

【AI 世代编者按】《最强大脑》上周起引入机器人参与到与人类的比拼中,在第一期面部识别的 PK 中,百度机器人上来就给人类选手一个下马威,领先人类先得一分,本周再战,总共三期的对决,这一期人类没有退路。
本周,人类和机器人将比拼语音识别技能。
虽然人工智能在语音识别上面一直不断进步,但相比较人类而言,仍然没有十足胜出的把握。特别是在复杂的声音环境下,人类能轻松分辨杂音,机器却未必一定能听出来。
本期的节目设置就在这方面做了文章。
人机大战第二期《不能说的秘密》赛况介绍
周杰伦化身接头人,派出三位线人隐藏在大脑合唱团(21 人)中“收集情报”,周杰伦和三名线人接头过程中通话遭到干扰,通话时断时续,线人声音暴露,我方担心线人安危,派出“机器人小度”和“名人堂”选手孙亦廷前去营救,两位营救队员只能根据不稳定通话中的只言片语作为辨别依据,在性别相同、年龄相仿、声线极为相似的专业合唱团中将 3 位线人找出,找出多者获胜。

人类派出的选手为“听音神童”孙亦廷。在《最强大脑》第二季中,孙亦廷面对将被蒙住双眼仅凭听水球坠地破碎的声音来判断其落下高度(要求正负相差 1 米)的挑战。“听音神童”孙亦廷。虽然孙亦廷他只有 8 岁,但却有着超乎常人的听力。
他的父亲说他从小就表现出很强的音乐天赋,大自然中的一切声音进入他的耳朵,都可以转化为五线谱上的音符,这个活泼好动的小鬼毫不谦虚地说:“我的耳朵是最棒的!”
而百度机器人所具备的 Deep Speech 语音识别技术,在 2016 年 2 月,Deep Speech 入选 MIT 2016 年全球十大突破技术。
Deep Speech 专注于提高嘈杂环境下的英语语音识别的准确率,它在噪音环境中的识别准确率超越谷歌、苹果的语音技术。在此基础上,研发了可实现普通话语音查询功能,识别准确率高达 94%。
目前,Deep Speech 通过使用一个单一的学习算法具备准确识别英语和汉语的能力。百度通过框架性的创新使汉语安静环境普通话语音识别技术的识别相对错误率比现有技术降低 15% 以上,识别率已接近 97%。
最终,孙亦廷和机器人分别准确识别出一位“线人”,这期以平局收场。语音识别让人类勉强保留住了一次尊严。
声纹识别比赛难点及技术解析
本次比赛对机器来说是声纹识别。声纹识别和语音识别一样,都是通过对采集到的语音信号进行分析和处理,提取相应的特征或建立相应的模型,然后据此做出判断;但它与语音识别又有区别,其目的不是识别语音的内容,而是识别说话人的身份。
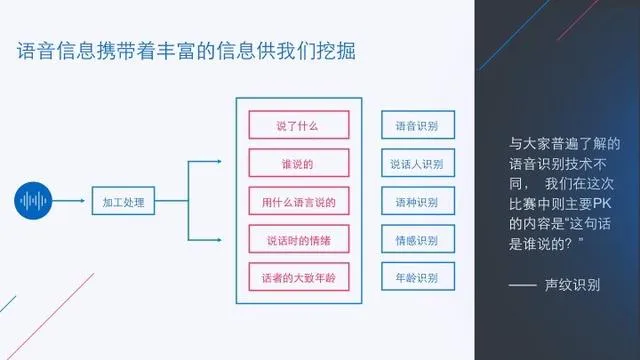
1、什么是声纹识别?
声纹识别简单的说就是判断给定的一句话到底是谁说的技术。早在上世纪 40 年代末期就有相关研究者开始进行相关技术的探索,主要应用于军事情报领域。其理论基础就是“每个人的说话特性都具有其独特的特征”,而决定这种独特特征的主要因素有:
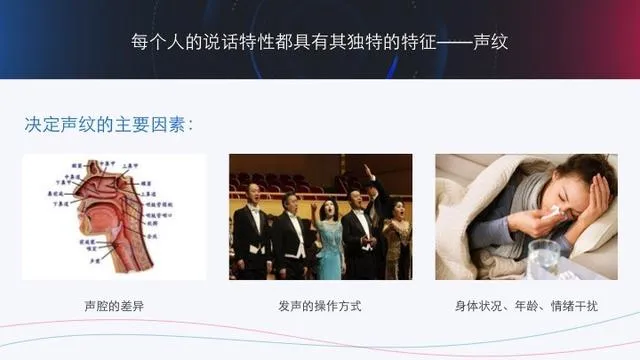
1) 声腔的差异,其包括咽喉、鼻腔、口腔以及胸腔等,这些器官的形状、尺寸和位置决定了声腔的差异。因此大家可以感受到,不同的人说话,其声音的频率分布是不同的;
2) 发声的操作方式,主要是指唇、口齿、舌头等部位在发声时的相互作用。一般而言,人在逐渐的学习过程中就会慢慢的形成了自己的声纹特性,正常说话时的声纹状态还是相对稳定的。但是声纹特性仍然具有易变性,因为影响声纹特性的两个因素非常容易受身体状况、年龄、情绪等情况的干扰,从而导致声纹特性的变化。例如:人随着年龄的变化声纹特性也在随之变化,尤其是小时候和成年后;人在感冒时由于鼻腔堵塞等问题会明显感觉到声纹特性的不一致等。当然,人也可以通过刻意的模仿等形成不同的声纹特性。总而言之,声纹特征是类似于虹膜、指纹等一种具有独特性的生物特征。
声纹识别从任务上来说,主要分为声纹确认技术(1:1)和声纹识别技术(1:N)两类。声纹确认技术回答的是两句话到底是不是一个人说的问题,而声纹识别技术回答的则是”给定的一句话属于样本库中谁说的”问题。本次节目就是采用了“声纹识别”任务,在 21 位声音特性及其相似的歌手中,凭借着有限的声音样本,来回答样本属于谁的问题。

2、“不能说的秘密”声纹识别难点?
1) 难度一:泛化能力
目前机器学习算法大多采用数据驱动的方法,什么是数据驱动呢?
简单来说,就是“你给了机器什么样的数据,机器以后就只认识这样的数据。”而在面对与学习时不一样的数据时,机器则往往会存在识别障碍。衡量一个机器学习算法好坏的一个重要指标,就是机器能够处理学习时没有遇见过的样本的能力,这种能力被称之为”泛化能力”。
例如,如果百度让机器学习识别狗时,用的学习样本都是成年的阿拉斯加,那么算法在遇到泰迪时,就会极有可能告诉你泰迪不是一只狗。在声纹识别中百度也会面临着同样的问题,传统的声纹识别任务都是注册和测试都是非常匹配的,即注册采用正常说话,测试也是正常说话。
而在本次比赛中,注册的语音则变成了唱歌,测试的才是正常说话。因此,百度需要让百度的模型能够学到同一个人在唱歌和说话时的差异。这对声纹识别算法的泛化能力提出了更高的要求。
2) 难度二:注册语音的趋同效应
一般而言,正常人说话时的声音特征是具有明显的差异的。而本次比赛采用的大合唱形式能显著的降低了不同人的差异性。由于合唱的要求大家的声音能像一个人那样的整齐,因此不同的合唱队员的唱歌样本就会有趋同效应,大家会刻意的通过改变发音习惯等来使得合唱的效果更好。这就好比分类难度从猫和狗的识别变成了阿拉斯加和哈士奇的区别。二者的难度有明显的差异。并且,合唱的内容有长时间的语气词内容,更进步增加了注册语音的混淆程度。
3) 难度三:线人测试声音的断断续续
由于人在发音时,存在协同发音的效应,即前后相连的语音总是彼此影响,后面说的内容会受前面说的内容的影响。而这些特性会被机器已数据驱动的方式学习到模型中,而在面临断断续续的语音时,特定说话人的一些发音习惯就有很大可能被损坏掉,从而加大了说话人特征提取表征的难度。
4) 难度四:线人测试声音时长过短
由于目前的机器学习的算法要能够有效的表征出一段语音能够表示的说话人信息,那么这段语音必须要有足够长。否则,语音过短,提取出来的特征不足以有效的表征该说话人的信息,就会导致系统性能出现严重下降。这就是声纹识别领域中的短时语音声纹验证难题。在实际测试中,线人说话的声音过短,不超过 10 个字,有效时间长短也小于 3s。这就给百度的算法带来了极大的难度,百度需要更为鲁棒(Robust)的来提取出短时的、断断续续的线人说话声音所能够表征的线人特性。

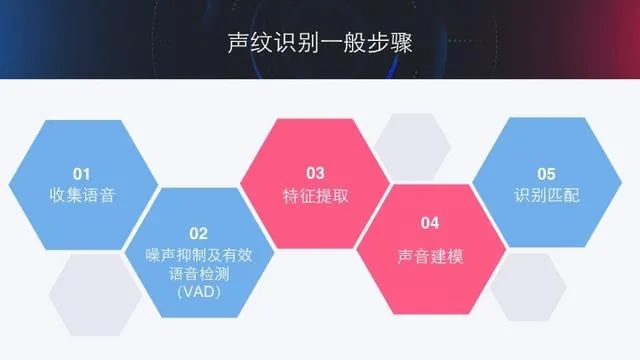
3、声纹识别通用原理是什么?
4、百度大脑声纹识别过程还原
一个基本的声纹识别过程如下图,主要包括声纹注册和声纹识别阶段:
Step1:声纹注册阶段
在声纹注册阶段,每个可能的用户都会录制足够的语音然后进行说话人特征的提取,从而形成声纹模型库。通俗来说,这个模型库就类似于字典,所有可能的字都会在该字典中被收录。
Step2:声纹测试阶段
在该阶段,测试者也会录制一定的语音,然后进行说话人特征提取,提取完成后,就会与声纹模型库中的所有注册者进行相似度计算。相似度最高的注册者即为机器认为的测试者身份。
因此,在实际比赛中,上述的过程可以被进一步解释如下图所示:
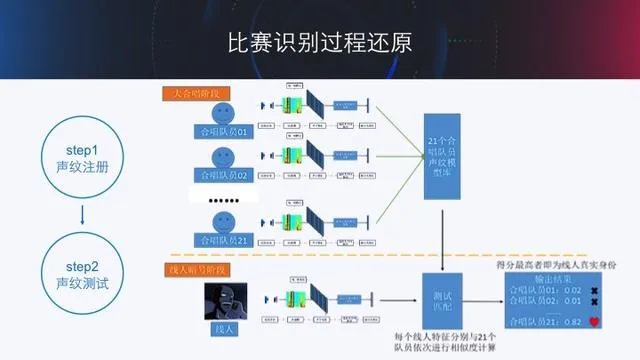
大合唱阶段,即可以对比成声纹注册阶段,百度通过收集每个合唱队员的唱歌语音,然后得到能够表征该合唱队员的说话人特征,从而构建好 21 个合唱队员的声纹模型库。
线人在与周杰伦进行对话的阶段,机器和人截获到的断断续续的语音,及可以看成是线人的测试语音,通过提取该测试语音的说话人特征,然后与模型库中的 21 个合唱队员依次进行相似度计算,相似度最高的合唱队员即为机器认为的线人真是身份。
值得一提的是,机器可以对采集到的语音进行录制,不存在记忆消失的问题,而人由于只能依靠记忆来完成对语音特征的存储。因此,机器在面临先听 21 个人合唱还是先听 3 个线人说话上是一样的,而人类则不同,在比赛中,人类先听线人说话,意味着人类只需要记住 3 个线人的说话特征,然后在从 21 个合唱队员中找出与这 3 个人相似的声音。这个难度是比,记住 21 个人唱歌,然后从 3 个人中找出对应的身份要相对简单。
5、百度大脑如何提取声纹特征?算法如何?
1) 声学特征提取
语音信号可以认为是一种短时平稳信号和长时非平稳信号,其长时的非平稳特性是由于发音器官的物理运动过程变化而产生的。从发音机理上来说,人在发出不同种类的声音时,声道的情况是不一样的,各种器官的相互作用,会形成不同的声道模型,而这种相互作用的变化所形成的不同发声差异是非线性的。但是,发声器官的运动又存在一定的惯性,所以在短时间内,百度认为语音信号还是可以当成平稳信号来处理,这个短时一般范围在 10 到 30 毫秒之间。
这个意思就是说语音信号的相关特征参数的分布规律在短时间(10-30ms)内可以认为是一致的,而在长时间来看则是有明显变化的。在数字信号处理时,一般而言百度都期望对平稳信号进行时频分析,从而提取特征。因此,在对语音信号进行特征提取的时候,百度会有一个 20ms 左右的时间窗,在这个时间窗内百度认为语音信号是平稳的。然后以这个窗为单位在语音信号上进行滑动,每一个时间窗都可以提取出一个能够表征这个时间窗内信号的特征,从而就得到了语音信号的特征序列。这个过程,百度称之为声学特征提取。这个特征能够表征出在这个时间窗内的语音信号相关信息。如下图所示:
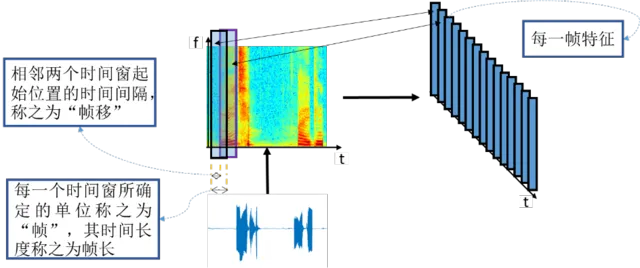
这样,百度就能够将一段语音转化得到一个以帧为单位的特征序列。由于人在说话时的随机性,不可能得到两段完全一模一样的语音,即便是同一个人连续说同样的内容时,其语音时长和特性都不能完全一致。因此,一般而言每段语音得到的特征序列长度是不一样的。
在时间窗里采取的不同的信号处理方式,就会得到不同的特征,目前常用的特征有滤波器组 fbank,梅尔频率倒谱系数 MFCC 以及感知线性预测系数 PLP 特征等。然而这些特征所含有的信息较为冗余,百度还需要进一步的方法将这些特征中所含有的说话人信息进行提纯。
2) 说话人特征提取
百度在提取说话人特征的过程中采用了经典的 DNN-ivector 系统以及基于端到端深度神经网络的说话人特征(Dvector)提取系统。两套系统从不同的角度实现了对说话人特征的抓取。
A.算法 1 DNN-ivector
这是目前被广泛采用的声纹识别系统。其主要特点就是将之前提取的声学特征通过按照一定的发声单元对齐后投影到一个较低的线性空间中,然后进行说话人信息的挖掘。直观上来说,可以理解成是在挖掘“不同的人在发同一个音时的区别是什么?”。
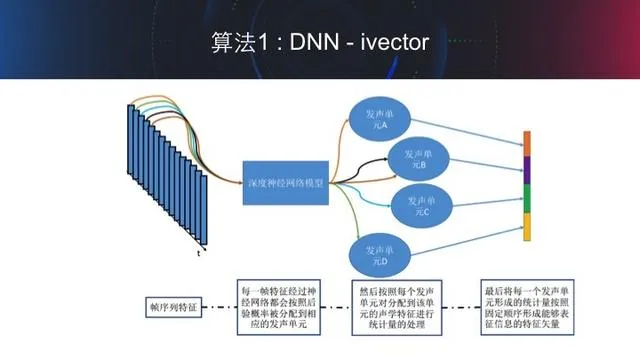
首先百度会用大量的数据训练一个能够将声学特征很好的对应到某一发声单元的神经网络,如下图所示。这样,每一帧特征通过神经网络后,就会被分配到某一发声单元上去。然后,百度会对每一句话在所有的发声单元进行逐个统计,按照每个发声单元没单位统计得到相应的信息。这样,对于每一句话百度就会得到一个高维的特征矢量。
在得到高维的特征矢量后,百度就会采用一种称之为 total variability 的建模方法对高维特征进行建模,
M=m Tw
其中m是所有训练数据得到的均值超矢量,M则是每一句话的超矢量,T是奇通过大量数据训练得到的载荷空间矩阵,w则是降维后得到的 ivector 特征矢量,根据任务情况而言,一般取几百维。最后,对这个 ivector 采用概率线性判别分析 PLDA 建模,从而挖掘出说话人的信息。
在实际中,百度依托百度领先的语音识别技术训练了一个高精度的深度神经网络来进行发声单元的对齐,然后依托海量数据训练得到了载荷矩阵空间T,最后创造性地采用了自适应方法来进行调整T空间和 PLDA 空间,大大增强了模型在唱歌和说话跨方式以及短时上的声纹识别鲁棒性。
B.算法 2 基于端到端深度学习的说话人信息提取
如果说上一套方法还借鉴了一些语音学的知识(采用了语音识别中的发声单元分类网络),那么基于端到端深度学习的说话人信息提取则是一个纯粹的数据驱动的方式。通过百度的海量数据样本以及非常深的卷积神经网络来让机器自动的去发掘声学特征中的说话人信息差异,从而提取出声学特征中的说话人信息表示。
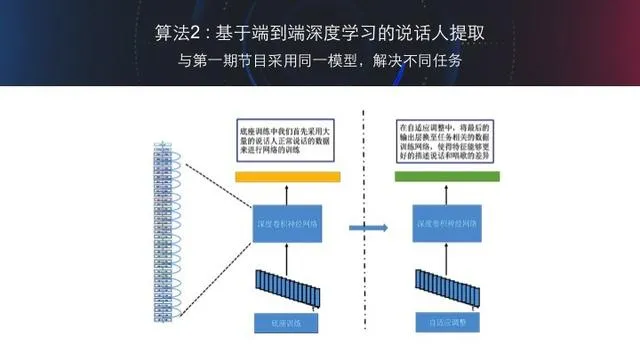
百度首先通过海量的声纹数据训练一个深度卷积神经网络,其输出的类别就是说话人的 ID,实际训练中百度使用了数万个 ID 来进行网络的训练。从而得到了能够有效表征说话人特性底座网络。在根据特定场景的任务进行自适应调优。具体过程如下图所示:
在完成网络的训练后,百度就得到了一个能够提取说话人差异信息的网络,对每一句话百度通过该网络就得到了说话人的特征。
系统的融合
两套系统百度最后在得分域上进行了加权融合,从而给出最后的判决结果。