
我们的祖先凝望星河闪耀,却花费万年时间才摸索出天体运行规律。
我们的前辈坐看潮涌潮平,却历经千秋万代才能航行到大洋彼岸。
而我们自己,在这片土地上繁衍至今,却仍旧对脚下的大地懵然无知。
从观察记录到规律预测,几乎是人类科学史的全部逻辑。但每次我们拼尽全力记下的数据,都只是抬高知识瀚海的涓涓细流。当我们提笔开始繁复演算的时候,期待的是阿基米德跳出浴缸、牛顿举起苹果的那一刻。
王伟涛博士正是这样计算的执笔人,他来自中国地震局。他想知道的,是我们脚下大地的每个细节。

【王伟涛】
浩如烟海的计算
我们经历的每一次地震,都在提醒自己预测和预警这种灾害的迫切性。但是,我们距离这个目标还很远。为更好的认识地震这一物理现象,需要极其的详细的地壳结构影像,而为了绘制这张地下地图,又需要详尽的数据计算。
目前为止人类打到地下最深的井是前苏联钻探的科拉超深井,约 12.2 公里,但是地震的震源深度往往在地下十几到几十公里,当前的科技根本无法在震源深度开展直接观测。
所以我们需要依靠分布在全国的数千个地震台来对地震波进行探测,震波在地下的传播特性,受到地质结构的影响,这也是地震波可以用来绘制地底图像的原理。这些地震台可以感知地震的“大震波”,也同样可以捕捉日常的“大地噪声”,例如海潮拍击大陆的震动。
王伟涛说。
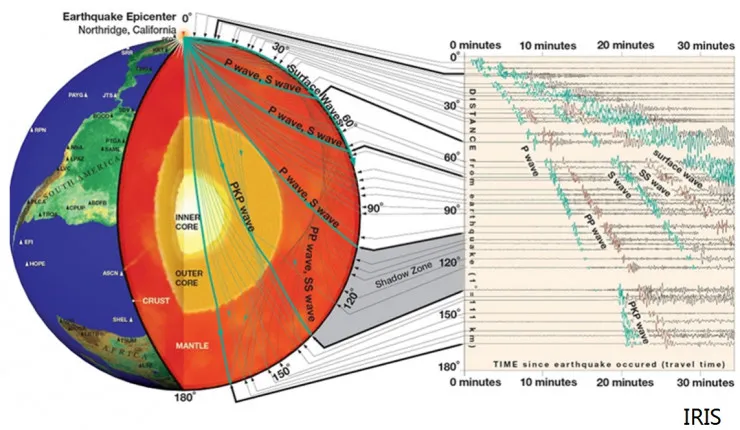
【根据地震波进行地底成像的原理/图片由王伟涛博士提供】
王伟涛告诉雷锋网,像他这样的地球物理科学家几乎都是半个程序员。因为从地震波到地底成像,中间要经过超越一般人想象的大规模程序计算。他的计算模型是这样的:
每一次震动都会由近至远依次传递到各个地震台,所以理论上来说,每个地震台都会对同一次震动做出自己的记录,这些数据既有差异有又联系。利用这些数据,可以计算出一些“虚拟地震”。用每两个地震台之间进行数据互相关对比计算,就可以获取研究中国地下的总体结构所需要的宝贵数据。
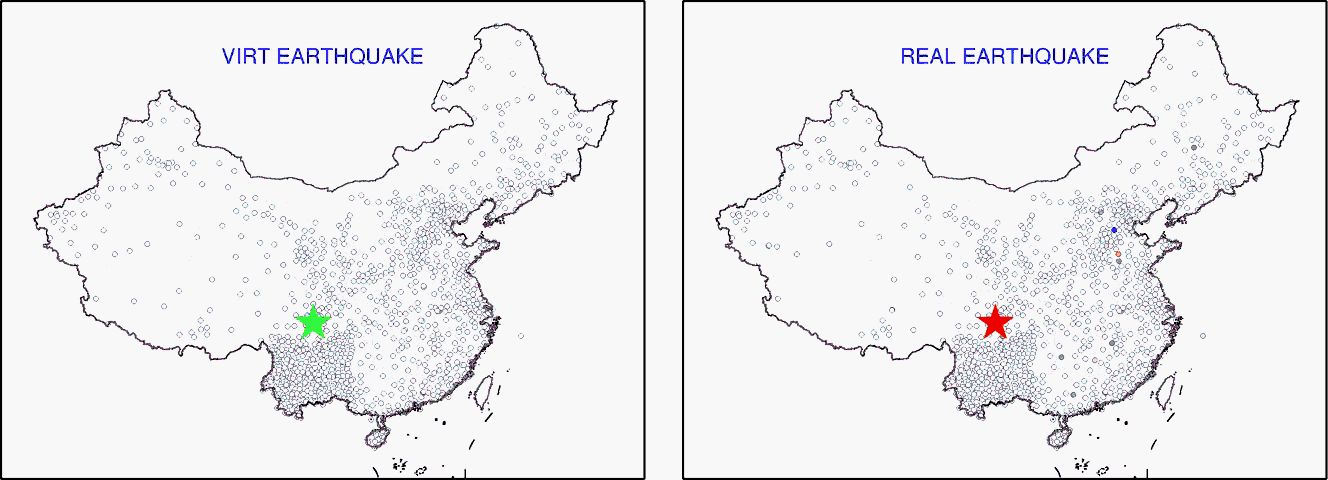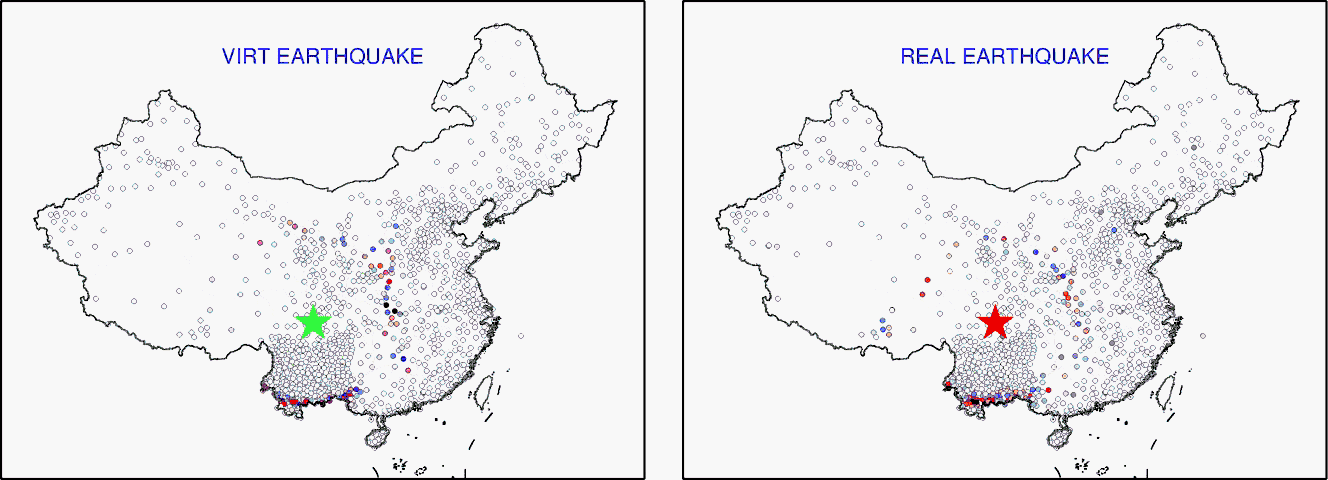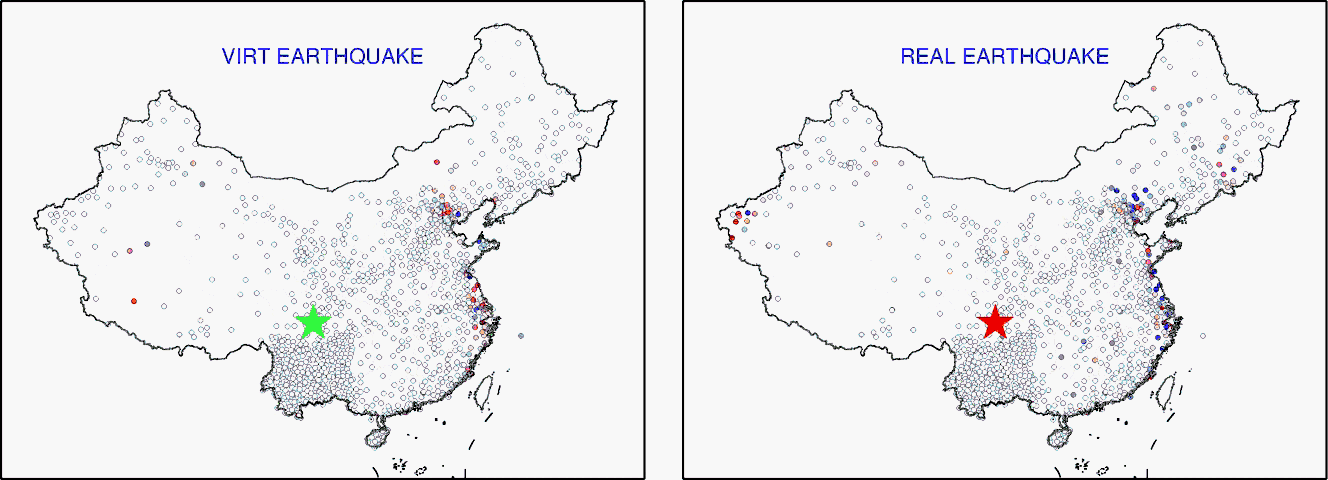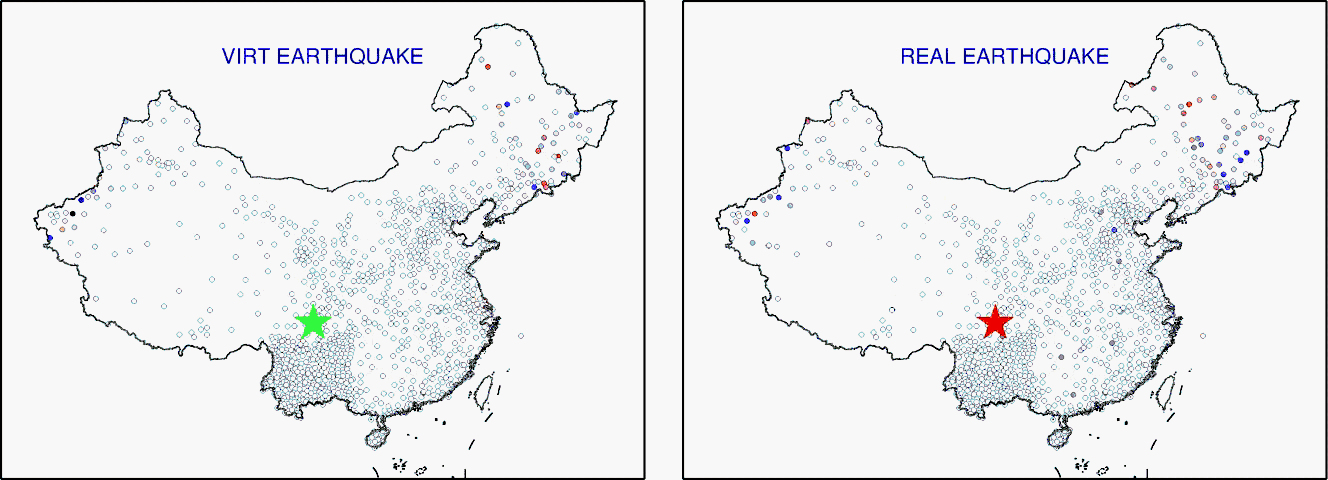
【虚拟地震可以模拟出和真实地震一样的数据,所以可以用于本来没有发生地震的地区的地底成像】
每个地震波数据都有 E,N,Z(东西,南北,垂直)三个向度的分量,全国 2000 多个永久和临时地震台就是 6000 个分量,每年的数据量大概是 30TB,而我们的总数据量已经到了 PB 级别。由于我们要相互对比每一个地震台每个时间点的每个分量数据,这些计算量是呈指数级增长的。
王伟涛的智慧和经验,恰恰表现在他所设计的程序和算法之上。但耗费很大心力完成这个算法的王伟涛博士发现,他才踏上了万里长征的第一步,还有一个巨大的困难横亘在面前。
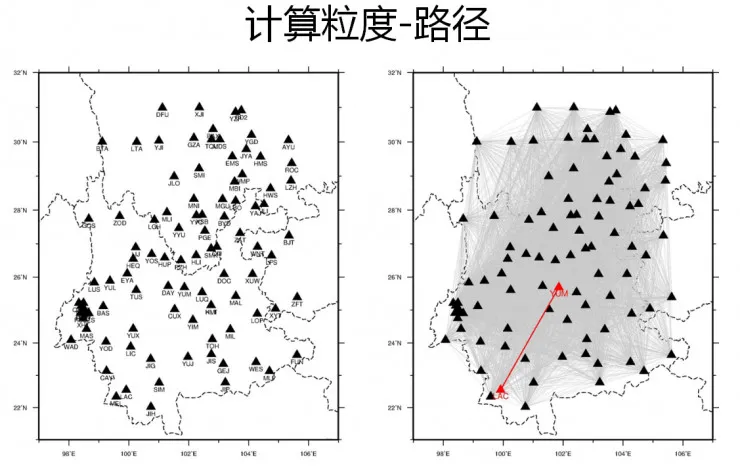
【图中每两个地震台之间的连线(灰色)都是需要计算的数据,总计算量极其庞大图片由王伟涛博士提供】
如果使用单机对这些数据进行计算,大概需要七年时间。按照一个人的职业生涯二十年计算的话,我在退休前只能完成三次计算。
在这种情况下,大规模分布式的云计算似乎成为了唯一的选择。然而,云计算的机理绝不像听起来这么轻盈。雷锋网也采访到了中国地震局的合作伙伴阿里云的童鞋们,在他们眼里,云计算和科学研究一样,集合了人类最顶尖的智慧。

【所需存储空间、计算量和预计单机计算所需的时间/数据由王伟涛博士提供】
分布式存储:有关农场的游戏
“云存储就像一个大的农场,每个服务器就像一个工人,而你的数据就是羊。”
阿里云存储高级专家承宗说。看来他是个牧场达人。
“分布式存储”,可以看作分布式计算的基础条件。也就是说,你的羊要先放进阿里云的“农场”,它的工人才会帮你照料、喂养、剪毛、纺线。对于王伟涛博士的数据来说,仅仅是存储在云端,就需要无数“黑科技”。
在将要进行的计算中,计算系统会对存储系统进行大规模的访问。而这些访问必须要平均地打到服务器上,绝不能存在热点。
而这还不够,由于服务器的硬件故障在大规模集群中会变成一个常态事件,所以必须做好资源的实时调度和提供故障容忍能力。例如保证在摘掉一块硬盘的时候,其余的硬盘要迅速用备份数据把存储追齐。
承宗举了以上两个例子。这两个例子换成农场的比喻,大概是如下表述:
农场对于工人的工作量要平均分配,绝不能出现“对着一个羊薅羊毛”的情况发生。
另外,农场每天都有工人病倒、请假,要在最短的时间把他的工作合理分配给很多人,这样别的工人也不至于负荷过大。
整个阿里云的分布式文件系统,被命名为盘古。在承宗心里,盘古还有很多智能化的“黑科技”。他举例了一个例子:
我们人类看到的磁盘都一样,但是盘古看到的磁盘各不相同。它会根据历史访问数据的积累,例如写入的速度和效率,对每一块磁盘的健康度进行打分。对于健康状况不好的磁盘,就相应减轻一些工作分配。这些底层的技术,都可以为王伟涛博士下一步真正的计算做准备。
承宗说,在分布式计算中,数据带宽成为了一个重要的参数。从王伟涛博士的角度来看,如果把数据存储在自己的服务器上,仅仅利用阿里云的计算能力进行结果输出,是不能实现的。原理很简单,分布式计算的所有服务器都向一个存储单位发送数据读取请求,带宽会被瞬间堵死,再强大的算力都无法发挥。
至于具体数据,百兆光纤的带宽一般是 100Mb/s,而硬盘的带宽最高可达几 Gb/s,而阿里云存储内网访问带宽(云计算系统内部)可以高达 Tb/s级别。
批量计算:建造一座金字塔
接下来,王伟涛博士的数据就会进入最终计算的环节。
我熟悉了自己习惯的 Linux 系统,所有的计算代码都是在这个环境中完成的,如何让我的代码在云计算的环境中发挥作用,是一个很重要的问题。
王伟涛说。
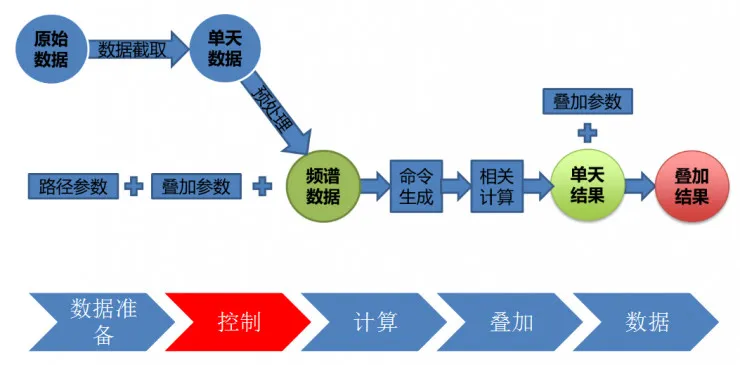
【王伟涛博士地底成像数据的计算流程】
在地震科学研究方面,阿里云显然没办法提出算法建议,所以他们需要做的是,提供一个通用的接口,让王伟涛可以使用自己机房中的电脑、界面和 Linux 系统,来对云上的计算进行控制。
阿里云提供的兼容和适配能力,是阿里计算专家林河山颇为骄傲的地方。
王博士在此之前没有使用过分布式集群,也没有使用过“超算”,所以直接跨越到云上,从操作和控制层面来说,对他来说会是个挑战。我们提供的计算接口可以让单机程序不做修改就高效执行在云环境下。用户通过几句简单的命令就能在云上调动大规模的计算资源进行分析,而不需要学习复杂的分布式计算知识。
其实很多从其他地方过渡到云计算的人都会有这样的问题,所以不仅是王博士,很多其他用户也会用到我们的通用计算接口。
他说。
这个时候,大规模计算的障碍基本被扫清了。不过,林河山告诉雷锋网,云计算真正的核心技术,还在于批量计算的算力调度之上。
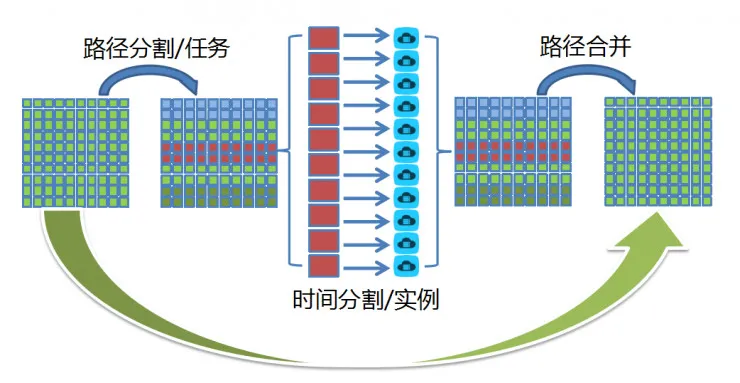
【大规模计算的加速流程和模式】
计算规模扩大之后,就会造成对存储资源的访问非常频繁,这时,对于访问的并发量的控制就要非常“小心”了。
王博士的应用有非常多的小I/O请求,如果每一次I/O请求都直接访问云存储,由此带来的延时会对计算效率造成影响。为了进一步优化计算性能,批量计算采取了“分布式缓存”的策略,把有可能会用到的数据,提前缓存到计算节点周围。这样,就可以让计算能力不受集群规模的限制。
林河山说。
而即使是这样,还远远不够,对于数据访问究竟采取多大“粒度”,是考验系统智能的重要时刻。如果一次读取过多,可能造成带宽拥堵,如果一次读取过少,又会造成频繁访问。而针对不同类型的数据,都要做出合理的预判,自动地读取,是一项艰巨的任务。
打个比方:
这如同建造一座金字塔,数万名“奴隶”要分工合作。工程师要决定:是牺牲速度一次性运输多个石块到现场,还是牺牲数量,一次快速运输一块石头到现场。
同样,面对浩瀚的金字塔工程,每时每刻要分配多少奴隶来搅拌砂浆,分配多少奴隶来搬运石块,分别分配多少奴隶来负责建造各个区块,这个即使是工程师都需要仔细考量才能完成的任务,都要交给系统自动完成,难度可想而知。

当然,如此繁复的计算过程,出错是经常会发生的。林河山举了一个例子:
在渲染追光动画的动画片《小门神》时,阿里云的容错机制就发挥了作用。(当时在峰值有 2000 台服务器参与了大规模批量计算。)
一般情况下, 对于视频的渲染工作是一个连续的长流程。如果某一帧渲染中哪怕只有一个节点出问题,都会造成访问的大规模延时,造成逻辑上的拥堵,产生“热点”。
林河山说:“阿里云的做法是,在计算出错之后,在最短的时间内重跑,如果在跑的过程中确认节点存在问题,还会自动调度到另一个地方,这些对于用户来说都是没有感知的,但是在背后,我们必须做出大量的努力。
绘制地下的世界
原本需要一年计算时间的整个中国数千个地震台两两之间的五年数据的计算任务,在云计算中狂飙,48 小时之内就计算完成了。
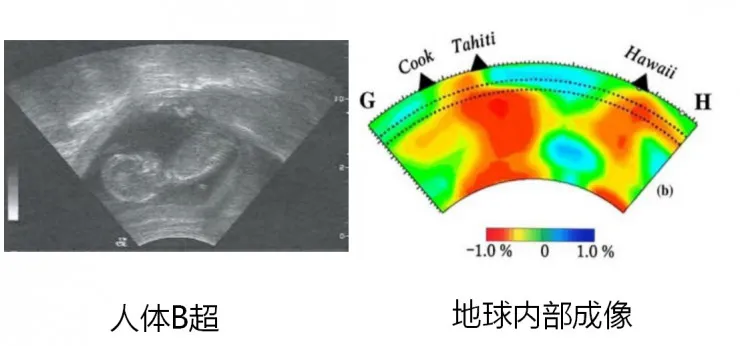
【地球内部成像,恰似人体的B超】
这在云计算时代来临以前是无法想象的。
从科学研究的角度来看,这些数据是原始的地震观测数据的数据产品,同时也是后续科学研究所依赖的重要数据,可以很好地支撑王伟涛进行接下来的研究。从外界看来计算过程非常顺利,而刚才我们所感受的一切艰辛,都只发生在背后的代码世界。
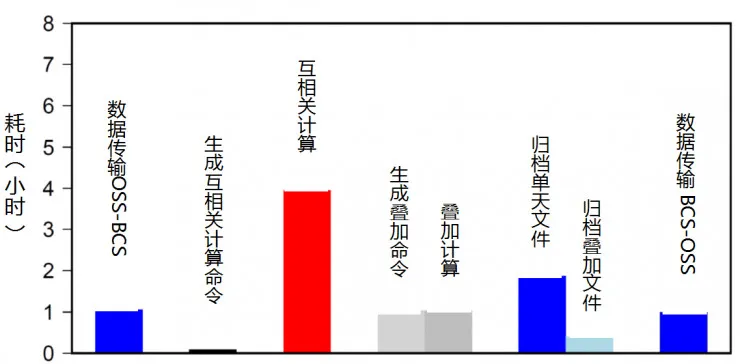
【各个步骤耗时统计/图片由王伟涛博士提供】
借用阿里云产品总监李津的话:
当计算结果输出的时候,我们所有的技术人员都沉默了。我们多么渴望这样的数据早几十年被计算出来,这样我们就能为人类认识地震这一自然灾害争取宝贵的时间。
抛开商业的云雾,可以看到云计算真正的的锋利所在。
王伟涛的研究并没有停止,他说:
目前为止,我只做了 2011 年到 2015 年的一个向度上的数据分析,未来还会继续把更多向度和频率上的数据进行计算。科学研究的精确度是可以一直提高的。越来越精确的地底数据,会为矿产勘探、防震减灾和地震科学研究提供非常强的支持。
科学的有趣之处,正是在于不断地尝试。有可能一觉醒来想到新的方法,就要重新改写公式和代码,通过计算进行验证。
也许有一天,属于王伟涛的那只苹果会悄然落下。那一刻,是王伟涛的胜利,也同样是人类计算力的胜利。
我们倾尽全力提高算力,把数据的涓涓细流汇聚成洪荒之力,只是因为我们不愿对脚下的大地懵然无知。
