

按:近日,《最强大脑》第四季落下帷幕,凭借在人脸识别和图像检索方面的出色表现,百度人工智能机器人小度荣获“脑王” 称号。4 月 11 日,百度以此为主题在北京举办了“第五届百度技术开放日”的活动。百度研究院院长、深度学习技术及应用国家工程实验室主任林元庆做了“最强大脑背后的技术”主题演讲,详细解释了小度在“脑王”对决中的台前幕后,涉及图像检索、声纹识别、人脸识别等方向。

随后林元庆还介绍了百度将在人工智能方面着重发力的方向及下一步的计划,雷锋网总结如下:
将图像识别技术做到极致
完善声纹识别技术
视频的分析:像素级别的图像分割
医疗图像分析
开放深度学习平台
产学研融合共建七大平台
林元庆提到:
从去年开始,Robin(李彦宏)一直在讲,作为目前最重要的战略,百度的下一幕是人工智能。现在百度在人工智能方面的投入在持续的增加,过去两年每年都投入了超过 100 亿,我们希望做好这个方面。
以下是林元庆的演讲实录,雷锋网做了不改变原意的整理:
今天就从最强大脑说起吧,也会给大家展示一些百度的其他技术,随后刘炀团队说的更系统、更全面一些,就是跟开发者生态有关的,百度有哪些技术在往外面开放的。
最强大脑背后的技术
让我们先来回顾一下与最强大脑的合作历程:之前节目组找过一些国内的公司,已经得到非常多的验证,后来听说百度也在做人脸识别才找过来。我就问节目组为什么不先找我们?他们表示以前根本就不知道百度也做人脸识别,这一度令我非常惊讶。
不过对于百度来说,这样的合作也是一个契机。一方面希望我们的技术能够让大家都知道,一方面参加《最强大脑》的初衷是希望我们的技术跟最强的人类去比,看看百度大脑到底在什么样的水平上。我们是抱着输赢不是那么重要的心态去比赛的。我们内部开玩笑说,如果输了的话,我们回去还得继续做研发,如果赢了的话,我们还得回去做研发,只是希望我们真正把技术到极限,能够更好的服务到人类。
在节目中我们做过的几个任务,这里简要的回顾一下。

第一个是图像检索的技术。左边的图像是从右边 30 张照片的一张当中截取的一小块,需要找出到底是哪张图上的。就像以图搜图差不多,因为以图搜图的图像质量相对来说还是不错的,另外它是整张图片去搜,而最强大脑节目组希望看看现在我们的技术极限到底在哪,就将照片做了老化、破损处理,所以这就比现在百度的以图搜图在技术实现上还要难。
这背后我们也是使用了深度学习的方法,它能够很好的处理模糊、噪声、甚至是不同的图像角度。现在我们能够索引百亿级别的照片,可以在 1s 之内返回结果。这个技术也就几家有自主知识产权的搜索引擎在大规模的做。
刚才提到的是最新研发的技术,应该是接下来几个月吧,我们会用到新的引擎里面,到时现有的服务会有一个非常大的升级。

第二个是声纹识别。它和语音识别不太一样。语音识别是要识别出说了什么,而声纹识别是要识别出谁在说话,说话的内容不同会对声纹识别准确性有非常大的干扰。咱们人类对声音的噪声不是很敏感,做声音处理专业的人都知道,声音是信噪比非常差的,因此声纹识别其实是很有挑战性的。
现在百度非常重视基于 AI 的交互,比如现在我们有鼠标键盘,手机上的触摸屏等交互方式,我们更希望下一代是基于语音图像或者 AI 非常自然的交互,特别是语音的,你们如果有关注百度,也知道百度投入非常大的力量,在做 Duer OS,我们内部把它叫 OS,因为像这些基于语音质量交互的情况,语音已经是一个存在的信号,如果我们能利用那个信号的话,能够识别说话的人是谁,这是非常有用的。因此在这块我们后续也在继续加大投入,技术上已经取得了一些突破,最后我们希望把声纹做的跟人脸识别那样高的精度。

第三个是人脸识别。在最强大脑节目中一个是跨年龄的人脸识别,一个是跨代的人脸识别。人脸识别是由检测和识别两个技术组成。检测是给出一张照片我们能检测出人在哪里,同时还能找出像鼻子眼睛嘴巴这样的关键点在哪里。这个我们可以很自信的说没有人能做的比我们更好。
很多时候我们所说的识别精度都是针对测试集说的,2015 年年底的时候,我们搞了一个比较大的数据集,把一些相对来说简单一些的图片去掉,用了我们当时所能的达到最好的算法,在这个测试集上仅能做到 92% 的准确率。后来在 2016 年的百度云计算大会前,我们对它的数据和算法都进行了很大的迭代,错误率从8% 降低到了 2.3%,那已经是非常大的提高了。现在的错误率已经低于1% 了。
百度在 AI 领域的布局

百度现在在很多人工智能领域同时在发力,百度人工智能的核心就是百度大脑,它有四大类的应用:
语音
图像
自然语言处理
用户画像
下面这张图可以更加形象的说明百度在人工智能上的布局,中间这层人工智能基础技术就类似于上面说到的百度大脑,它们都是基于下面机器学习的平台做的研发。
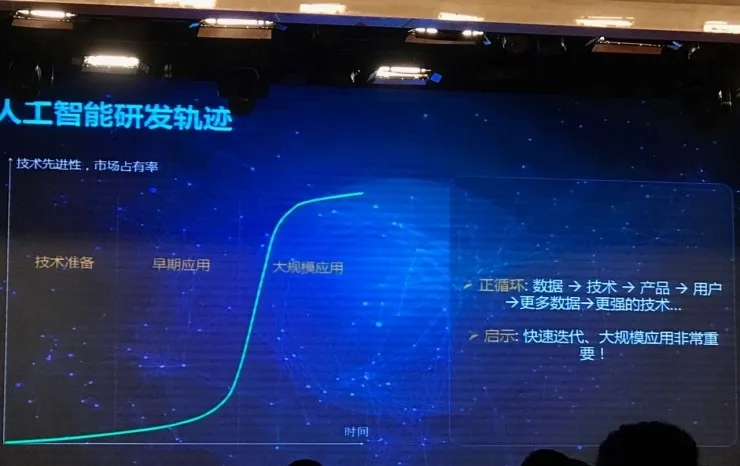
在人工智能的研发上,有一个从数据-->技术-->产品-->用户-->数据的闭环,如果闭环产生的话,技术就能够发展的非常快。现在百度在人工智能方面,哪些做哪些不做,就是看能否产生很强的闭环。
在通用图像技术方面,大家所熟知的 ImageNet 是 1000 个类 150 万张照片,而我们曾经做过的一个库就已经有 4 万类 7000 万张照片,目前我们正在做的有 11 万类,我们希望将图像识别真正做到极致。
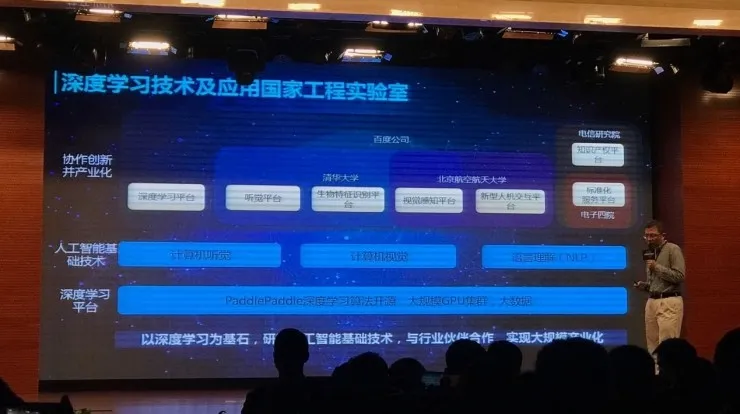
同时我们要建深度学习、听觉、生物特征识别、视觉感知、新型人机交互、知识产权、标准化服务等七大平台。这七大平台百度都要建,其中听觉和生物特征识别是和清华大学共建,视觉感知和新型人机交互是和北航共建的,知识产权和标准化服务和电信研究院共建。这些建设完成后都会向外部开放。

深度学习平台方面,现在 PaddlePaddle 已经开源了,但是还不够。第一步,我们要做一些针对 PaddlePaddle 的教程,下一步,国家工程实验室在建设一些机房,届时我们将开放一些机器,用户只需要一个账号,就可以使用这些计算资源。
下面的一些应用是百度已经比较成熟的技术,我们做好后也将对外部开放,当然现在已经开放了很多了,包括图像、语音、自然语言处理等。

现在百度还有一个正在进行的项目就是视频的分析,主要分为两个方向。一个是语义理解,就像现在非常火的短视频,我们需要理解视频里面到底发生了什么。另一个方向是 low level 的环境理解,即根据视频我们能够精确的估计出摄像头在环境中的坐标和朝向。这是三维重建非常重要的一步,我们希望结合深度学习,使其达到像素级别的图像分割。
比如自动驾驶的场景,视频中的房子、车、人、路面、天空等区域我们希望以像素为单位将其识别出来,这个现在百度正在做,我们希望能够达到 99% 以上的精度。这是非常难的一个方向,但是如果能够攻克的话,对很多应用的影响都会是非常大的,特别是无人驾驶、AR。现在百度在这方面正在筹建一个很大的团队,致力于解决这方面的问题。
还有一个是医疗图像分析的项目,百度正在花很大的力气去做,我们也希望将其做成一个很大的方向。
AI 是个新的电能,希望 AI 能够像电一样,影响各个行业,实现各个行业的升级。
从去年开始,Robin(李彦宏)一直在讲,作为目前最重要的战略,百度的下一幕是人工智能。现在百度在人工智能方面的投入在持续的增加,目前百度科研与营收比为 15%,这是非常高的,过去两年每年都投入了超过 100 亿,我们真的希望做好这个方面。
我的介绍就这些了,谢谢大家。