
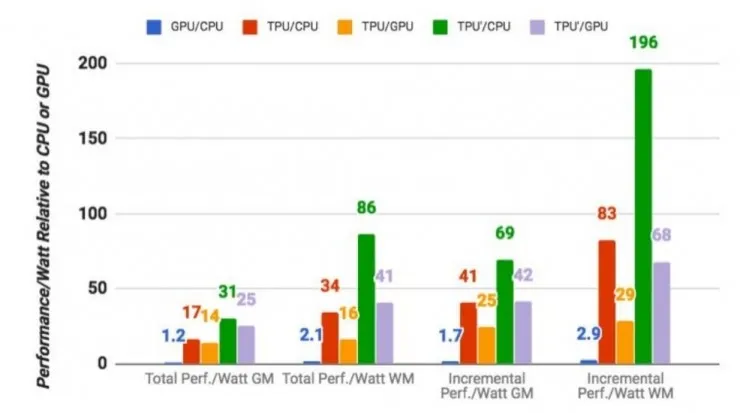
我们找到了一些资料,希望能够解答为什么 TPU 运算速度比普通的 GPU、CPU 组合快 15-30 倍。同时,我们认为 Google 在 TPU 研发上的这些创新极有可能将成为 Inter、AMD 跟进同类硬件开发的标杆,并最终成为一种趋势。
一、针对深度学习的定制化研发
TPU 是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款 ASIC。
ASIC,指依照产品需求不同而定制化的特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。一般来说,ASIC 在特定功能上进行了专项强化,可以根据需要进行复杂的设计,但相对来说,实现更高处理速度和更低能耗。相对应的,ASIC 的生产成本也非常高。
一般公司很难承担为深度学习开发专门处理器 ASIC 芯片的成本和风险。首先为了性能必须使用最好的半导体制造工艺,而现在用最新的工艺制造芯片一次性成本就要几百万美元,非常贵。就算有钱,还需要拉一支队伍从头开始设计,设计时间往往要到一年以上,time to market 时间太长,风险很大。如果无法实现规模化的应用,就算开发成功也缺少实际使用价值。所以,企业一般倾向于采用通用性的芯片(如 CPU、GPU),或者半定制化芯片(FPGA)。
谷歌之所以敢自己做定制化研发,一方面自然是有钱任性,另一方面也由于谷歌提供的很多服务,包括谷歌图像搜索(Google ImageSearch)、谷歌照片(Google Photo)、谷歌云视觉 API(Google Cloud Vision API)、谷歌翻译等产品和服务都需要用到深度神经网络。基于谷歌自身庞大的体量,开发一种专门的芯片开始具备规模化应用(大量分摊研发成本)的可能。
假如存在这样一个场景,其中人们在 1 天中使用谷歌语音进行 3 分钟搜索,并且我们要在正使用的处理器中为语音识别系统运行深度神经网络,那么我们就不得不翻倍谷歌数据中心的数量。
我们的负载是用高级的 TensorFlow 框架编写的,并是用了生产级的神经网络应用(多层感知器、卷积神经网络和 LSTM),这些应用占到了我们的数据中心的神经网络推理计算需求的 95%。
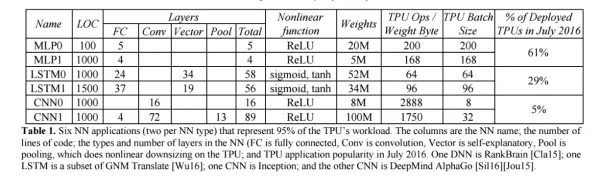
表 1:6 种神经网络应用(每种神经网络类型各 2 种)占据了 TPU 负载的 95%。表中的列依次是各种神经网络、代码的行数、神经网络中层的类型和数量(FC 是全连接层、Conv 是卷积层,Vector 是向量层,Pool 是池化层)以及 TPU 在 2016 年 7 月的应用普及程度。
相对于 CPU 和 GPU 的随时间变化的优化方法(高速缓存、无序执行、多线程、多处理、预取……),这种 TPU 的确定性的执行模型(deterministic execution model)能更好地匹配我们的神经网络应用的 99% 的响应时间需求,因为 CPU 和 GPU 更多的是帮助对吞吐量(throughout)进行平均,而非确保延迟性能。这些特性的缺失有助于解释为什么尽管 TPU 有极大的 MAC 和大内存,但却相对小和低功耗。
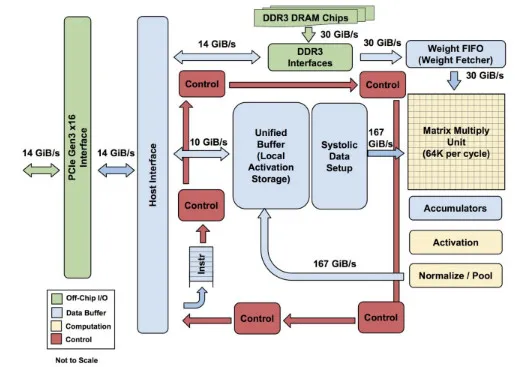
TPU 各模块的框图。主要计算部分是右上方的黄色矩阵乘法单元。其输入是蓝色的「权重 FIFO」和蓝色的统一缓存(Unified Buffer(UB));输出是蓝色的累加器(Accumulators(Acc))。黄色的激活(Activation)单元在 Acc 中执行流向 UB 的非线性函数。
二、大规模片上内存
TPU 在芯片上使用了高达 24MB 的局部内存,6MB 的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的 37%(图中蓝色部分)。
这表示 Google 充分意识到片外内存访问是 GPU 能效比低的罪魁祸首,因此不惜成本在芯片上放了巨大的内存。相比之下,Nvidia 同时期的 K80 只有 8MB 的片上内存,因此需要不断地去访问片外 DRAM。
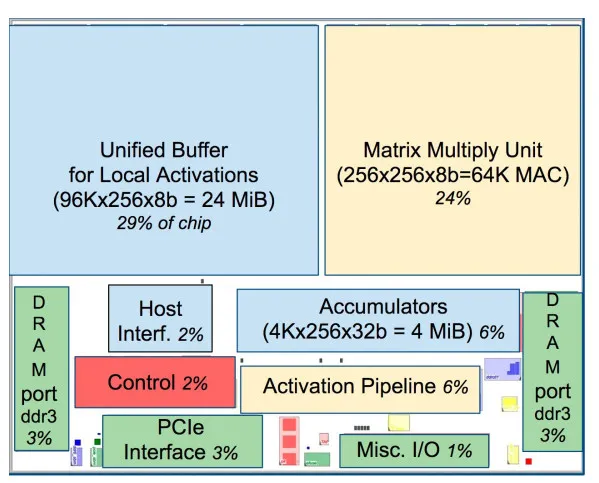
TPU 芯片布局图。蓝色的数据缓存占芯片的 37%。黄色的计算是 30%。绿色的 I/O 是 10%。红色的控制只有 2%。CPU 或 GPU 中的控制部分则要大很多(并且非常难以设计)。
三、低精度 (8-bit) 计算
TPU 的高性能还来源于对于低运算精度的容忍。
研究结果表明低精度运算带来的算法准确率损失很小,但是在硬件实现上却可以带来巨大的便利,包括功耗更低速度更快占芯片面积更小的运算单元,更小的内存带宽需求等。
这次公布的信息显示,TPU 采用了 8-bit 的低精度运算。也就是说每一步操作 TPU 将会需要更少的晶体管。在晶体管总容量不变的情况下,每单位时间可以在这些晶体管上运行更多的操作,这样就能够以更快的速度通过使用更加复杂与强大的机器学习算法得到更加智能的结果。
在 Google 的测试中,使用 64 位浮点数学运算器的 18 核心运行在 2.3 GHz 的 Haswell XeonE5-2699 v3 处理器能够处理每秒 1.3 TOPS 的运算,并提供 51GB / 秒的内存带宽;Haswell 芯片功耗为 145 瓦,其系统(拥有 256 GB 内存)满载时消耗 455 瓦特。相比之下,TPU 使用 8 位整数数学运算器,拥有 256GB 的主机内存以及 32GB 的内存,能够实现 34GB / 秒的内存带宽,处理速度高达 92 TOPS ,这比 Haswell 提升了 71 倍,此外,TPU 服务器的热功率只有 384 瓦。
四、脉动式数据流
对于 GPU,从存储器中取指令与数据将耗费大量的时间。TPU 甚至没有取命令的动作,而是主处理器提供给它当前的指令,而 TPU 根据目前的指令做相应操作,这使得 TPU 能够实现更高的计算效率。
在矩阵乘法和卷积运算中,许多数据是可以复用的,同一个数据需要和许多不同的权重相乘并累加以获得最后结果。因此,在不同的时刻,数据输入中往往只有一两个新数据需要从外面取,其他的数据只是上一个时刻数据的移位。
在这种情况下,把片上内存的数据全部 Flush 再去取新的数据无疑是非常低效的。根据这个计算特性,TPU 加入了脉动式数据流的支持,每个时钟周期数据移位,并取回一个新数据。这样做可以最大化数据复用,并减小内存访问次数,在降低内存带宽压力的同时也减小了内存访问的能量消耗。
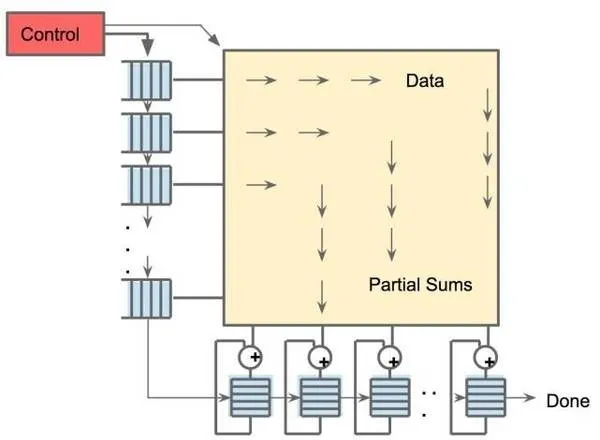
五、散热功能强化
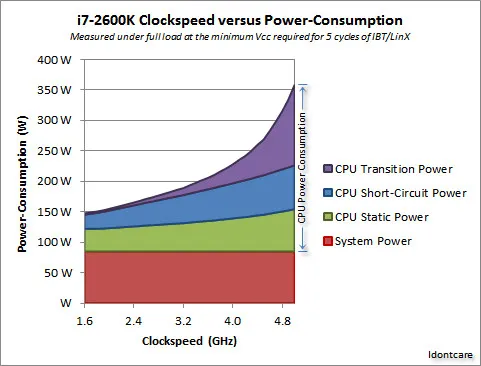
对于性能来说,限制处理器速度的最大两个因素是发热与逻辑门的延迟,其中发热是限制速度最主要的因素。现在的处理器大部分使用的是 CMOS 技术,每一个时钟周期都会产生能量耗散,所以速度越快,热量就越大。下面是一张 CPU 时钟频率与能量消耗的关系,可以看到,芯片能耗随运算速度变化呈现指数级增长。
TPU 在降低功耗的同时,对于散热能力也做了进一步的优化。从 TPU 的外观图可以看出,其中间突出一块很大的金属片,这便是为了可以很好地对 TPU 高速运算是产生大量的热进行耗散。

六、硬件、软件持续优化
谷歌认为现在的 TPU 仍在硬件和软件方面存在很大的优化空间,比如假定用上了 NVIDIA K80 GPU 中的 GDDR5 内存,那么 TPU 就可以发挥出更好的性能。
此外,谷歌工程师还为 TPU 开发了名为 CNN1 的软件,其可以让 TPU 的运行速度比普通 CPU 高出 70 多倍!