦除任何你曾留在 Facebook 上的痕迹,那么答案是否定的。
对于已删除的帖文,情况类似。我们不确定 Facebook 是否真正在后端数据库中删除了帖文,而不只是在客户端上隐藏了它。
当你真正发布一则帖子、上传一张图片,或者只是修改了任意信息,Facebook 完全有权力把这些数据用于内部研究,打包销售给如 Acxiom 那样的市场数据收集机构,或者通过国安局(NSA)或者棱镜计划提供给美国政府。
发布状态后 Facebook 收集的收据
毫无疑问,Facebook 收集了你主动提供的所有数据:政治关系、工作地点、喜欢的电影、书籍、打卡的地点、你发表的评论以及任何对帖子的操作。Facebook 允许用户下载数据库中的部分个人数据。
在我的个人数据中,可以看到如下内容:
- 我上传的照片以及圈出我的照片视频
- 所有我曾发布在个人时间线上的东西(包括我曾表示感兴趣的活动、其他人发布在我时间线上的东西、分享的回忆等)
- 我的好友以及加为好友的时间
- 我所有的私人信息
- 我曾参加过的活动
- 我曾用来登录账户的所有设备
- 以及我可能感兴趣的广告。这并非我自己提供的信息,而是 Facebook 基于我所发布的东西通过算法生成的。
我们下面会谈到有关广告的部分。
除了数据以及元数据,Facebook 还跟踪用户的注意力。其中一个方法在前文已经提过:那些没有发布的状态。另外一个方法是在视频播放过程中通过热点图来记录用户的参与程度。
除了你的个人信息,Facebook 还知道有关你好友的一切。这意味着,即使你的个人资料不完整或是很少发布状态,这并不影响 Facebook 对你的了解。
Facebook 在内部如何使用你的数据
对于收集到的数据,Facebook 做了不少事情。
首先,它在收集到的数据上运行简单的程序,用来提高网站的表现,或者用于业务报告(例如网站的正常运行时间、用户量、日收入等)。其他任何一家公司也都会这么做。
然而事情在 Facebook 中有一点扭曲。它拥有的庞大工程师团队专注于构建工具,目的是提高使用 SQL 类语言查询数据的便利性,该语言建构于 Hadoop 和 Hive 之上。尽管 Facebook 声称对于数据的访问受到严格的控制,但一些报道却与此相斥。
厂牌 Anjunabeats 的主管 Paavo Siljamäki 在 Facebook 发布的一则帖子引起了人们对这个问题的关注。在一次访问 Facebook 洛杉矶办公室的时候,一位员工没有向他索要密码就能轻易访问他的账户。
更多关于 Facebook 员工访问隐私数据的事件描述,请参见这里。
其次,Facebook 把用户当作小白鼠一样进行学术研究。这是数据使用政策条款中没有提到的。有趣的是,Facebook Research 首页上的标题是:「在 Facebook,研究贯彻到我们工作的方方面面。」
Facebook 的数据科学团队非常庞大(最新数据显示为 41 个人)。相比而言,一个同样拥有 15,000 名员工的公司,如果要积极推进数据科学研究,大概仅需要 5 名数据科学家。
然而直到 2014 年,Facebook 仍然没有任何操作流程来核查被访问的数据和研究用途。一名前 Facebook 数据科学家写道:
在我任职期间,并没有机构审查委员会来审查出于内部目的进行某项实验的决策。但如果有人得到结果并要在期刊发表文章, PR 以及法务部门必定会反复斟酌将被公开的内容。但如果你想运行一个测试,看看人们是点击绿色按钮还是蓝色按钮,你不需要得到批准;或是测试一个新的广告投放系统,看看是否会提高用户的点击率和营收,这同样不需要得到批准。
他继续指出,这对于大部分 SaaS 公司来说司空见惯。但大部分 SaaS 公司并没有在十年中一直储存用户生活中最私密的细节。
他还提到:
大部分在 Facebook 与数据打交道的员工的根本目的是影响和改变用户的情绪和行为。他们一直致力于此,让你更喜欢产品故事,点击更多广告,在网站上逗留更久。
大部分网站的目的也是如此,这无可厚非。但一旦我们每天要在一个旨在影响用户情感的网站上逗留 40 分钟以上的时候,我们需要三思了。
Facebook 不仅挖掘文本,进行情感研究,还对此进行操纵利用。
Facebook 的 News Feed 功能很适合用于操纵,因为 Facebook 特意将它设计得容易沉迷。这是我们神经系统间的糖衣炮弹。Facebook 希望你花在 News Feed 的时间越多越好,花更多时间浏览婴儿照片以及其他令人愉悦的事物,和能引起争论、愤怒的新闻,这相比平淡的「我今天吃了早餐」这样的状态更能吸引回应。
今天我们所谓的「过滤气泡」(Filter Bubble)就是这样开始的。当人们只点击感兴趣的事物,Facebook 就会更偏向于展示吸引用户互动的事物,而其他观点、朋友、图片将会从你的 Facebook 信息流中消失。这个例子很好地解释了这一流程如何运作:红色信息流 vs. 蓝色信息流,你会看到自由派与保守派的 Facebook 信息流之间的差异有多么大。
Facebook 还在研究什么呢?比如,他们收集同性恋人群出柜的比例。他们是如何知道的?「在过去一年里,大概有八十万美国人更新了他们的个人资料,表明他们对同性的喜好或者使用自定义性别。」
Facebook 有很多研究着重于图谱理论,即我们与朋友之间的关系。换句话来说,它正在对一群从未表示过同意的对象进行人类学研究。
比如最近,数据科学团队发布了一项关于在美移民社群的社会关系的研究,此处研究人员使用了如下数据:
我们把分析限制于匿名的聚合数据,这些数据来自在进行此项研究之前 30 天内至少登录过 Facebook 一次的位于美国的用户。我们把用户在个人资料中填写的家乡设定为其国籍。
我们进一步对分析对象设置了限制,他们至少需要有两位现居其母国的好友,和两位现居美国的好友。我们的最终结果建立在超过一千万符合标准的用户样本上面。贯穿整篇论文,所说的「Facebook 用户」都假定符合这些限制。
这些还只是公开的研究。谁知道他们暗地里还在做其他什么研究。
另一个 Facebook 喜欢研究的对象是「人脸」——这不难理解。每一次你在照片中圈出自己,Facebook 都会识别出你并作出相应调整。
Facebook 鼓励你在个人发布的照片中把朋友圈出来,而它则收集这些信息。Facebook 使用一个叫做 DeepFace 的程序来匹配一个人的其他照片。
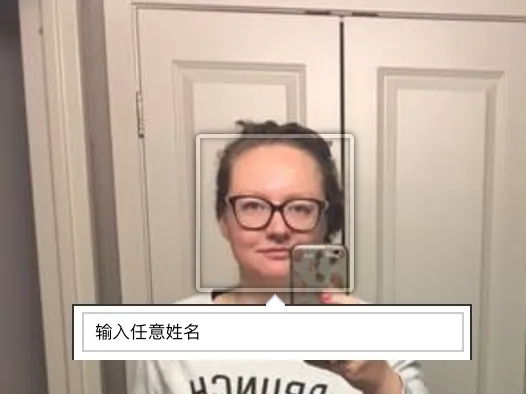
这个叫做 DeepFace 的程序,是提高标签精准度的一种绝佳方式。但同时也是一种侵犯他人隐私的糟糕方法。比方说,假如你不想被圈出来呢?如果你在参加对政府的示威呢?更简单的例子是,当你与这位朋友而不是另一位朋友参加音乐会,并且不想被别人知道呢?
不幸的是,活动的隐私很快将不由你选择了。Facebook 正在研究识别出隐藏在照片里的人的方法。一篇关于 Facebook DeepFace 的论文指出,「脸部识别技术会给社会和文化带来巨大影响。」但文中完全没有提及,在照片中被圈出来所可能带来的对隐私的侵犯。例如:
「我们很快能令商店里的摄像头识别出进店购物的顾客。」她说。
他们是如何知道这一切的呢?
因为这是我们自愿提供的数据。每当我们发布状态更新、上传图片并标签、向朋友发送信息、签到某个地方,甚至是登录 Facebook,系统都会生成相关信息并存入数据库。「嘿,这个人现在在 Facebook 的宇宙中。」这个宇宙现在还包括 WhatsApp 和 Instagram。
影子档案
当你分享的数据量没有达到 Facebook 期望的程度时,会发生什么?Facebook 会创建一个影子档案,它是「Facebook 收集的非用户提供的数据集合。」
正如文章中指出:
即使你从未提供,Facebook 也很有可能获取你的辅助电邮地址、电话号码和家庭住址,这些都要归功于渴望找到你并建立联系的朋友们。
更糟糕的是,Facebook 收集的,可以说就是你的脸。
最近一场诉讼关注的重点不在于电邮地址或者电话号码,而在于「脸部模板」:只要用户上传了图片,Facebook 将会扫描图片中的所有人脸并创建一个「数字生物特征模板」。
即使 Facebook 收集数据仅供自己使用,这也足够令人担忧了。然而还有外部合作机构。
Facebook 与广告主的关系
Facebook 的数据使用政策上提到,它与其他机构合作收集用户数据:
我们从第三方合作伙伴那里获取您在 Facebook 上和 Facebook 以外的个人与活动信息,例如:来自与我们共同提供服务的合作方的信息,或者来自广告主的有关您的广告体验与互动的信息。
它收集了「大约 29,000 个人口统计指标,其中大约有 98% 来自用户在 Facebook 上的活动。」
据报道,大约有 600 个数据点来自于独立的数据交易商比如 Experian、Acxiom 等。据称用户无法访问来自第三方的人口统计数据。
除了你主动提供的个人数据,比如完整的姓名、生日、爱好、宗教信仰、所有你曾上学以及工作的地方以外,Facebook 还会对未知的数据进行推断,所以它可以与 Acxiom 或其他广告巨头共享这些数据,以便更有效地针对你投放广告。
比如 Facebook 会基于家庭收入来创建数据档案并销售给广告主,毕竟他们才是真正的付费客户。广告主能买到精准投放的广告,包括以下任何一种或者所有信息:
地点、年龄、代际、性别、语言、教育程度、学习领域、学校、种族认同、收入和净值、住房所有权以及类型、住房价值、物业尺寸、住房的平方大小、修建年份,和家庭组成。
Facebook 是怎么知道这些的?它基于自有的数据和从 Experian 之类第三方合作伙伴中得到的数据对你作出了推断。
然后,这些信息被用来对 Facebook 用户进行广告投放。Facebook 所能进行的投放揭示出很多隐藏在背后的数据。比如,你不仅可以根据地理位置 / 年龄 / 性别 / 语言来进行投放,还可以根据爱好和生活阶段(比如,刚订婚、订婚六个月后,或者孩子刚进入学龄阶段)。即使是这么狭窄的定位,它仍然能覆盖到不少人(在我的例子中,是 100 到 200 人)。

这些数据还被出售给下游公司,与信用卡以及其他营销机构现存的关于你的数据结合,来建立一个你的完整档案。没有一劳永逸的方法能摆脱这一切,因为数据一旦被创建,删除它就变得非常困难。这就是为什么隐私权倡导者们的关注点之一就是要求商业公司定期批量删除数据。Facebook 还有权把你和你未满 18 岁的孩子的照片用在广告当中。
Facebook 提供给政府的数据
我们并不了解 Facebook 提供给政府的一切信息。Facebook 的确在网站上公开了它收到的政府请求报告,但该页面自 2016 年 6 月起就停止了更新。但我们知道,政府索取的信息不减反增。
以上数据指向的报告中表明了曾被访问的数据的规模和受到影响的用户数量,但对于提供的信息类型,以及访问数据的机构类型(本地机构、州立机构、联邦调查局或者国安局),却没有额外说明。
马克 · 扎克伯格甚至发表了一个声明:
Facebook 不处于且从未参与任何向美国或其他政府提供服务器直接访问的计划当中。我们从来没有收到任何政府机构访问大量数据的要求,也没有像报道所称的 Verizon 那样,收到要求提供大批量数据或元数据的法院命令。即使发生这种情况,我们也会积极反抗。直到昨天,我们甚至还没有听说过棱镜计划。
理解字里行间的含义很重要。对服务器的直接访问不必发送大批量的文件,也没有必要知道棱镜计划这个名字。
我们也很难知道国安局是否使用其他方法来收集 Facebook 上的数据。至少在欧洲,关于这个问题有数个诉讼正在进行。
但现在,我们暂且假设监控仍在继续。
当你退出登录时 Facebook 跟踪的数据
在 Facebook.com 以外,Facebook 会通过单点登录来跟踪你。
假如你退出,它还会通过 cookies 来追踪你。正如他们的隐私政策所述:
当您使用我们的服务来访问或使用第三方网站或手机应用时,我们会收集信息。这包括您所访问的网站和手机应用的信息,您在网站和应用上使用我们服务的信息,以及应用开发者、应用发布者或网站提供方所提供给你或我们的信息。
Facebook 正在尝试或已经在跟踪用户的鼠标在屏幕上移动的轨迹了。
早在 2011 年,当你还处于登录 Facebook 状态的时候,它就开始跟踪你在页面上移动的轨迹了。
未经你同意, Facebook 会在登录后跟踪你在网络上的位置。Nik Cubrilovic 研究得更加深入,然后发现即使在登出后跟踪仍然有效。Facebook 否认了这个说法。
但可以有把握地说它收集你的浏览历史来丰富广告内容。
在使用 Facebook 时,应作出的考虑
这一切意味着什么?基本上它意味着你在 Facebook 上的所有行为,包括处于登录状态时在其他网站上的活动,都有可能被 Facebook 跟踪,并保存在他们的服务器上。
要清楚,任何公司目前都有某种形式上的用户跟踪。这是最根本的衡量运营效率的方法。但显然 Facebook 已经游走在道德层面可接受的数据业务实践范围之外。即使 Facebook 没做过上文提到的事(如记录发布前的状态、主动干扰 News Feed),他们所进行的也是非常相似的工作,同时不能保障任何隐私或避免数据被用于实验。这还意味着即使你不是 Facebook 上的活跃用户,跟踪依然无可避免。
每一次对文章的点赞、每一个添加的好友、所有签到的位置、所有点击的商品类别、每一张照片,都被保存在 Facebook 上并被汇集起来。
如何被汇集?这很难说。也许是作为社会实验的一部分,也许被转交给政府机构,也许在 Facebook 某个没有合理权限的员工可以访问你的页面并查看你的就业历史,也许同样的就业历史被提供给了保险公司。
这包括所有私人的群组,所有关闭的群组,以及所有信息。正如 Facebook 指出,在 Facebook 就没有隐私这种东西。
简单来说,使用 Facebook 的时候,你需要假设所有行为都有可能被公开,或被用于广告,或为政府机构分析。
如何避免 Facebook 收集数据
Facebook 起初只是大学生互相连接的途径,最终成长至现在的规模,足以改变人们的行为,跟踪人们的使用情况,以及可能为政府部门搜集汇总信息。
问题在于,每个人,不管他/她是否使用 Facebook,这个社交网络的跟踪系统、关系标签和影子档案都已将他/她牵连其中。对于活跃用户来说影响就更加广泛。
所以最重要的就是必须意识到这一切确实在发生,并尽量不给 Facebook 可乘之机。
以下是我减少 Facebook 收集我个人信息的一系列措施。
并不是每个人都必须遵循我的做法。重要的是,即使你决定继续使用 Facebook,你已经意识到 Facebook 如何处理你的个人信息,也有能力权衡保持社交活跃带来的利弊。
- 不要发布过多个人信息。
- 不要发布任何你孩子的照片,特别当他们还处于无法表达同意的年龄。
- 使用完 Facebook 后登出系统。设置一个 Facebook 专用浏览器,以及另一个用于其他事情的浏览器。
- 使用广告拦截器
- 不要使用 Facebook,特别是 Messenger 来组织或参与政治活动。如果你需要组织,使用 Facebook 来作为发起点,然后转移到另一个平台。推荐的平台有:Signal 符合私人聊天软件的最高标准;WhatsApp 对于群聊来说已经足够,但它与 Facebook 的元数据系统有关联,因此我并不推荐;Telegram 也是合适的,但由于它是闭源的,所以并不够好。再一次提醒,对平台的选择取决于你愿意承担的风险。更多关于这些平台的信息请参见这里。
- 不要在手机上安装 Facebook 软件。它会向你请求很多过份的权限。
- 不要在手机上安装 Messenger,使用移动端的网页版。Messenger 在移动端上的访问受到屏蔽,但可以在浏览器上启用桌面版来迂回解决问题。
一个社交网络在带来诸多好处的同时也成为互联网上最坏的事物,这是令人悲伤的事实。但除非人们离开这个社交平台或对其施加某种经济压力,否则改变无从说起。
个人而言,作为一个数据专家,我所能做的就是给 Facebook 的招聘人员发了如下邮件。
尊敬的招聘官:
Facebook 收集以及使用数据的方法,包括:
- 转售贵公司的数据给广告公司如 Acxiom
- 跟踪用户浏览历史
- 人脸识别
- 创建影子档案
- 实施各类社会科学实验如情感传染(Emotional Contagion)
- News Feeds 的算法所带来的过滤气泡
- 以及最重要的的是,Facebook 给予包括 NSA 在内的政府机构访问平台上海量数据的权限
这不仅让我非常反感在贵公司工作,同时也让我三思自己对 Facebook 的使用,因为我不知道每一次进入系统的操作将被如何利用。
假如 Facebook 作为一家公司愿意改变方向并
- 使用数据来对抗以上某些问题
- 主动研究删除非必要数据的方法
- 主动研究私密、安全的通信,不受政府的干扰。
- 以及主动研究防止个人隐私信息被分享到不必要的第三方。
我将非常乐意了解这一切。
谨启,Vicki
我们都是社交动物,本能使我们渴望连接、认可与分享,希望在大众的社交平台上建立自己的关系。这些目前为止都是 Facebook 的优势。很难说 Facebook 没有可取之处——它确实连接了人们、帮助组织聚会和活动,使得世界的联系变得更加紧密。
但作为 Facebook 用户,我们和我们的数据是它的产品。随着我们更加了解如何使用这些数据,我们依然可以在 Facebook 的世界里活动,按照着它的规则,但并不盲从于这一切。