

近日,蚂蚁金服与美国加州伯克利大学近期新成立的 RISE 实验室达成合作意向。RISE 实验室的前身是著名伯克利 AMP 实验室,主导研发了当今大数据计算领域最前沿的开源系统:Apache Spark、Apache Mesos、以及 Alluxio (又名“Tachyon”)。以 Apache Spark 为例,作为大数据处理的计算引擎,它具备 DAG 执行引擎以及基于内存的多轮迭代计算等优势,使得其在数据分析等工作负载上表现优秀,成为大数据领域最活跃的开源项目之一。
此前,蚂蚁金服和清华大学、同济大学等高校就基础科研进行了合作,此次和美国加州伯克利大学的合作向国际高校基础科研合作迈出了新的一步,蚂蚁金服董事长彭蕾曾在内部讲话中表明蚂蚁金服对大数据技术的人才将“不拘一格,不遗余力”。蚂蚁金服方面对雷锋网表示,和 RISE 实验室合作,除了表面对基础技术深度研究之外,更深层次是对人才长期的持续投资。
AMPLab 升级为 RISE 实验室,标志着世界顶级计算机科学系在大数据计算领域种下一个五年重大研究计划。这个新实验室专注于下一代大数据计算系统 “实时智能安全决策引擎“(RISE)的研发,世界十一家顶级科技公司成为该实验室的创始成员:谷歌、微软、亚马逊、蚂蚁金服、CAPITAL ONE、英特尔、华为、爱立信、 IBM、VMWare 和 GE。

RISE 实验室主任 Ion Stoica 教授描绘了实验室的使命愿景:解决大规模数据计算中长期未能很好解决的世界难题,机器如何在实时数据环境中快速地做出智能决策。这项技术适用于许多未来场景,从地震监控,无人车/无人机指挥与导航、到网络安全等等,需要在复杂环境交互中做出实时计算决策。
RISE 实验室的主要教授包括 Ion Stoica , Michael Jordan 等在内的涵盖了大数据系统及人工智能等领域的世界顶级专家。其前身 AMPLab,早已跻身全球前十的大学实验室。AMPLab 是加州伯克利大学六年前成立的一个交叉学科的协同实验室,致力于通过开发一个集成机器学习、云计算、集群计算和众包的新型软件栈,进而解决大数据分析面临的挑战。想了解这个名家辈出,硕果累累的实验室吗?一起与雷锋网一起来看看吧!
时势造 AMPLab
要提及 AMPLab 的诞生原因,雷锋网就不得不提及目前的研究进展所存在的一些问题。
首先,WSC(巨型计算机) 及云计算能够实现世界上最大的计算力,但是为 WSC 提供的编程环境还非常局限。为了支持更通用的数据分析,研究机构就需要量身定制一个新的软件基础设施,让 WSC 能以灵活的编程抽象结合高度并行的数据中心计算环境。
其次,大量的在线数据能够提供数据分析所必须的重要资源,但这些数据的出处各不相同,缺少普遍模式,质量也良莠不齐。我们需要拥有这样的一种数据管理技术,能从根本上「驾驭」大量、异构且并不完美的数据集。
再者,比起以传统的数据分析系统支持的数据库,数据来源的不同会让访问请求大大增加,此外也会让数据集的规模前所未有地扩张。也就是说,传统的数据分析算法需要更多的计算资源,也会带来更高的延迟。因此,研究机构需要更加灵活、更大规模且可调的分析算法,这样一来,即使是大量的访问请求,系统也能在延迟、成本与返回结果之间权衡,并得到令人满意的答案。
最后,众包服务第一次将大规模的人工输入及按需调用召集在一起,如果面临类似「ML-hard」(雷锋网按:比如对于传统机器学习或其它自动化工具而言太难的任务)的问题,众包可以说是提供了一个新的选择。但为了实现更大范围的普及,这样的众包模式需要紧密地与更多通用的数据分析框架联系在一起。
这也让 AMPLab 应运而生。
AMPLab 的诞生
面对这些挑战,AMPLab 的诞生似乎成了一种必然。2011 年 2 月 17 日, Ion Stoica 在 BEARS 2011 年度研讨会上(Berkeley EECS Annual Research Symposium)提及了 AMPLab , 这也宣告了它的正式成立。
他在演讲中提及,大数据的体量已经变得越来越大,但目前数据的管理成本非常昂贵,而且还需要合适的工具以分析数据,并从中提取有价值的信息。
因此,Stoica 认为要从三个方面提升数据分析的能力,这三者缺一不可。
首先需要提升算法适用的范围、有效性及质量(Algorithms);
其次,需要扩大数据中心的规模(Machines);
再者,还需要充分利用人类的行为及智能(People)。
这就是 AMPLab(Algorithms、Machines 及 People 实验室)名字的由来,而这个实验室也希望能够紧密地结合算法、机器与人,让大规模的数据在其中发挥功用。
AMPLab 是这样描述他们的理念的:「我们希望将数据转化为信息,为这个世界赋予意义。数年来,我们在机器学习、数据挖掘、数据集、信息检索、自然语言处理与语音识别的研究已经逐步改进相关的技术,并揭示不透明数据集里的信息。但计算机科学目前处于数据分析发展的关键节点,主要得益于巨型计算机的出现(WSC),在线数据的爆发式增长,多样性与时间敏感性强的数据访问,再者就是众包的出现了。这些趋势合在一起——通常我们笼统地称为大数据——在数据分析上彰显了它的潜力。」
AMPLab 主要由学校的几位老师牵头组织,比如:
Michael Franklin,主负责人、数据库主管:
ACM Fellow,于 1993 年在威斯康辛大学麦迪逊分校获得计算机科学博士学位,年度 ACM SIGMOD 十年最佳论文奖获得者、曾获 ICDE 2013 和 NSDI 2012 最佳论文奖。也曾被 IBM、谷歌及 Facebook 授予最佳研究奖。
联合负责人 Michael Jordan,负责机器学习:
AAAI, ACM, ASA, CSS, IEEE, IMS, ISBA 和 SIAM Fellow,此前在 MIT 就职十年教授,后于 1998 年担任加州伯克利教授至今。最近刚获得了 IJCAI 2016 的最佳研究奖。
联合负责人 Ion Stoica,负责系统方面的工作。
Ion Stoica 为 ACM Fellow,2000 于 CMU 博士毕业,主要关注云计算及网络化计算系统。与此同时他也是 Databricks 的技术顾问。
此外还有主管计算机网络 Scott Shenker、计算机架构的 David Patterson 和 Randy Katz,还有安全隐私层面的 Anthony Joseph 等。
如此群星荟萃的名师,自然吸引了一大批学生慕名前来,甚至也成为了一些学生申请加州伯克利的理由。比如 Spark 的核心成员、Databricks 联合创始人 Reynold Xin(辛湜)此前在接受 CSDN 采访时表示,申请学校的一大原因就是 AMPLab 的建立。
「伯克利数据库和系统领域的研究项目基本上都会开源,对工业界有比较深的影响(BSD, PostgreSQL, Berkeley DB, TinyOS 等等)。我个人希望我的研究想法可以超越论文的阶段,所以伯克利这几点十分吸引我。」
六年来,AMPLab 得到了加州伯克利大学计算机科学及数据相关应用领域的老师、学生及机构的合力帮助,致力于利用大数据分析解决问题。
此外,AMPLab 的建立还得到了一大波科技企业的支持,谷歌、SAP、亚马逊、ebay、华为、IBM、英特尔、微软等公司都为伯克利大学提供了资金及资源等多方面的赞助。赞助企业会参加两年一度的交流会,为研究成果提出建议及具有国际视野的洞见,并且与相关项目的研究者进行深入的交流。
据负责人 Michael Franklin 介绍,实验室也得到了美国政府的支持,获得了 5 年的美国自然科学基金-信息科学与工程「计算探险计划」资助(2012 年白宫大数据研究计划的一部分)。
仅在去年,AMPLab 在各大期刊及平台上发表了 21 篇文章,包括 ICLR、NIPS、KDD、SIGMOD 等,主要集中于机器学习及数据分析等领域。根据 Marelrei 前段时间的统计,雷锋网(公众号:雷锋网)发现加州伯克利大学发表了 33 篇与人工智能有关的论文,虽然两者的统计方式有所不同,可能出现重叠之处,但雷锋网引用这两个数字为大家做个简单的对比:实验室果然高产!
六年沉淀,硕果累累
而 AMPLab 经过六年的发展,已经形成了 BDAS,即 the Berkeley Data Analytics Stack,也就是基于实验室成果而整合开发的开源软件栈。学过编程的小伙伴自然在下图中能看到了一些熟悉的身影,雷锋网将简单介绍其中几个系统。
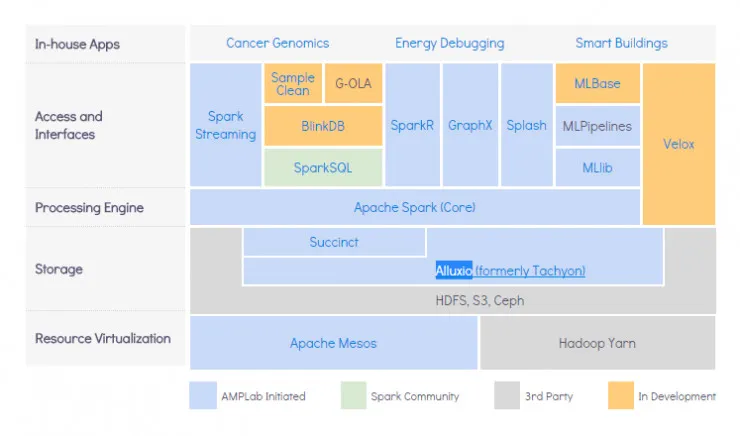
Spark:高效分布式计算系统
核心自然是大数据处理引擎 Apache Spark 了。Apache Spark 原名为 Spark,最开始是一个学生项目,计划实现一个类 Hadoop MapReduce 高效的分布式计算系统,后来与 Apache 合作成为旗下孵化项目,并成立了 Databricks 公司。
官网上显示,它有以下四个优势:
运行速度快,比起 Hadoop 的性能要快上 100 倍,此外 Spark 还能提供比 Hadoop 更上层的 API,长度只有 Hadoop 的 10% 甚至是 1%。
简洁易用,支持 Java、Scala、Python、R 语言。
整合性强。它基于 RDD 提供了一体化解决方案,整合了 MapReduce、Streaming、SQL、机器学习、图像处理等模型,并提供 API 公开及相同的部署方案。
适用范围广。Spark 能够在 Hadoop、Mesos、standalone 或云上运行,也能处理包括 HDFS、Cassandra、HBase 和 S3 在内的数据来源。
与 Hadoop 相比,Spark 采用了内存分布数据集,可用于构建大型、低延迟的数据分析应用程序。
Mesos:资源可视化的功臣
Mesos 也是源于 AMPLab 的一个项目,是 Apache 下的开源分布式资源管理框架,它的特点在于可以将数据中心放在一台电脑里运行,隐藏内部的复杂结构,并对外提供简单的 API。根据官网介绍,Mesos 能够将 CPU、存储及其它计算资源与机器抽离开来,并提供兼容性强与分布式系统,使计算构建更加简便且运行效率提升。
Mesos 在 Twitter 上得到了广泛使用,此外 Airbnb、eBay 及 Netflix 也部署了 Mesos。可以说,Mesos 在克服资源利用率方面做出了大的贡献,堪称分布式系统的内核。
Alluxio:分布式存储的新星
Alluxio 也是 AMPLab 中不可忽视的一个,前身是 Tachyon,由当时的博士研究生李浩源(HY)带头。HY 见证了 Spark 与 Mesos 的在计算与资源管理方面的快速发展,因此计划从存储入手,计划将高速内存数据实现跨应用共享。
Alluxio 能够以文件形式在内存或其它存储设施中提供数据的存取服务,是全球首个基于内存为中心的虚拟分布式存储系统。
该项目在孵化后成立了公司 Alluxio,并得到了包括阿里、百度、IBM、英特尔等多家公司的支持,后者也一直采用他们的服务访问数据。
AMPLab 展望的未来是这样的:通过技术不断发展的各类设备,借由海量数据、云计算,沟通的特点,人类与云端紧密连接在一起,并持续、灵活且充满活力地解决各类困难问题。
而我们也相信,AMPLab 会在研究的路上披荆斩棘,与更多的学者一起共绘大数据分析的蓝图。
而在今年 2 月 9 日,伯克利大学又将召开 2017 年的 BEARS 大会,本次主题为 Brains and Machines,雷锋网也将到现场做相关报道,敬请期待。