
越来越多人加入数据科学这个行列,而数据科学家离不开算法的使用,因此出现数据科学家们最常用的一些算法。今天我们小编根据 KDnuggets 调查,带大家看看这 5 年时间(2011 年-2016 年),到底哪 10 个算法深受数据科学家们的喜爱呢?

2016 年数据科学家最常使用的十大算法,它们分别是:
1. Regression 回归算法
2. Clustering 聚类算法
3. Decision Trees/Rules 决策树
4. Visualization 可视化
5. k-Nearest Neighbor 邻近算法
6. PCA (Principal Component Analysis) 主成分分析算法
7. Statistics 统计算法
8. Random Forests 随机森林算法
9. Time series/Sequence 时间序列
10. Text Mining 文本挖掘

从上图调查中,我们不难看出这五年,数据科学家们对回归算法、聚类算法、决策树和可视化这四个情有独钟,依然占据前四位;不过这期间也有些算法上升特别快,虽然有的未能挤进前十名,但是值得关注, 比如 Boosting,从 2011 年的 23.5% 至 2016 年的 32.8%,同比增长 40%;异常/偏差检测,从 2011 年的 16.4% 至 2016 年的 19.5%,同比增长 19% 等;有升必有降,而 2016 年下降比较明显的算法分别是关联规则 ,从 2011 年的 28.6% 至 2016 年的 15.3%,同比下降 47%;增量模型 ,从 2011 年的 4.8% 至 2016 年的 3.1%,同比下降 36%,因素分析 ,从 2011 年的 18.6% 至 2016 年的 14.2%,同比下降 24%。
不同领域使用算法的比例情况
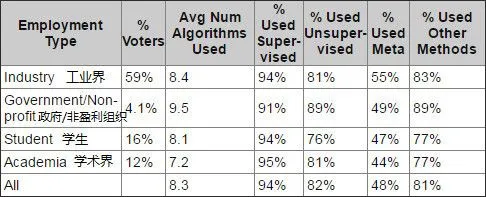
算法不断涌现,但好不好用,需要时间和数据科学家们的实践,不过,众多受访者也表示多使用算法,了解各种算法,从调查中得出数据科学家们平均使用了 8.1 个算法。因此,多掌握些算法,协同使用可能更利于成长。