
在科技圈,如果你不懂“机器学习”,那你就 out 了。当别人在谈论机器学习娓娓道来时,你却一头雾水,怎么办?在跟同事的聊天中,你只能频频点头却插不上话,怎么办?让我们来做些改变!
Adam Geitgey 撰写了一份简单易懂的《机器学习,乐趣无限》的资料,共分为 5 个部分,主要针对所有对“机器学习”感兴趣,却苦于不知从何下手的朋友,希望能借此让更多人认识了解“机器学习”,激发其对“机器学习”的兴趣。本文为第二篇。
在这份指南的第一篇,我们讲到了,机器学习能够让你在不需要为具体问题专门编写代码的情况下,通过泛型算法告诉你一组数据的有趣之处,并且帮助解决你的实际问题。
这一次,我们将用其中一条泛型算法来做些非常酷的事情——让算法生成一个看起来像人工设计的游戏关卡。
首先,我们将建立一个神经网络系统;其次再给这个网络系统提供现存的“超级马里奥”游戏关卡数据;然后就可以坐等一个个新的游戏关卡诞生了!
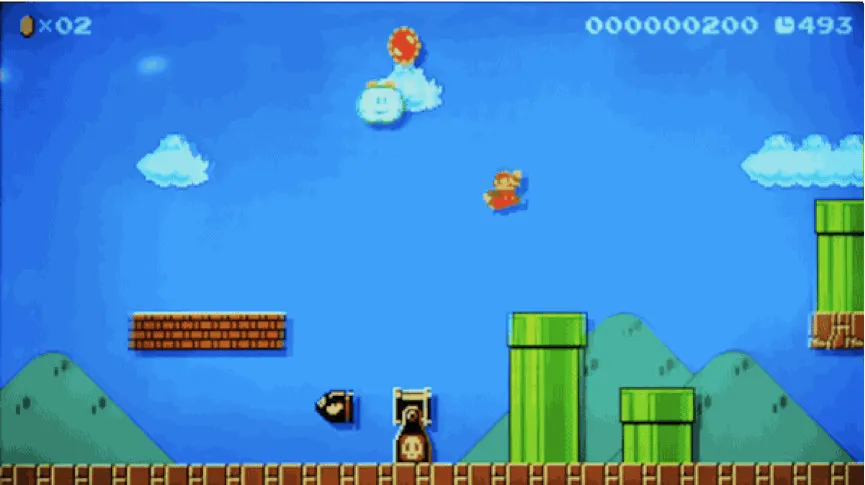
上面就是用我们的算法设计的一个游戏关卡。
就像在第一部分提到的,这份教程指南是针对所有对机器学习感兴趣,却不知从何下手的朋友。由于是面向大众,所以这份指南有概括性和不尽完整之处。但是我还是希望能借此激起大众对机器学习的兴趣,让更多人认识、了解机器学习。
作出更聪明、准确的猜测
回到指南的第一部分,我们创建了一个用于预估房子价格的简单算法 。所需提供的房子的相关数据信息如下表:

最后,我们得出了一个简单的预测函数:

换句话来说,我们把上面信息表格中的每个属性数据与一个特定的权重相乘,然后把相乘的得数简单相加,从而得到了一个房子大概的预估价格。
与其看那些纷繁复杂的编码,不如用一个简单的图表来形象、直观地表示这个函数:
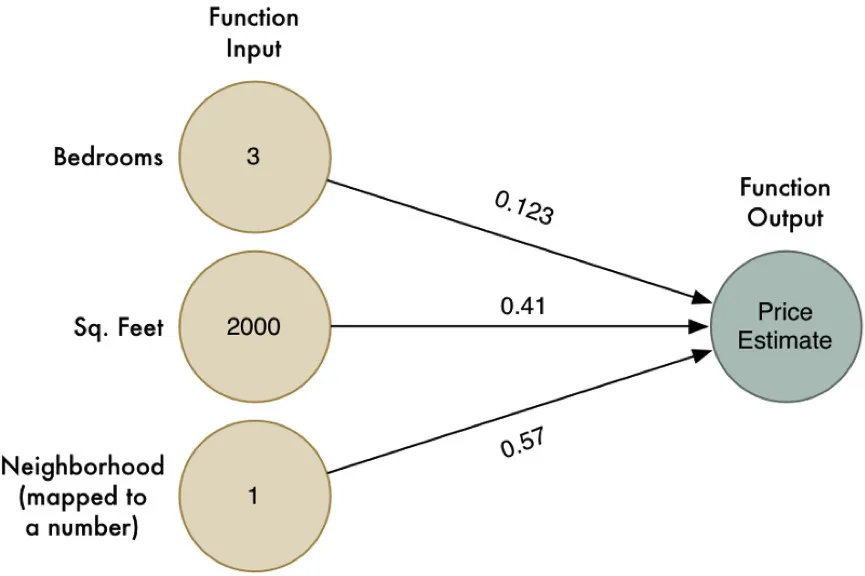
图中的箭头代表的是这个函数的权重。
然而这个算法只能解决那些输出结果与输入内容有着线性关系的简单问题,并不适用于其他复杂的问题。那么如果房价背后的现实因素并不像我们假设的那么简单呢?
比如说,有可能邻近的周边环境对大面积及小面积住宅影响非常大,但是对中等面积的房屋基本没有影响。那么我们让我们的模型函数里涵盖所有诸如此类的复杂因素和细节呢?
一个聪明的做法是:把这些复杂的边缘情况中的数据一一用到算法中来测试其准确性。
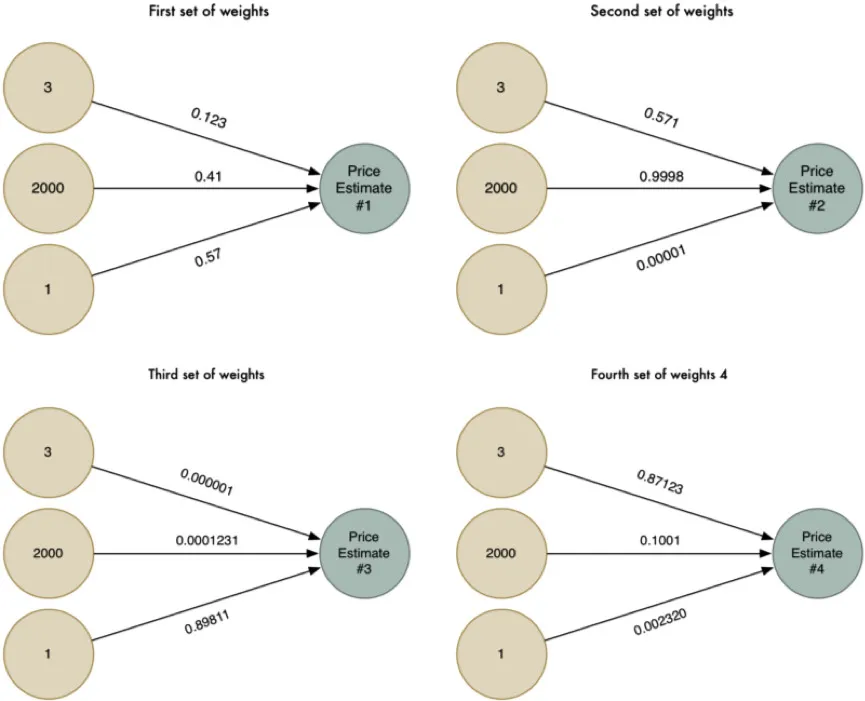
我们可以先用四种不同的方法(即四种不同的权重数据)来解决这个问题。
那么接下来很自然地,我们就会得到四个不同的估价。把这四个估价合并为一个最终的价格预期,然后再次运用到我们前面使用的算法当中。
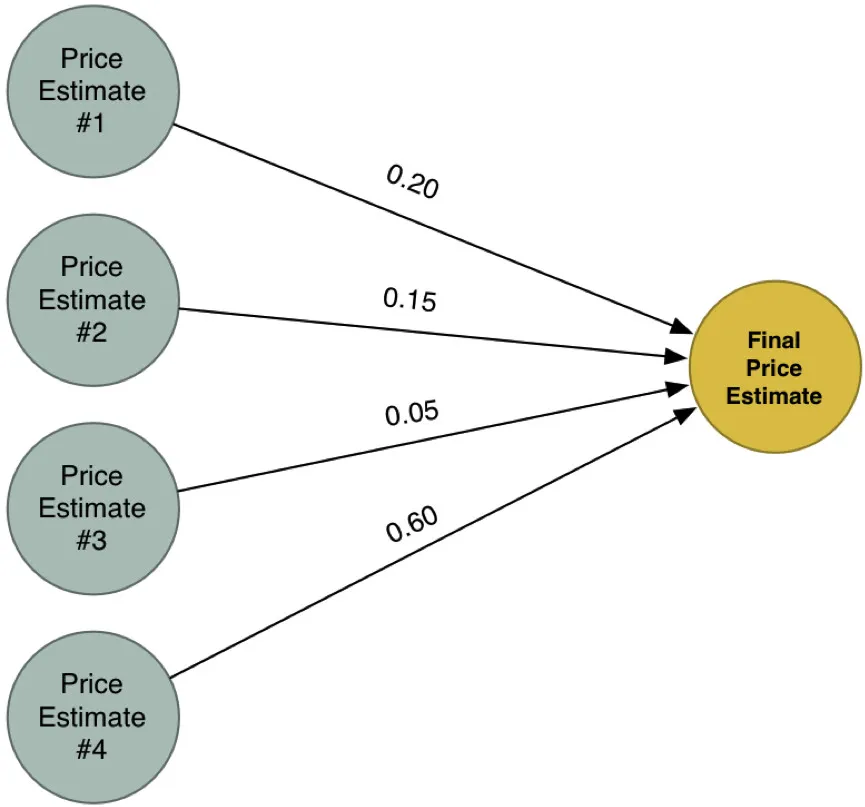
我们这个全新的“超级答案”是由前面四个不同的价格预估合并而来的。正是因为如此,与我们在单独的一个模型中所能涵盖的因素相比,它能模拟更多复杂的细节和案例。
什么是神经网络?
我们试着把前面四次不同的价格预估合并为一个大的图表:
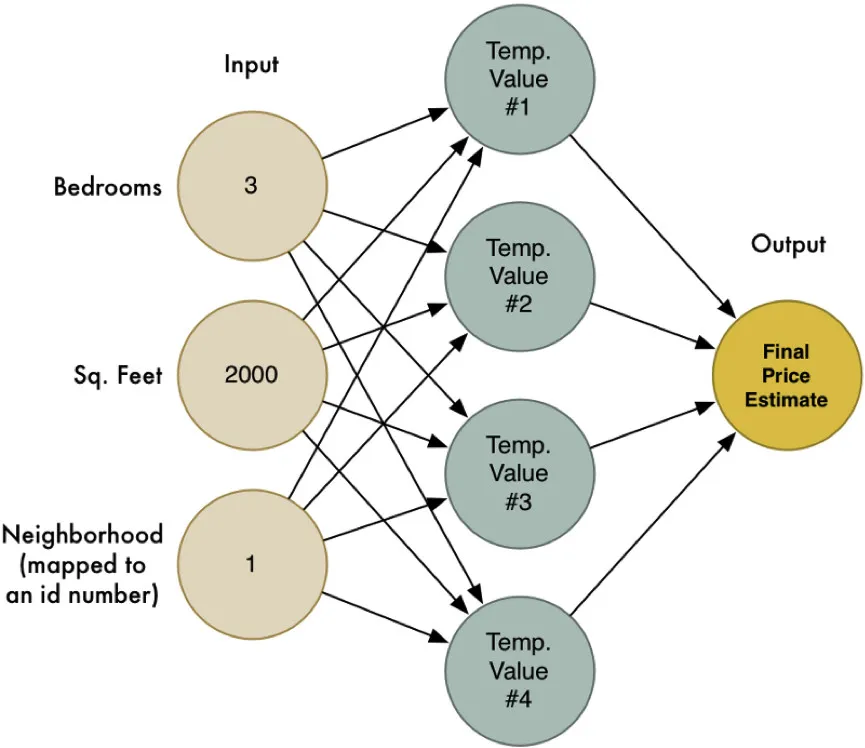
看!这就是一个神经网络。每个节点都能够接收一系列数据输入,并应用不同的权重,并且能够计算出一个确切的输出值。把这些节点链接起来,我们就能模拟很多复杂的函数。
由于篇幅有限,我在这篇文章了省略了一些与之相关的内容,比如特征标准化和激活函数。但是最重要的部分是以下这些基本内容:
- 我们建立了一个简单的预估函数,它能接收一系列数据输入,然后把这些数据与各个节点的权重相乘,最后输出一个相对确切的预估值。这个简单的预估函数叫做神经元。
- 通过这些简单的神经元的链接结合,我们可以模拟那些对于单个神经元来说过于复杂的函数。
这其中的原理就像玩乐高积木。我们无法只用一个乐高积木来搭建不同的造型,但是我们如果有足够的乐高积木,我们就能用它们搭建各种各样的造型。

赋予我们神经网络记忆的能力
我们以往了解的“类神经网络”是没有记忆的,当你输入一个相同的数据,它就只能返回到那个相同的答案。在编程计算中,这其实是一种无状态算法。
在很多案例中(比如房子价格预估),这种算法可能就足够解决你的问题。但是这种类型的模型函数是不能应对模式存在于时间推移中的数据的。
试着想象一下,我给你一个键盘,让你写一个故事。但是在你开始写之前,我要猜测你将在键盘上敲下的第一个字母,那么我究竟要猜哪个字母呢?
我可以用我的英语知识储备来增加我猜对的几率。比如,你可能会输入一个经常被用在故事开头的单词的第一个字母。如果我看过你曾经写的文章,我就能把范围缩小在你经常在故事开头使用的单词上。一旦我掌握了这些信息,我就能用它来建立一个神经网络,模拟计算你将以哪个字母开头的可能性。
我们这个神经网络的模型大概就像这样:

我们现在不妨把问题想得再复杂一点。假如说,停在你的故事的任意一个地方,我需要猜出你接下来要输入的下一个字母。那么这个问题就变得更加有意思了。
我们以海明威的《太阳依旧升起》这本书的开篇的几个单词为例:
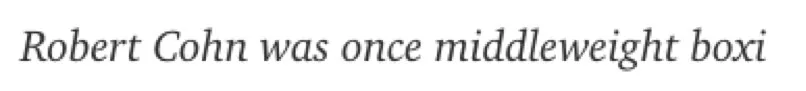
能猜出在这个不完整的单词后面的第一个字母是什么吗?
你可能会猜“n”,因为这个单词很可能会是 boxing。我们做出这个猜测,是基于对这个不完整的单词的判断以及我们最基础的英语单词的知识储备。同时句子中提到的“middleweight”(拳击比赛中中量级选手)也给了我们暗示,这个句子谈论的内容可能是拳击。
换句话来说,如果我们仔细考虑前面的字母顺序,并且结合我们的英语语言规则的知识,还是很容易就能猜出接下来即将键入的字母的。
因此,为了使用神经网络来解决这个问题,我们需要给我们的模型添加一种状态。我们每次使用这个神经网络来解决问题的时候,我们都会把中间计算结果自动保存下来,然后下次作为我们的部分输入再次使用。通过这种方式,我们的模型将会根据最近浏览的输入数据来调整预估结果。
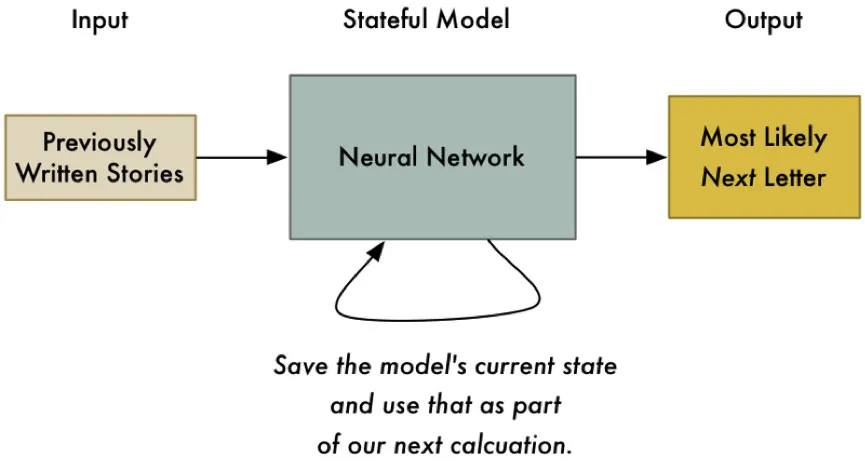
时刻追踪这个模型的“状态”,你不仅有可能猜中故事中第一个字母,甚至有可能猜中在故事任意位置的下一个字母。
以上就是递归神经网络的基本内容,简单来说就是我们每使用一次这个网络,就对它自动更新一次,同时也根据它最近浏览的信息输入对预估结果进行更新。只要我们赋予了它足够大的记忆内存,它甚至能随着时间推移来模拟各种不同条件下的模式。
猜测一个字母到底能有什么特殊意义呢?
猜测出一个故事中的即将输入的一个字母,这看起来很无聊也很无用吧?那么,猜测一个字母到底能有什么意义呢?
这其中一个很有代表性的意义就体现在手机输入键盘的输入内容自动预估功能。
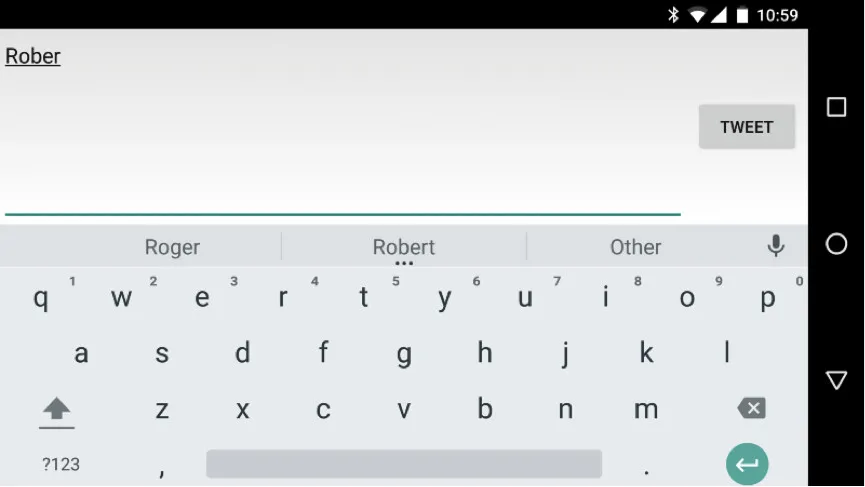
看上面的图,接下来输入的字母最有可能是“t”。
接下来,我们试着把上面这种思路运用到一种极致。如果我们让这个模型不停地预估下面可能出现的单词,一直重复预估,会出现什么样的状况呢?那很可能这个模型就帮我们完成一篇完整的故事的创作了。
创作一篇故事作品
我们刚刚已经见识了猜测海明威小说中一个句子的下一个字母的方法和过程,那么接下来,我们不妨试着创作一个有海明威风格的完整的故事。
我们这里即将用到的是由 Andrej Karpathy 编写的递归神经网络实现。Andrej Karpathy 是一名来自斯坦福大学的深度学习研究人员,他曾经写了一篇非常优秀的关于运用递归神经网络进行创作的介绍,你能在 github 网站上找到所有关于这个模型的代码。
我们将根据海明威的《太阳依旧升起》这本书完整的内容来建造我们的预估模型。这篇作品中有 362239 个字词,共使用了 84 个特殊字符(其中包括了标点符号、大写字母和小写字母等等)。
这些数据与我们在现实世界中的典型的应用量相比,实际上已经是非常小的了。为了建立一个更贴近海明威创作风格的模型,我们最好能掌握比这个数据多数倍的示例文本。但是这些数据作为展示递归神经网络创作过程的例子已经足够了。
在递归神经网络模型的测试训练之初,它还并不擅长字母预测。下面是在 100 次迭代训练后,我们的创作模型输出的内容:

你会发现,这个时候它已经能够预测出有时候单词之间需要以空格间隔开,但是这还不足够完成一篇文章。
在大约 1000 次迭代之后,这个模型输出的内容看起来总算有些像样了:

这个模型开始能够识别出一些句子的基本结构模式了,比如在句子末尾加句号,甚至能够给对话添加引号。有少部分的话语是通顺、可以理解的了,但是仍然有一大部分句子看起来是非常荒谬可笑的废话。
但是经过更多次的反复训练,这个模型的输出结果看起来已经相当不错了:

到现在为止,我们所使用的这个算法已经成功掌握了海明威的短小、直接对话的模式,所以它生成的一小部分句子在内容上还算是说得通的。
然后,我们把这个创作模型输出的内容与书中实际的原文做个比较:
把字词一一对照来看,我们的算法也已经做到了文章内容的再现,而且内容看起来还十分可信,使用的格式也非常恰当。这已经相当了不起了。
同样的,我们还不需要完全通过打草稿来创作文章了,我们可以给算法提供文章前面的几个字母作为种子文本,然后让算法根据种子文本自动输出接下来的一些字母。
不妨用这个自动输出的系统来玩玩。我们试着给我们脑中幻想的书制作一个假的封面,用“Er”“He”“The S”作为种子文本,创造一个新的作者名字和新的书名。

图片的左边是真实的书,而右边是我们电脑生成的“无稽之谈”书。
至少看起来还不错!
但是最令人兴奋的地方是这个算法能够从任意的数据顺序中找出规律模式,这意味着它能轻易地生成看起来非常逼真的支票或者是假的奥巴马演讲稿。但是为什么仅被我们人类自己的语言所局限呢?我们可以把这个思路应用到任何一种有规律模式可循的顺序数据中。
在没有马里奥的情况下制作马里奥
2015 年,任天堂为 Wii U 游戏系统推出了“超级马里奥制造”。
能自己设计游戏关卡,大概是所有孩子的梦想吧!
这个游戏让你在游戏板上随意设计出你属于自己的“超级马里奥兄弟”关卡,然后上传到网上让你的朋友们玩你设计的游戏关卡。在你专属的“超级马里奥”关卡中,可以包含原始游戏里的经典的特殊道具和敌人。这就像为玩着“超级马里奥兄弟”长大的人们而设计的一个虚拟乐高。
我们能用前面那个假的海明威风格作品的创作模型来设计一个假的“超级马里奥兄弟”关卡吗?试一试无妨!
首先,我们需要一些用于模型测试训练的数据。那么就先用 1985 年发布的“超级马里奥兄弟”游戏的室外关卡作为训练数据吧。

这真是最棒的圣诞节了!谢谢爸爸妈妈!
这个游戏总共有 32 个关卡,其中大约有 70% 都是室外游戏的风格,所以我们将选择室外的这一部分。
为了得到每个关卡的设计,我找到了游戏的原始版本,然后写了一个程序将关卡设计从游戏记忆储蓄里抽出。“超级马里奥兄弟”是一个有着 30 年历史的经典游戏,所以网上有很多可以帮你找到关卡设计是如何储存在游戏记忆中的的资源。从一个视频游戏的经典中调出关卡设计数据是一次非常有趣的编程经历,你一定要试试!
下面是这个游戏的第一关,如果玩过的话你可能还有印象的。

“超级马里奥兄弟”第一关
仔细观察,我们会发现这个关卡其实就是由一些简单的网状方块对象构成的:

我们还可以简单地把这些方块对象一一用字符顺序来表示,一个字符代表一个对象:

如上图,我们现在已经把关卡中的每个对象用一个对应的字符表示好了:
空白格用“-”表示
实心砌砖用“=”表示
易碎砌砖用“#”表示
金币砌砖用“?”表示
按照上面的思路,把关卡内的每个不同的对象用一个对应的字符表示。
最后,我们就会的到一个像下图这样的文本文字档:
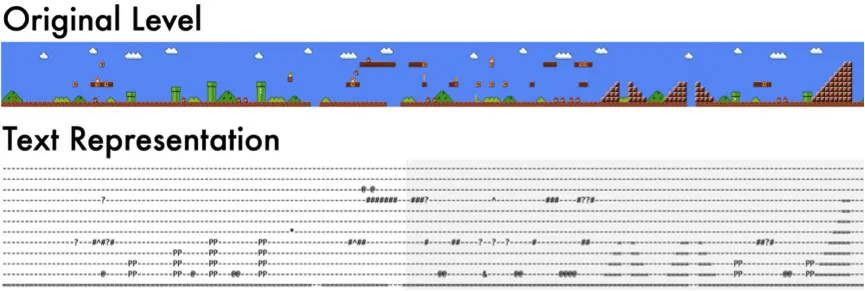
一行一行地观察这个文字档,你会发现这个“马里奥”关卡好像确实没有一个固定的模式或者规律:

一行一行地看,确实是找不到一个相对固定的模式或规律。甚至有很多行是完全空白的。
只有当你以一种“系列栏状”的思维来看这个关卡文字档文本的时候,你才会发现其中的规律和模式:

一列一列地看,它确实是有一个相对固定的模式的,比如说:每列都是以“=”结尾的。
所以,为了让算法能顺利找到我们数据里的规律和模式,我们需要以列的方式输入数据。找出能最有效地表现你的数据的方式(也被称作“特征选择”),是使用机器学习算法的关键点之一。
为了训练这个模型,我们需要把这个文字档文本旋转 90 度,这是为了确保字符是按照一种更容易显示其规律和模式的顺序输入模型的:

模型训练
正如我们前面“海明威散文风格”创作模型的创作经验,一个模型在不断的训练和测试中才能一步步趋于完善。
我们的模型在初期阶段只经过少量的训练,还没有完善,所以输出的内容完全不像样:
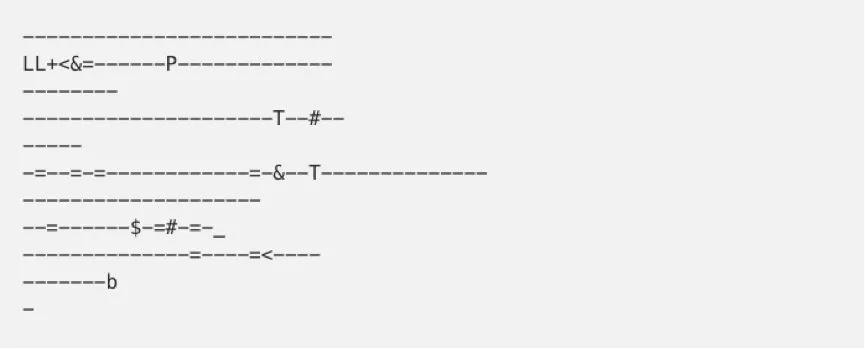
虽然它已经有了“-”和“=”两个符号所搭建的大概框架,但是还没有找到关卡设计的规律和模式。
经过上千次的反复试验和训练,这个模型的输出结果开始有了不错的雏形:

这个模型已经找到了每行字符的长度应该相同的这个规律,它甚至还找到了“马里奥”游戏关卡的小部分设计逻辑和规律:在“马里奥”游戏中“管道”这个物件通常是两个砌砖的宽度,高度至少是两个砌砖,所以“P”这个字母(P代表“管道”)在文本文字档中一般是显示为2*2 的群集。这个发现确实是相当酷的!
在经过更多次的训练以后,这个模型已经能根据关卡设计输出完全准确的对应字符数据了:

我们不妨用我们的模型来输出一整个关卡的字符数据,然后把它旋转回到水平状态:

大功告成!上面就是经由我们的模型输出的一整个游戏关卡。
这个字符数据看上去还不错!还有一些同样酷的事情值得关注:
- 跟原版的“马里奥”游戏一样,在这个游戏关卡的开头,它就把“快乐云”(游戏角色,是一个漂浮在云上的小怪兽)设置在空中了。
- 它能够知道管道是需要依附实心砌块才能浮在空中的。
- 它能按照正常逻辑来设置敌人的位置。
- 它不会设置任何会阻滞玩家前进的物件。
- 它带来的游戏体验与真实的第一代“超级马里奥兄弟”游戏是一样的,因为它就是以原版游戏里现存的关卡为基础设计的。
最后,拿着我们的关卡设计,用“超级马里奥制作”软件把游戏重新制作出来:

上图就是我们的关卡数据在被输入至“超级马里奥制作”以后的结果。
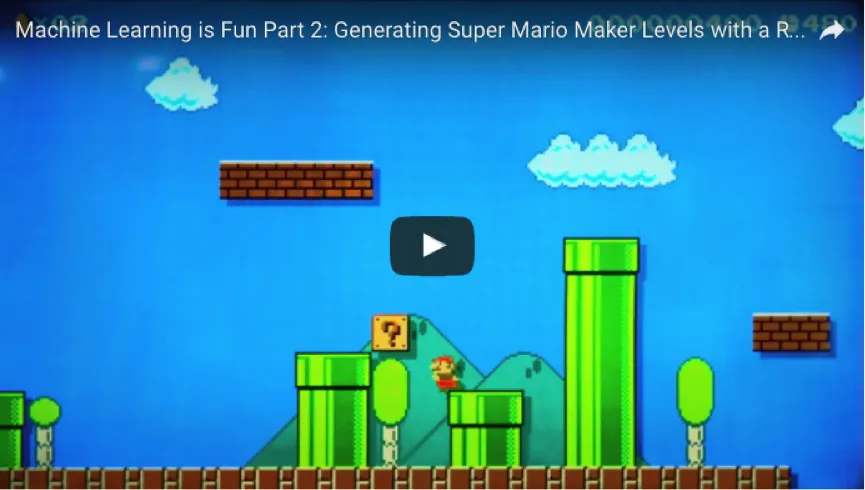
游戏制作好了,自己先玩玩吧!
如果你有“超级马里奥制作”这个应用程序,你就可以先把这个游戏关卡用网络书签收藏起来再玩;你也可以通过搜索游戏编码“4AC9–0000–0157-F3C3”来玩这个关卡。
玩具 vs 现实世界的应用程序
递归神经网络算法与现实世界的公司用于解决像语音探测、语言翻译等复杂的问题的算法是一样的。
我们的模型之所以更像一个“玩具”,而不是非常高端的存在,是因为我们的模型是由非常有限的、少量的数据中训练的,在原版的“超级马里奥兄弟”游戏中没有足够多的关卡来为我们的模型提供足够多的数据。
如果我们能像 Nintendo 一样有成千上万个游戏玩家设计的“超级马里奥制作”的游戏关卡,我们一定也能建立一个相当完美的模型。然而现实是,我们没法像 Nintendo 一样拥有这么多游戏关卡数据的,因为那些大公司是绝不会免费透露他们的数据信息的。
因为机器学习在越来越多的领域都发挥着非常越来越重要的作用,所以区分一个程序的好坏的标准就将变成你用于模型测试和训练的数据量的多少了。这也就是为什么像谷歌和 Facebook 这样的大公司那么迫切地需要你的个人信息。
举个例子来说:谷歌最近开源了 TensorFlow——一个用于建立大规模机器学习应用程序的软件工具包。谷歌这次将如此重要的、有能力的科技开源确实算是一个大举动,“谷歌翻译”等产品也是用这个框架实现的。
但是,如果没有谷歌在所有语言上庞大的数据支撑,你就不能与“谷歌翻译”相媲美的翻译软件。数据就是谷歌的高端所在。试想一下,下次当你打开“谷歌地图”里的历史位置记录或者是 Facebook 的历史位置记录时,你会发现它记录保存着你到过的所有地方。
深度阅读
在机器学习中,要解决一个问题通常没有一个标准的办法。在决定如何预先加工你的数据,或者决定使用哪个算法时,你会有无限的选择。通常来说,把各种不同的方法结合起来使用的结果比单个使用一种方法要好得多。
以下是一些读者发给我的链接,是关于设计“超级马里奥”关卡的一些其他有趣的方法的:
Amy K. Hoover 的团队用的方法能够一一表示游戏关卡中的每一种物件对象(管道、地面、平台等等),就像在一整个交响乐中单独表示每一种乐器的声音一样。
使用一种被称作“功能性搭建”的进程,系统能够用任何给定的对象类型的砌块自动增加关卡数量,比如说:你可以先草拟一个游戏关卡的基本框架,然后系统就能通过增加管道和障碍砌块来完善你的设计。
Steve Dahlskog 的团队像我们展示了,如果按照一系列n-gram 单词来建立游戏关卡数据的竖列模型,将更可能用比一个复杂的递归神经网络更简单的算法来输出游戏关卡。
【本文由「图普科技」编译,微信公众号「图普科技」(tuputech)】