
2016 年,就我个人来讲,所做出的最重大抉择,就是在已经工作了十三年的微软研究院(以下简称 MSR),和一个成立不过几年的创业公司——Face 旷视科技(以下简称 Face )之间,选择了后者,并且以首席科学家身份加入。
当时我还住在西雅图,当真是“身未动,消息已远”,各种报道从国内外朋友圈向我强势袭来,让我体会到了媒体的力量。时至今日,我已搬回北京,在 Face 上班近半年了,依然时常被问及:
“过的怎么样?”、“Face 和 MSR 的研究部门一吗?”、“Face 是如何开展研究工作的?……”等等。
问题或大或小,但大多诸如此类。值此新年之际,我想把自己这半年来的观察与思考与大家分享一下,权且当作对各位关心的答谢。
接下来,我将围绕大家关注的一些典型问题,逐一说明:
Face 与 MSR 的研发部门有什么异同?
就我的观察与体验,两家公司研发部门的本质是几乎没有差别的。什么叫一个公司的研发部门本质呢?我认为有三个要素极其关键:使命定位、人员组成和研发方式。坦白来讲,从这三点审视,我在两边看到了惊人的一致性,也就是说:
1)他们都同样有着既基于产品,又探索前沿技术的使命定位;
2)他们都同样聚集着一群追求极致,有 Geek 精神,且高自我驱动的精英;
3)他们都用同样的套路推进研究工作:确定问题-->实现、研究和理解既有方法-->进行持续改进或创新。
在这其中,最令人有现场触动感的还是“人”。举个最近让我感动的例子: 下面这张我在 2016 年最后一天发的朋友圈最好的诠释了 Face 的核心价值观“追求、极致、简单、可靠”中的前两点。雷锋网
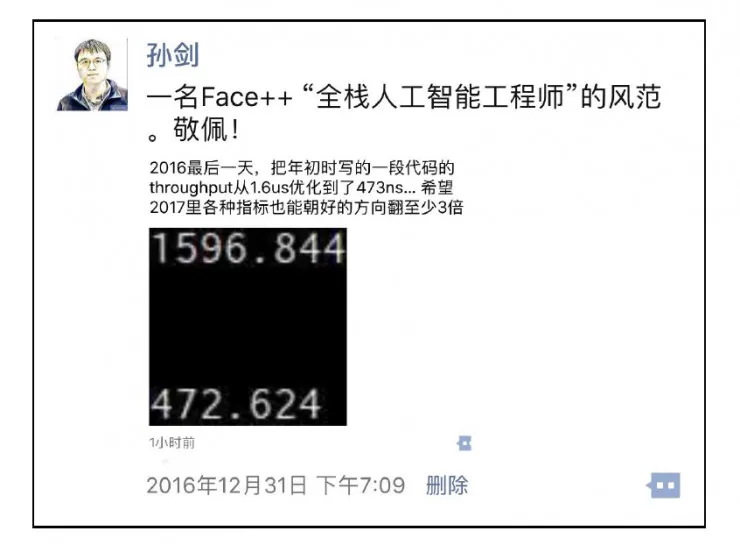
当然,即便两边研究部门的本质相同,也必然会存在着不同之处,毕竟每个公司都有其特定的文化与管理模式。当我身边的战友们从平均年龄三十多岁直降十岁的那一天突然来临时,我一方面感觉自己好像在瞬间迈入中老年的行列中(讲个梗:今天一名同事问我为什么把手机字体调的那么大),另一方面觉得自己充满了干劲,同时还有一份沉甸甸的责任感。
Face 的研究部门在研究什么?
在众多场合下问,这个问题是被提及次数最多的。为什么会有这样的疑问呢,我想不外乎两方面的思考,一是想知道公司具体研究哪些领域,长期课题与目标是什么,二是想了解一家创业公司里的研发部门,到底能不能推进真正意义上的研究工作,还是打着研究的旗号做着产品开发。
这里还隐含着一个认识上的误区,就是在我们公司被广泛称为 Face 之后,越来越多的人误以为 Face 嘛,只是在做人脸技术。人脸,目前确实是一个商业前景广阔,玩法花样不断翻新的应用。但是,Face 从创立第一天就聚焦在人工智能的三大应用领域之——计算机视觉,是以一系列视觉识别(人脸、人、物体、文字、场景、行为等)问题为中心,研发核心算法,打造能落地的产品。 消除了这样一个误区,你会比较好理解,为什么 Face 要用“Power Human with AI”作为使命,用“人工智能技术造福大众”,来发愿。毕竟公司的全名是叫旷视(英文叫 megvii, 取自 mega vision),也就是大的视觉。
回到问题本身,目前我们主要在集中研究四个视觉理解核心问题(见下图):图像分类、物体检测、语义分割、和序列学习。研究的技术路线是彻彻底底的深度学习:1)使用深度神经网络;2)尽最大可能使用端到端(end-to-end)学习。Face 应该说是这波儿人工智能创业公司当中最早研究并应用深度学习的。雷锋网(公众号:雷锋网)
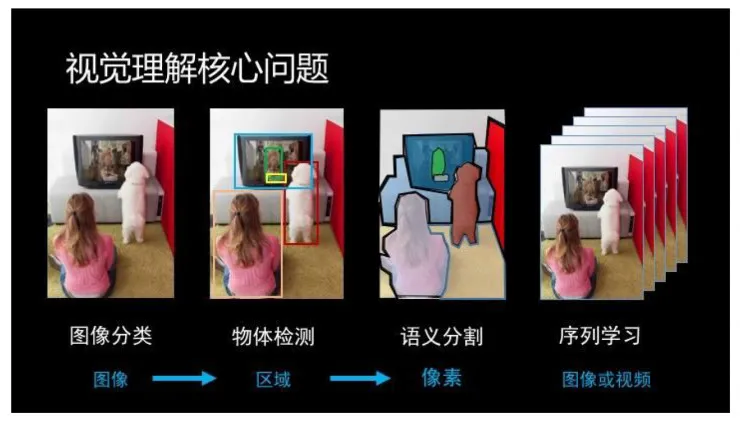
图像分类是最基础的问题。这个问题自身就有广泛的应用(例如人脸识别和场景分类),也是研究其他问题的根基。深度学习的出现使得我们从以往的特征设计走向了网络结构设计,这里包含很多对问题的深刻理解、实践中总结的经验和原理、优化算法的探索、和对下一步技术发展的判断。
我们的研发部门里有一个专门的小组负责研究如何训练最好的基础神经网络,并沿着以下三个子问题深入:
1)针对不同计算复杂度下设计最优的神经网络;
2)针对不同计算平台的实际要求,来设计最高效的网络;
3)针对不同问题设计最合适的网络。
另外对神经网络模型的压缩和低比特化表示也是我们研究的重点之一。
物体识别是解决感知图像中哪里有什么物体的问题。
典型的应用包括手机上的人脸检测, 无人车中的车辆/行人/交通标志的检测,视频分析中的各类物体检测。这个问题是图像理解中研究内容最丰富的核心问题,也是一个非常复杂的感知智能问题。
我们关心的若干子问题是:
1)如何有效地解决遮挡问题。这个问题对人来说好像是很容易的,但其实涉及到了人脑中对不可见部分自动做联想和补充的能力,已经部分属于人类的认知智能能力范畴;
2)如何有效的利用图像或视频的上下文(context)信息或我们的常识(common sense)。上下文和常识对我们避免一些明显错误和小物体检测十分重要。目前的物体对小物体检测的性能非常不理想,和人眼的能力差距还是非常大的。如果我们单独把小物体从图像中裁剪出来,人也很难识别。但是当小物体放回整副图像中,人却做得非常出色。我个人认为对这个两个子问题的深入研究真的可以对理解认知智能提供有意义指导,甚至是突破。
语义分割就是对每个像素分类,这是一个更为精细的分类任务。
比如说把识别出来的人体分割成具体部位,把人脸分割成五官,把场景分成蓝天、建筑、道路和物体等。目前在这个问题上统治性的方法是 Berkeley 在 2014 年提出的全卷积网络(FCN)。这个方法使得神经网络具有了有强大的结构化输出能力,进而将深度学习有效地推进到很多中期和初期视觉理解(例如立体匹配和光流计算)问题上。我当年博士论文就是在研究初期视觉中的立体匹配问题,十几年后的方法发生了根本性的变化,当年是想也不敢想的。我们研发部门的一名实习生在最近的 CVPR 投稿中设计了一个简单有效的 FCN 模型,在公开评测集上取得了非常好的效果。
序列学习是最有趣的问题,它的形式多样,可以输入一个序列(视频或音频)进行分类,也可以针对一副图像输出一个描述性的文字序列,或输入输出都是序列(例如识别图像中的多行文字)。
解决这三类问题的算法在 Face 的产品中都有应用。目前解决这个问题的主流方法是递归神经网络(RNN),也是现在在语音识别和自然语言处理中的大杀器。由于人的智能本质是在实时的“处理”连续不断感知到的信号流,这使得序列学习成为当下的最热的研究方向之一。尤其是最近引入外部记忆读写机制和执行单元的 RNN,让我看到了解决人工智能不少难题的一丝曙光。Face 的研究员们也正在这方面积极思考,积极实践。
在 Face 旷视科技如何开展研究?
推进研究部门的工作,核心是培养人做事的能力,并给予最好的研发环境。
培养什么人才?人才是研发的生命线。创造一个良好的环境吸引人才,培养人才,留住人才是我们的第一优先级。信息学竞赛(NOI/IOI)和大学生程序设计竞赛(ACM/ICPC)的选手们构成了研究部门的第一批战士。我们后续更多的战士来自五湖四海,拥有相当不同的背景:既有以前做视觉的,也有以前做机器学习的,既有研究基本问题的,也有专注特定应用的。
一个多样性的环境也使得我们看问题的角度更全面。在这样的基因下,我们大致将人才向两个方向培养:研究科学家,和全栈人工智能工程师。研究科学家主要聚焦在算法上,寻求对问题的本质解,我们的培养目标是成为能独挡一面领域专家;全栈人工智能工程师是我们内部的叫法,目的是培养即能上九天揽月(算法设计和训练),又能下五洋捉鳖(算法的工程化,研究问题和方式系统化)的全能战士,他们既能做 research,又懂 system,能建系统、造轮子。针对目前 AI 发展的趋势,我们需要大量的全能人才来将 AI “ ” 到不同的行业上,解决实际问题。这就对人才提出了更高的要求。我们相信即便没有 AI 背景的工程师,在这里工作1-2 年后就能成为独当一面的人才。
怎么做事?有了一帮志同道合的小伙伴们,就要围绕这上面介绍的四个视觉理解核心问题开展研究、并将研究成果应用在具体的视觉识别场景中。Face 的研发团队扁平化,每个研究小组由2-4 人组成,聚焦一个课题。课题可以是短期的,例如对已经应用的某个产品线上的算法的改进;课题也可以是长期的,例如持续提升识别的精度和性能。 我们的每个研究员都可以在不同的课题之间自由切换,这样能最大程度发挥个人的长处和积极性,同时也让大家有机会短时间了解更多的问题,有更丰富的经历,能更快的成长。套用现在深度学习的精髓,每个人的学习也需要输入大数据。
研发环境:做深度学习研究需要一个非常高效的训练引擎/平台和充沛的计算资源,Face 内部使用了近两年的“MegBrain”是一个全自主研发的训练引擎,它与目前流行的 TensorFlow(Google 一年前发布)设计相似,同属基于 Computing Graph 的新一代训练引擎。为什么非要自研系统呢?公司研究深度学习开展得非常早,当时还没有很好用的系统,并且 MegBrain 在同时满足灵活性及精简性的基础上,能最大限度提升工作效率。目前在 AI 创业公司中完全使用自研深度学习训练引擎的,可能只有 Face 。
除了核心引擎,我们的体系结构组还搭建了一个强大的深度学习平台 Brain 来管理我们庞大的 GPU 集群,来完成从数据标注和管理、模型训练、GPU 集群中心化管理、到产品化发布的“一条龙”自动化流程,从而使得我们的研发人员将宝贵的精力集中在问题上。这也使得来 Face 的实习生非常容易上手,即便对深度学习系统零基础,一套简单的教程读过后2-3 个星期就可以开始思考问题了。这些系统能够建立得益于我们团队内部的有不少“全栈人工智能工程师”,他们不仅是深度学习方面的专家,更是系统和分布式计算方面的专家。
最后针对深度学习很大程度上得益于大规模训练数据,我们还设有专门的团队负责标注工具开发和完成大量数据标注任务。以前读书时开玩笑的一个讲法是“没有不好的算法,只有不好的数据”,Datais King。
过得怎么样?
对于 Face ,我分享几个数字:我们的人工智能云开放平台的 API 已经服务了近 7 万开发者,已被调用 62 亿次;身份认证平台目前已为 1.2 亿人(注意不是 1.2 亿次)提供了刷脸服务,覆盖了 85% 的金融市场智能化应用;智慧安防和智能商业产品也覆盖到 25 个省。服务客户、追求极致,不断驱动着我们的前行。对于我自己,现在有着无比的自信能够和 Face 的研发团队一起,在这个最好的时代,做出更好的成绩,追求研究之美!