

传统机器学习方法,需要把训练数据集中于某一台机器或是单个数据中心里。谷歌等云服务巨头还建设了规模庞大的云计算基础设施,来对数据进行处理。现在,为利用移动设备上的人机交互来训练模型,谷歌发明了一个新名词——Federated Learning。
谷歌表示,这会是机器学习的另一大未来发展方向。
那么,什么是 Federated Learning?
它意为“联合学习”——能使多台智能手机以协作的形式,学习共享的预测模型。与此同时,所有的训练数据保存在终端设备。这意味着在 Federated Learning 的方式下,把数据保存在云端,不再是搞大规模机器学习的必要前提。
最重要的一点:Federated Learning 并不仅仅是在智能手机上运行本地模型做预测 (比如 Mobile Vision API 和 On-Device Smart Reply),而更进一步,让移动设备能够协同进行模型训练。
工作原理
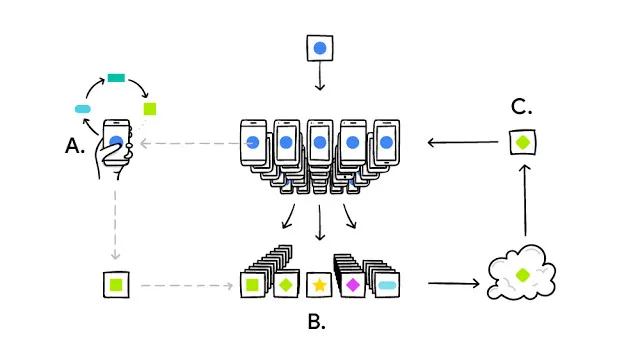
Federated Learning 的工作方式如下:
智能手机下载当前版本的模型
通过学习本地数据来改进模型
把对模型的改进,概括成一个比较小的专门更新
该更新被加密发送到云端
与其他用户的更新即时整合,作为对共享模型的改进
所有的训练数据仍然在每名终端用户的设备中,个人更新不会在云端保存。
雷锋网获知,整个过程有三个关键环节:
根据用户使用情况,每台手机在本地对模型进行个性化改进
形成一个整体的模型修改方案
应用于共享的模型
该过程会不断循环。
谷歌表示,Federated Learning 的主要优点有:
更智能的模型
低延迟
低功耗
保障用户隐私
另外,在向共享模型提供更新之外;本地的改进模型可以即时使用,这能向用户提供个性化的使用体验。
谷歌输入法
目前,谷歌正在谷歌输入法 Gboard 上测试 Federated Learning。当 Gboard 显示推荐搜索项,不论用户是否最终点击了推荐项,智能手机会在本地存储相关信息。Federated Learning 会对设备历史数据进行处理,然后对 Gboard 检索推荐模型提出改进。
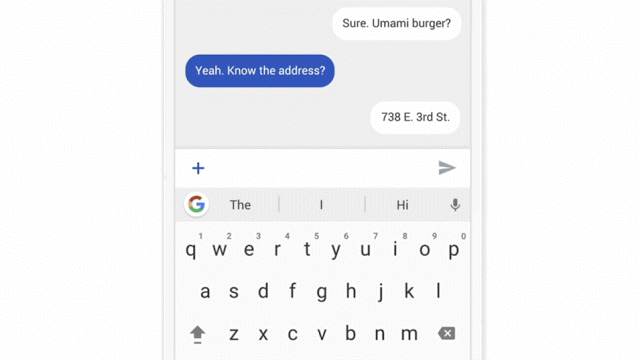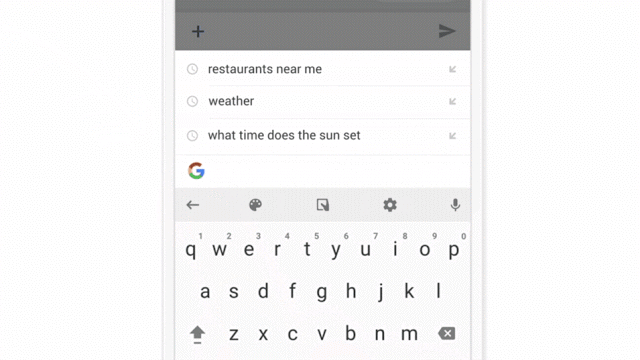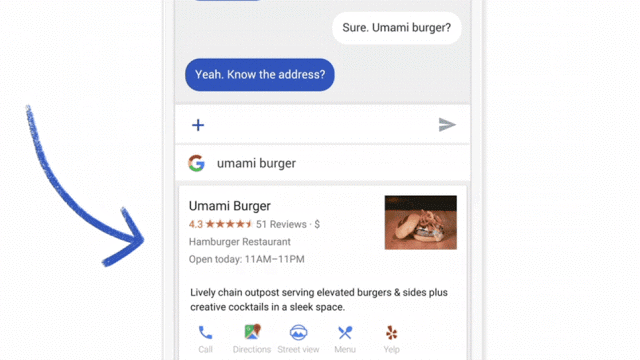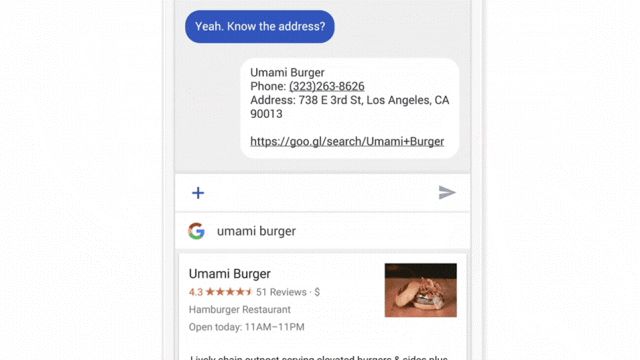
与推荐算法很像,但模型更新先在本地发生,再到云端整合。
技术挑战与解决方案
谷歌表示,实现 Federated Learning 有许多算法、技术上的挑战,比方说:
在典型的机器学习系统中,超大型数据集会被平均分割到云端的多个服务器上,像随机梯度下降(SGD)这样的优化算法便运行于其上。这类反复迭代的算法,与训练数据之间需要低延迟、高吞吐量的连接。而在 Federated Learning 的情况下,数据以非常不平均的方式分布在数百万的移动设备上。相比之下,智能手机的延迟更高、网络吞吐量更低,并且仅可在保证用户日常使用的前提下,断断续续地进行训练。
为解决这些带宽、延迟问题,谷歌开发出一套名为 Federated Averaging 的算法。雷锋网(公众号:雷锋网)了解到,相比原生的 Federated Learning 版本随机梯度下降,该算法对训练深度神经网络的通讯要求,要低 10 到 100 倍。谷歌的核心思路,是利用智能移动设备的强大处理器来计算出更高质量的更新,而不仅仅是优化。做一个好模型,高质量的更新会意味着迭代次数的减少。因此,模型训练能够减少通讯需求。
由于上行速度一般比下行速度慢很多,谷歌还开发了一种比较新奇的方式,将上行通讯需求再次减少的 100 倍之多:使用随机 rotation 和 quantization 来压缩更新。虽然这些解决方案聚焦于训练深度网络,谷歌还设计了一个针对高维稀疏 convex 模型的算法,特别擅长点击率预测等问题。
在数百万不同的智能手机上部署 Federated Learning,需要非常复杂的技术整合。设备本地的模型训练,使用的是迷你版的 TensorFlow。非常细致的 scheduling 系统,保证只有用户手机闲置、插着电、有 Wi-Fi 时才训练模型。所以在智能手机的日常使用中,Federated Learning 并不会影响性能。
谷歌强调, Federated Learning 不会在用户体验上做任何妥协。保证了此前提,用户手机才会加入 Federated Learning。
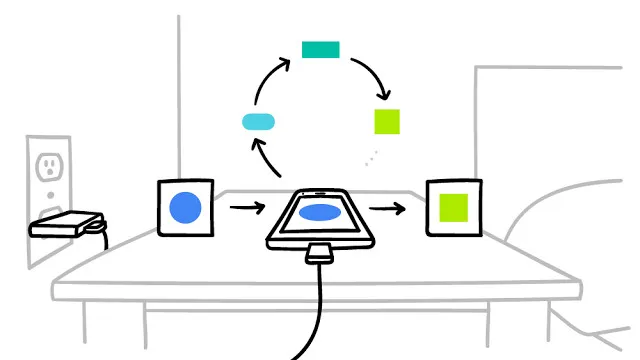
然后,该系统需要以安全、高效、可扩展、可容错的方式对模型更新进行整合。
Federated learning 不需要在云端存储用户数据。但为避免用户隐私泄露,谷歌更进一步,开发了一个名为 Secure Aggregation、使用加密技术的协议。由于此草案,系统服务器只能够解码至少 100 或 1000 名用户参与的平均更新。在整合以前,用户的个体更新不能被查看。
据雷锋网了解,这是世界上第一个此类协议,对于深度网络层级的问题以及现实通讯瓶颈具有使用价值。谷歌表示,设计 Federated Averaging,是为了让服务器只需要整合后的更新,让 Secure Aggregation 能够派上用场。另外,该草案具有通用潜力,能够应用于其他问题。谷歌正在加紧研发该协议产品级的应用执行。
小结
谷歌表示,Federated learning 的潜力十分巨大,现在只不过探索了它的皮毛。但它无法用来处理所有的机器学习问题。对于许多其他模型,必需的训练数据已经存在云端 (比如训练 Gmail 的垃圾邮件过滤器)。因此,谷歌表示会继续探索基于云计算的 ML,但同时“下定决心”不断拓展 Federated Learning 的功能。目前,在谷歌输入法的搜索推荐之外,谷歌希望根据手机输入习惯改进语言模型;以及根据图片浏览数据改进图片排列。
对 Federated Learning 进行应用,需要机器学习开发者采用新的开发工具以及全新思路——从模型开发、训练一直到模型评估。
今后,Federated Learning 是否会成为 AI 领域的一大主题,还是像网状网络技术那样停留在实验室中,我们拭目以待。
via googleblog