
可能许多刚刚接触 AI 的新人们都产生过类似这样的疑问:机器学习和数理统计,究竟有什么本质区别?不都是玩数据的么。
如果从传统意义上的数据分析师的观点来说,这个问题的答案很简单,无非是下面这两点:
机器学习本质上是一种算法,这种算法由数据分析习得,而且不依赖于规则导向的程序设计;
统计建模则是以数据为基础,利用数学方程式来探究变量变化规律的一套规范化流程。
总结来说,机器学习的关键词是预测、监督学习和非监督学习等。而数理统计是关于抽样、统计和假设检验的科学。
这个答案看起来似乎无懈可击,但其实机器学习和数理统计之间的关系远没有这么简单。
相同点
按照数理统计学的大师级人物 Larry Wasserman 的说法,实际上“这两门学科(机器学习和数理统计)关心的是同一件事,即我们能从数据中学到什么?”
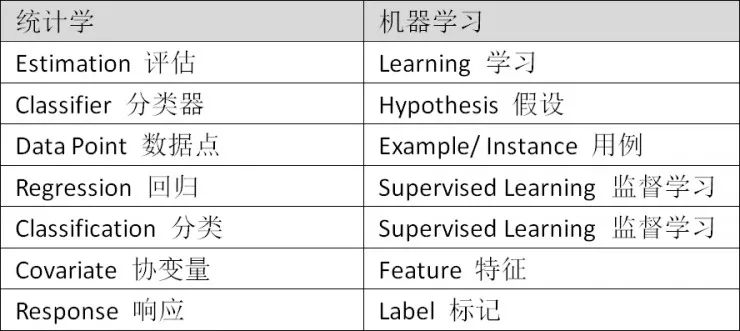
根据他在个人博客中的总结,以下这些在数理统计和机器学习中的常见术语实际上具有相同的含义。
除此之外,另一位学术界的专家,斯坦福大学著名统计学和机器学习大师 Robert Tibshirani 也一直将机器学习称为“美化过的统计学”(glorified statistics)。
实际上,发展到今天,机器学习和统计学技术都已经是模式识别、知识发现和数据挖掘等领域的常用技术。虽然根据 SAS 于 2014 年发布的统计结果(如下图),机器学习和数理统计之间的关系是相互独立的,但实际上在近两年他们之间的界限已经已经越来越模糊,甚至有相互融合的趋势。

这样看来,机器学习和数理统计的确具有相同的目标:从数据中学习。他们的核心都是探讨如何从数据中提取人们需要的信息或规律。但是,这两门学科在研究方法上却有本质的区别。
不同点
首先,机器学习是一个比较新的领域,是计算机科学与人工智能的一个分支,它更多地关心如何构建一个系统去分析数据,而不是针对特定的程序化指令。
而统计建模则完全是数学的分支。虽然现在廉价的计算能力和海量的可用数据的支持下,数据科学家们已经可以通过数据分析来训练计算机的学习能力,即机器学习。但统计建模相对机器学习而言却拥有悠久得多的历史,实际上它早在计算机被发明之前就存在了。
另一方面,机器学习更多地强调优化和性能,而统计学则更注重推导。
关于这一点,我们或许可以从下面这两段分别来自统计学家和机器学习研究人员针对同一数据模型的描述上得到更深的体会。
机器学习研究人员:在给定 a、b 和 c 的前提下,该模型准确预测出结果 Y 的概率达到了 85%。
统计学家:在给定 a、b 和 c 的前提下,该模型准确预测出结果 Y 的概率达到了 85%;而且我有九成的把握你也会得到与此相同的结论。
第三,机器学习并不需要对有关变量之间的潜在关系提出先验假设。研究人员只需要将所有的可用数据导入模型,等待算法的分析并输出其中的潜在规律,然后将这一规律应用于新数据进行预测就可以了。对于研究人员来说,机器学习就像一个黑盒子,你只需要会用,但并不清楚其中的具体实现。机器学习通常应用于高维度的数据集,你的可用数据越多,预测通常就越准确。
相比之下,统计学则必须了解数据的收集方式,估计量(包括p值和无偏估计)的统计特征,被研究人群的潜在分布规律,以及多次试验的期望参数的类型。研究人员需要非常清楚自己在做什么,并提出具有预测能力的参数。而且统计建模通常用于较低维度的数据集。
结论
总结来说,我们可以认为机器学习和统计建模是预测建模领域的两个不同分支。这两者之间的差距在过去的 10 年中正在不断缩小,而且它们之间存在许多相互学习和借鉴的地方。未来,它们之间的联系将会更加紧密。
对开发者而言,充分了解机器学习和统计建模之间的差异和联系,将有助于他们扩大自己的知识面,甚至将专业领域之外的分析方法引入研发流程之中。这一点也正是数据科学(data science)本身的核心理念,即弥合机器学习和统计建模之间的区别,让二者逐渐趋于归一化。最后需要肯定的是,这两门以数据驱动的学科之间的协作和交流越频繁,我们的生活就会变得越好。
来源:kdnuggets,雷锋网编译