
本文作者是王昊奋,Apex 数据与知识管理实验室语义组负责人,曾主持并参与了多项相关项目的研发,长期与 IBM、百度等知名 IT 企业进行合作,在知识图谱相关的研究领域积累了丰富的经验。
也许你并不是很了解知识图谱,但是你一定知道石油。石油不仅仅是能源,很多衍生品也都需要依赖石油。
而类似地,在进行人工智能的探索道路上,我们也需要了解其本质,或者在其基础上衍生出各种上层的智能应用。在我个人看来,知识图谱正是起到了这样一个作用。
本文主要是站在一个中立的角度尽量给大家呈现知识图谱在各领域的应用。
基于知识图谱的应用
Google 的两大重要技术储备,一个是深度学习,形成了 Google 大脑;另一个就是知识图谱(2012 年提出),用来支撑下一代搜索和在线广告业务。
有些我们耳熟能详的应用其实是基于知识图谱的,比如“语义搜索”。
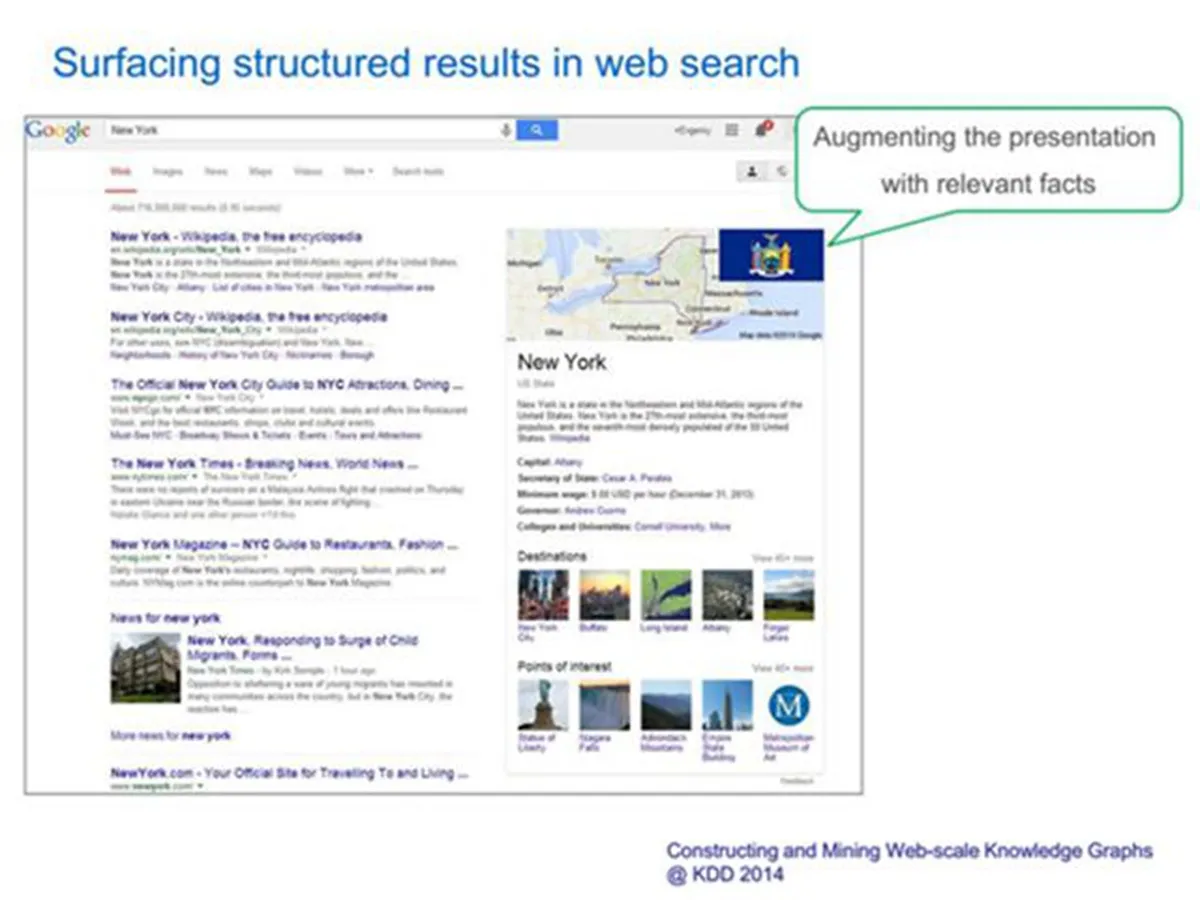
上面的图中,大家可以发现与传统的搜索相比,搜索引擎开始理解用户输入的需求了,并对此返回各种非网页内容信息。
在图中,对于 New York(纽约州),返回各种结构化信息(在右边),类似一种经过梳理的高质量的摘要,供大家快速了解,而非仅有包含 New York 作为关键词的文档内容。
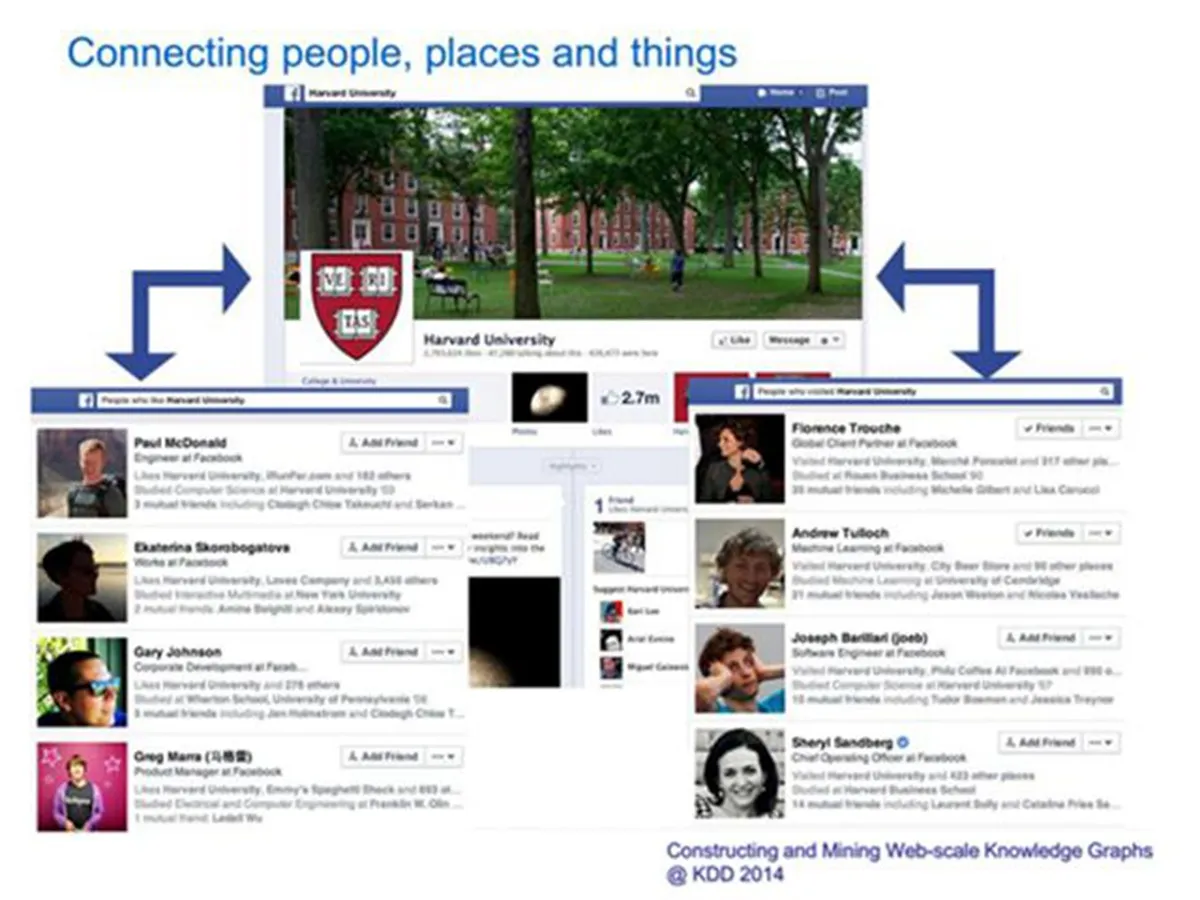
接着我们再来看另一个巨头 Facebook 公司的工作,他在之后利用知识图谱技术构建兴趣图谱(interest graph),用来连接人、分享的信息等,并基于此构建了 graph search。
通过上图可以看到用户输入的两个自然语言问题,一个是问喜欢哈佛大学的人(左边),另一个访问过哈佛大学的人,如果按照传统的搜索做法,返回的结果会有很多重合,而事实上从返回结果我们可以看到 Facebook 公司可以清晰分辨这两者的区别。
那么这里就需要做更精确的语义分析,对于这里可以识别 people(询问对象)、Harford University(大学),like/visit 是动作,而 like 可以对应到社交网站中的点赞,而 visit 对应到社交网站上的签到,这样就能完全区分开了,更进一步,我们有了各种允许语音输入的个人助理。
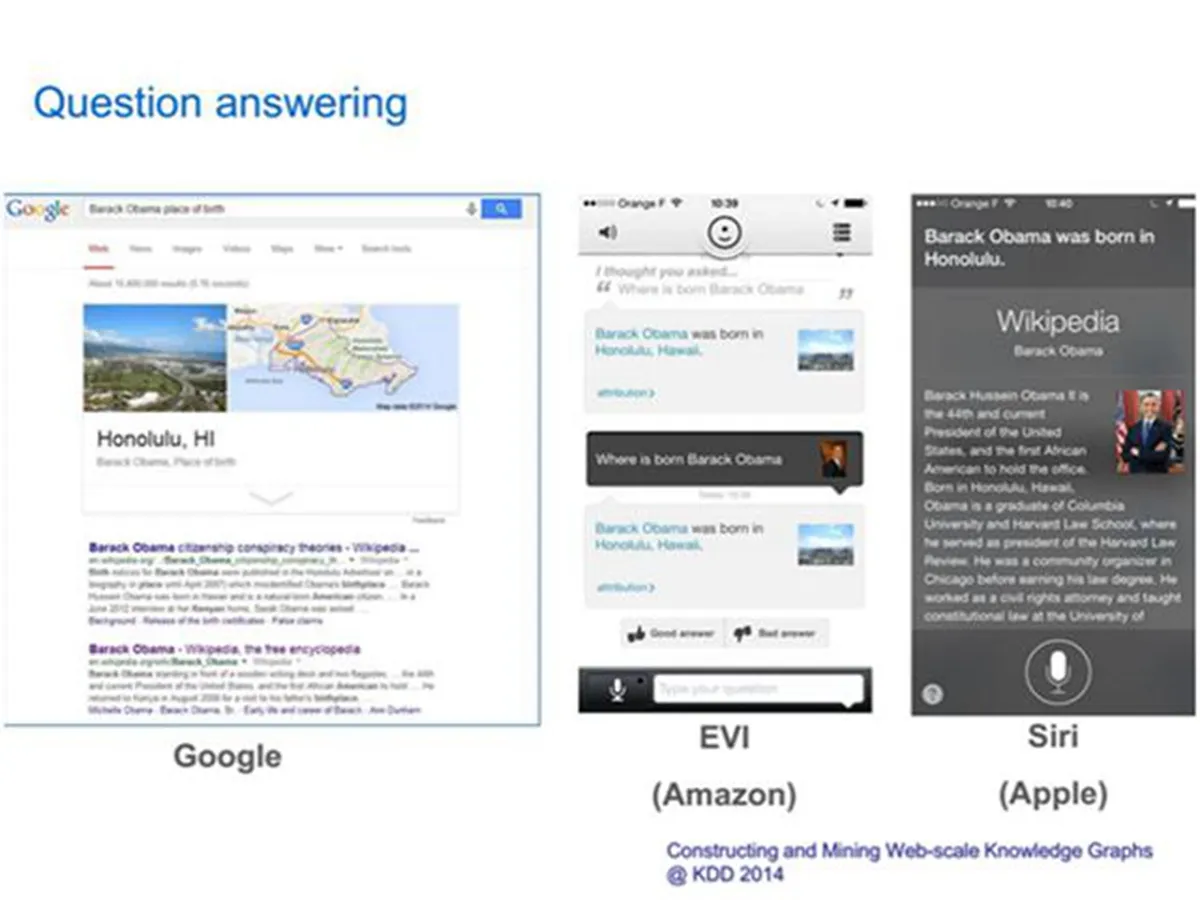
从 Siri 到 Evi 到 Google Now,这些仅仅是在交互方式上有所不同,支持自然语言自由沟通的前提是庞大的知识库和基于知识库的各种服务—即知识图谱,此外,大家都知道 IBM 近年来一直在推动认知智能和智慧地球的理念。
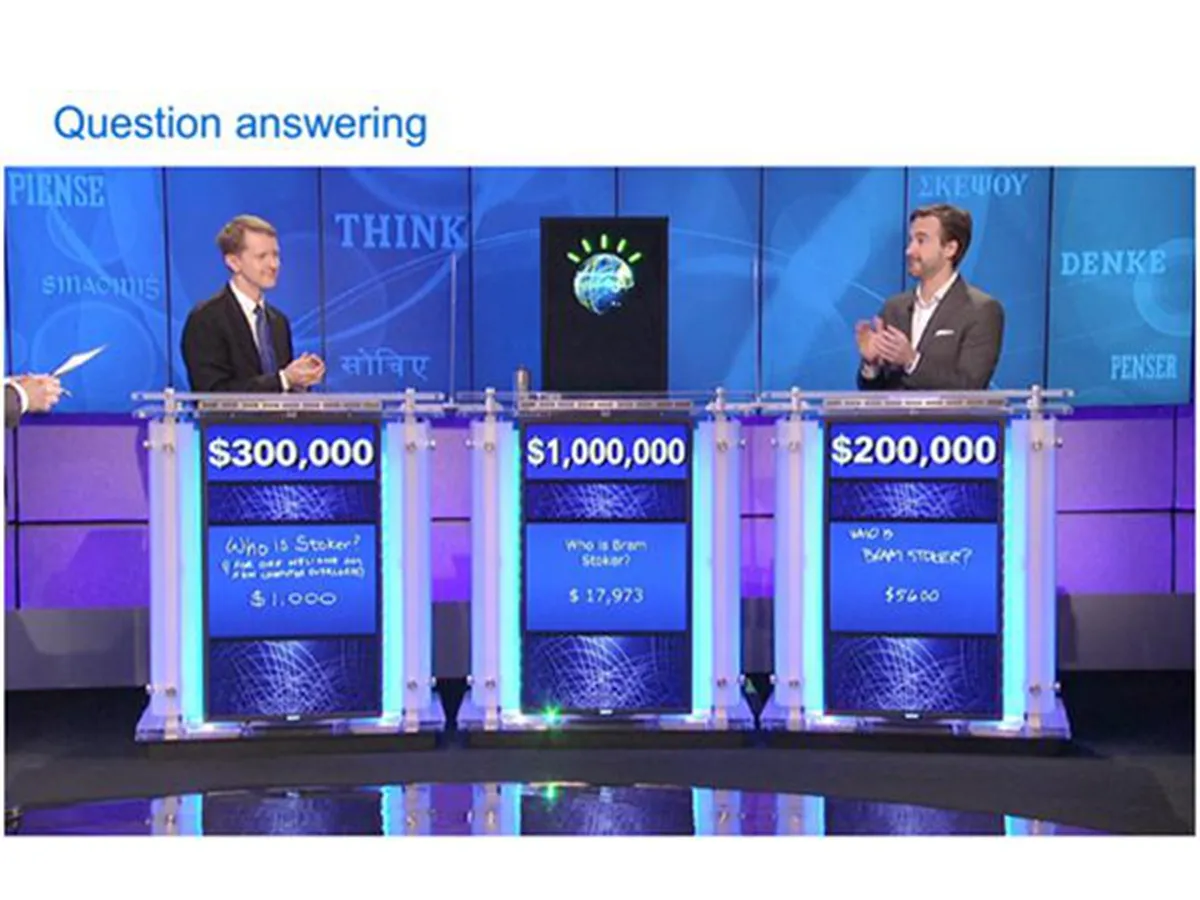
IBM 在 2011 年研发了 Watson 问答系统,参加了 Jeopardy!(危险边缘)电视节目,类似国内的一站到底和开心词典,并打败人类冠军。
很有幸,我参与了 2 年的 Watson 系统研发,这对后面的经历以及目前公司的技术选型有比较大的影响,刚刚举了一些例子,我们总结一下知识图谱会带来的好处。
这对于大数据来说,其实就是全数据的概念。而对于人工智能来说,其实就是将原本没有联系的数据连通,将离散的数据整合在一起,从而提供更有价值的决策支持。
而“知识图谱面面观”在这里其实更进一步针对 B 端市场,强调了外部数据和内部数据整合的意义和价值。
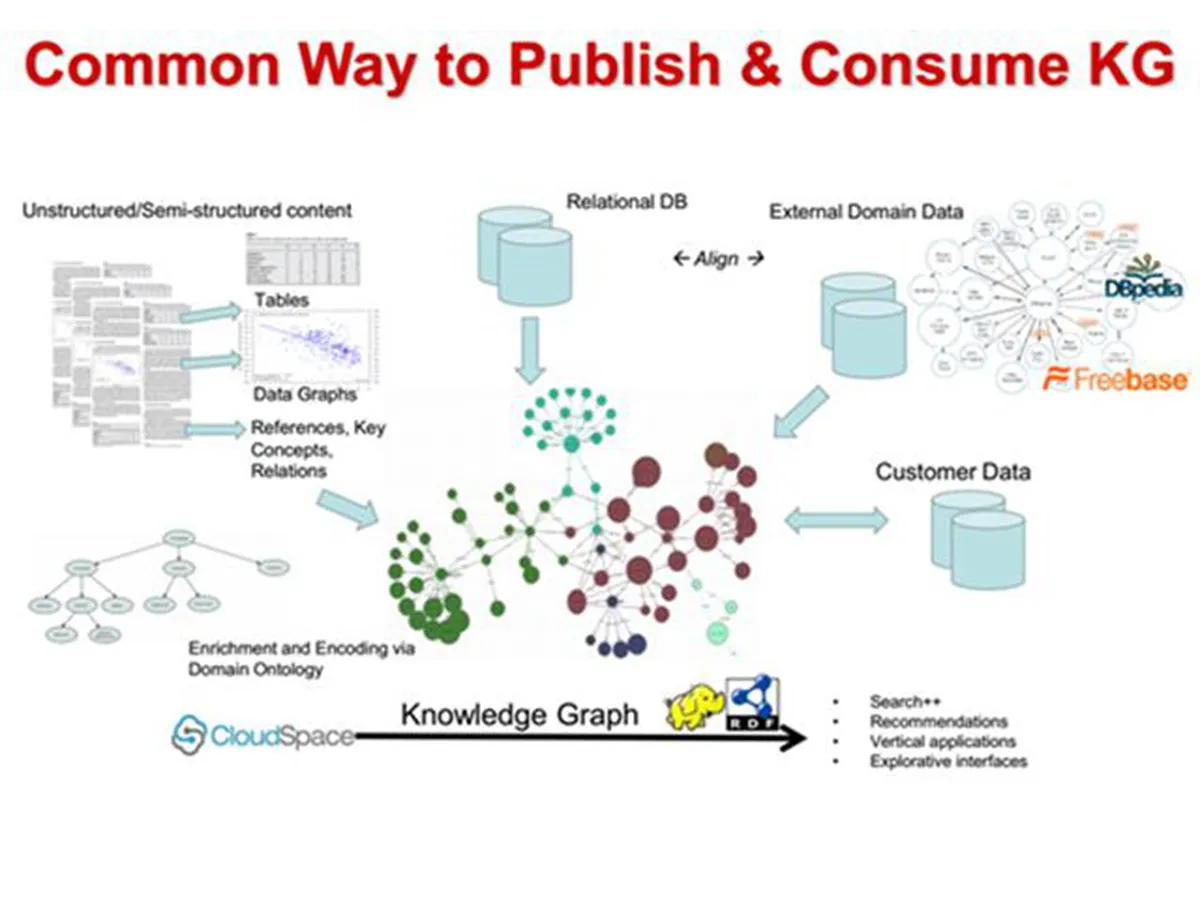
这是一个通用的知识图谱的框架,我们可以看到知识图谱不是空中楼阁,而是基于现有数据的再加工,包括关系数据库中的结构化数据、文本或 XML 中的非结构化或半结构化数据、客户数据、领域本体知识以及外部知识,通过各种数据挖掘、信息抽取和知识融合技术形成一个统一的全局的知识库。
注意这里的全局知识库并非中心管理,而是一个逻辑上的全局(即数据统一,语义清晰),那么知识图谱能做什么呢?也就是上面提到的那些大家熟悉的应用(搜索、推荐、以及在后面会提到的各种垂直应用)。
知识图谱在生命科学中的应用
第一个应用是药物发现:
大家都知道,医药公司往往花费 10 亿美元甚至更高来研发新药,如何缩短新药研制周期,降低研发成本是大家所关注的。

这里首先大家可以了解一下欧盟第 7 框架下的一个重大项目,称之为开放药品平台 Open Phacts,这个项目吸引了辉瑞和诺华制药等巨头参与。
利用来自实验室的理化数据、各种期刊文献中的研究成果、以及各种开放数据(其中比较有名的包括 Clinical Trials.org,美国开放数据中的临床实验数据)来加速药物研制中的分子筛选工作。
具体来说,我们看一个例子:

大家都知道,阿尔兹海默症也就是老年痴呆症是世界难题。
这里给出了 3 个观察:药物研发经常需要去找药物靶点,而药物靶点中大家关注的是其中丰富的信号转导通路,更具体来说即对于化学治疗起作用的蛋白。同时我们知道老年痴呆症患者的 CA1 锥形神经元是损坏的。
那么我们在做基因筛选的时候就会发问:能否找到存在于上述信号转导通路中,且被包含在上述神经元的候选基因呢?

更具体来说,我们将其转换为一个复杂的查询,大家不用纠结这个查询的格式,这是一个图查询,是图谱对应的标准格式,称为 SPARQL。这个查询一共跨越了 4 个数据源,锥形神经元在 Mesh(美国 NIH 发布的标准术语)中 Entrez Gene 是一个知名的基因知识库。
而 GO (基因本体)包含信号转导,同时可以在图中看到有两个橙色部分的查询,需要依赖去做知识推理。知识推理就是希望通过逻辑和统计的方法从显式的数据中得到隐含的知识。
比如这里,是要做一个传递闭包的推理,因为 part of (部分)是一个可以传递的,A part of B, B part of C 可以推出 A part of C。这样得到的候选基因能让医学研究人员更加专注,省去了大量用机器(即使是华大基因)去筛选基因的耗费。
刚刚我们也提到了 Watson,随着 Watson 取得巨大成功,IBM 成立了 Watson group(事业部),对各种行业进行认知攻破。
第一个就是医疗方面
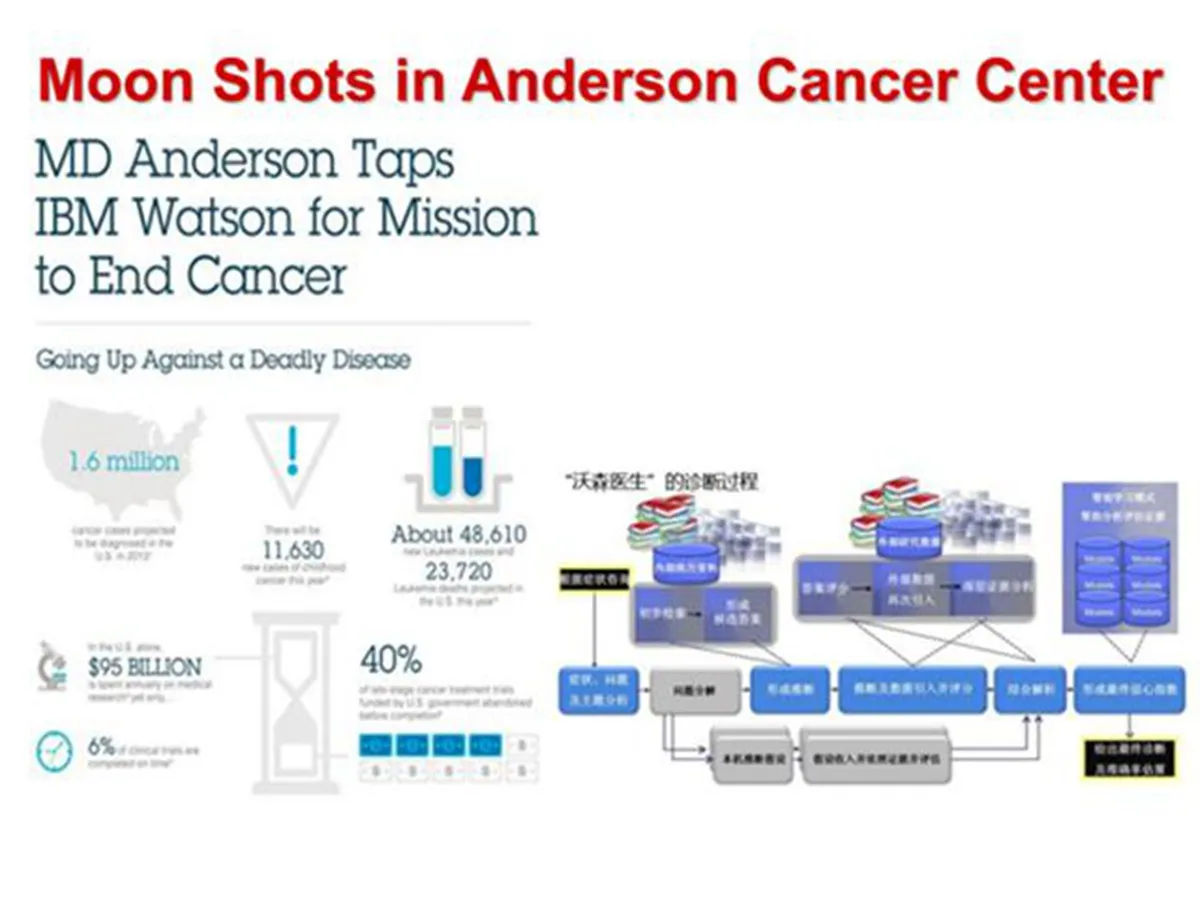
这是在安德森癌症中心的实验,我们知道 Anderson 癌症中心是全世界最有名的癌症中心之一。
IBM 称这个项目为登月计划(moon shot) ,这里通过整合大量医疗文献和书籍以及各种 EMR(电子病历)来获取海量高质量的医疗知识,并基于这些知识面对医护人员提供辅助临床决策和用药安全等方面的应用,并取得了巨大成功。
知识图谱在农业中的应用
大家都知道我国是农业大国,但是我们的农业又是基于小作坊,靠手工或看天工作的阶段。

当然整个亚洲其实和美国这种大农场主统一管理的方式很不同,也存在各种资源利用率低的现状,我们发现有超过 50% 存在农药过分灌溉或缺乏灌溉的情况。
大量的资料是很分散的,而且存放在各种格式中,而农民们非常迫切希望有人来指导他们更好地进行灌溉和解决虫害,那么这个时候的关键就是使得各种农业相关的知识可被这些农民朋友访问到。
这里我们以柑橘知识为例,我们发现传统的关系数据库模式对于这种复杂或多变的领域是不可行的,因为我们无法实现定义所有可能的知识点(用于构建关键数据库模式)。所以我们需要一种更加灵活的知识表示模型来管理,这个时候知识图谱就能起到很好的作用。
如果大家对知识图谱还比较陌生的话,可以看到这里贴出的可视化图,即根据上述施肥问答信息抽取构建的图谱片段。
类似的,我们可以用各种抽取挖掘技术(这里省略)从各种多源异构数据中获取相应的知识,并统一用图谱进行表示,从而形成一个完整的知识库。
这里以 Excel 表或 CSV 文件为例,我们可以通过构建 wrapper 将其列映射为图模式,而将下面的记录(每一行)映射为对应的符合模式的图数据,并与之前从问答知识数据中获取的图谱进行关联整合。
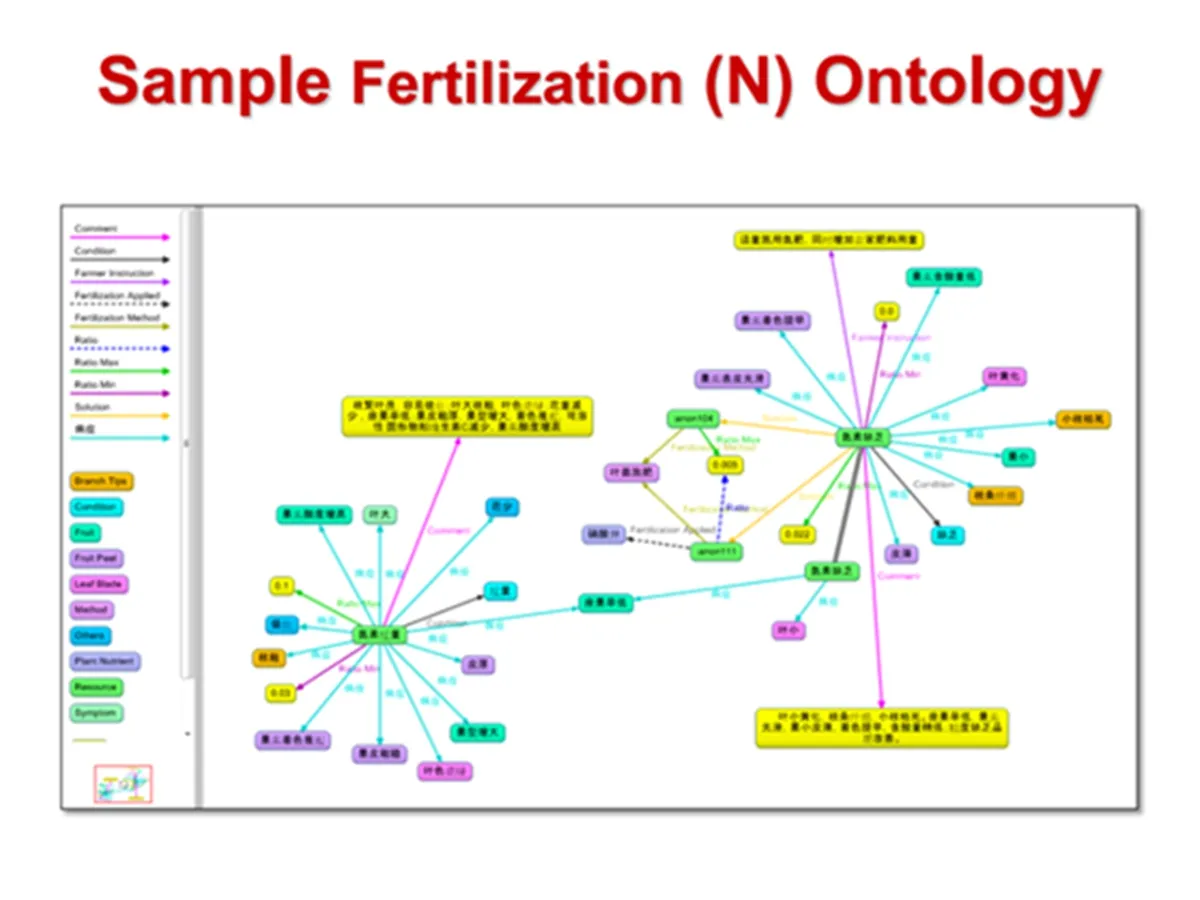
这是一个整合之后的化肥本体知识。
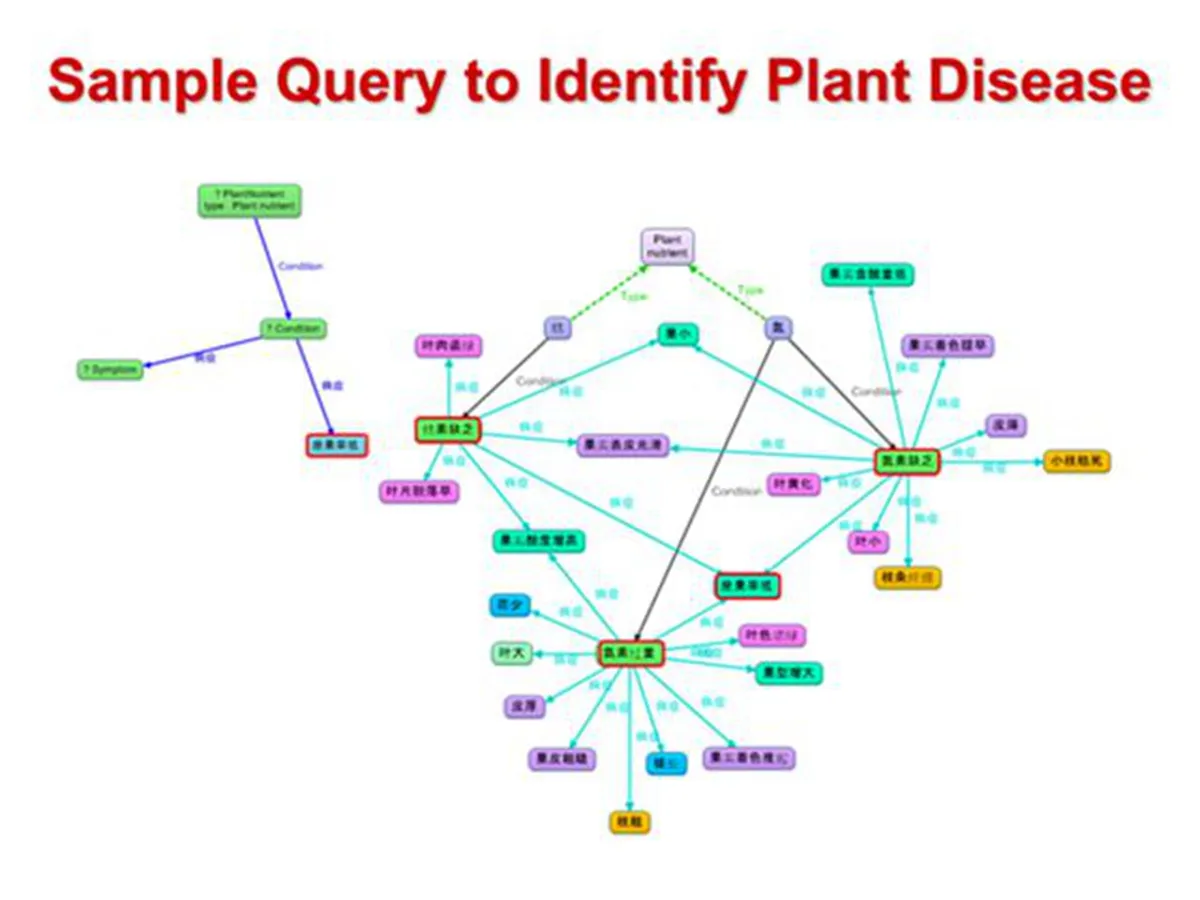
对于这个知识库,我们可以通过 SPARQL 查询(可以可视化为图谱,见左上脚)来利用知识库,这里的例子是查询症状是座果率低的植物和其他相关症状。
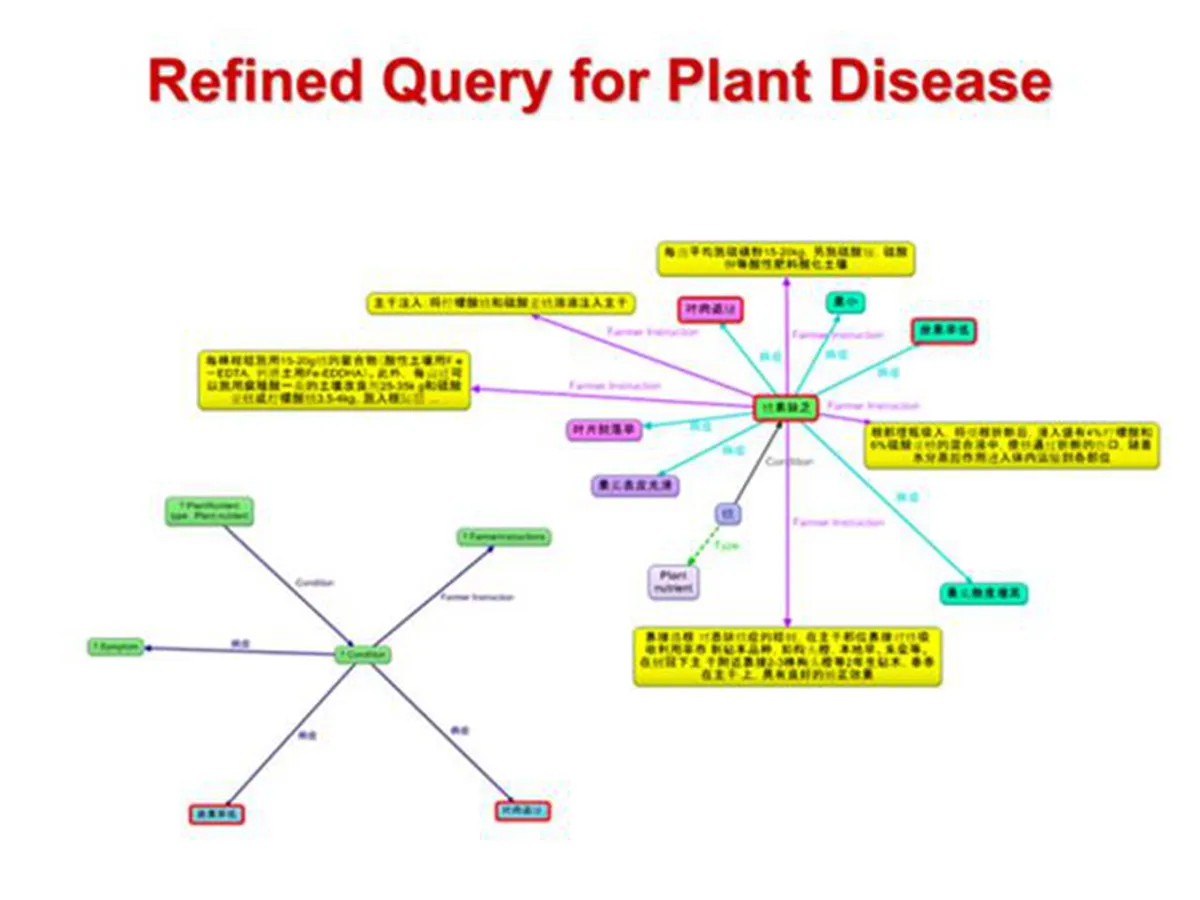
图查询类似图谱数据,非常灵活,可以方便地进行变化,通过增删节点和边来实现,从而增加条件或放松条件。
这是一个完整的例子,即缺乏氮素的植物以及植物灌溉知识。通过例子可以看出,我们可以通过图谱关联到图片信息,这样形成了多媒体知识图谱,而这些病变的图片信息相比专业知识更加直观,也更方便农民使用。
这里总结了,在农业方面知识的影响和作用,我们可以刻画作物知识、土壤、肥料知识、疾病知识和天气知识等。

通过知识图谱,我们可以将传统的农业转换为精准农业( precision agriculture )。
知识图谱在电信行业客服中的应用
Amdocs 是美国最大的第三方账单审计和客服中心,AT&T, Verizon 和 Sprint 等都是他的客户,美国的电信市场很早就饱和了,所以各大运营商均没有很多新客户可以争取,那么维护好老客户就非常重要。

这是一个案例,大家有时间看看,其原则就是希望对于信用好的用户能前瞻性地了解他的需求,并在他打电话来反映情况的时候(抱怨或询问信息等),可以预先判断他需要什么,并帮其解决,从而减少沟通次数和沟通时长。
为了做到这一点,系统需要判断用户的信用等级。并根据用户的当前消费情况和各种动作来自动化判断其可能的行为。
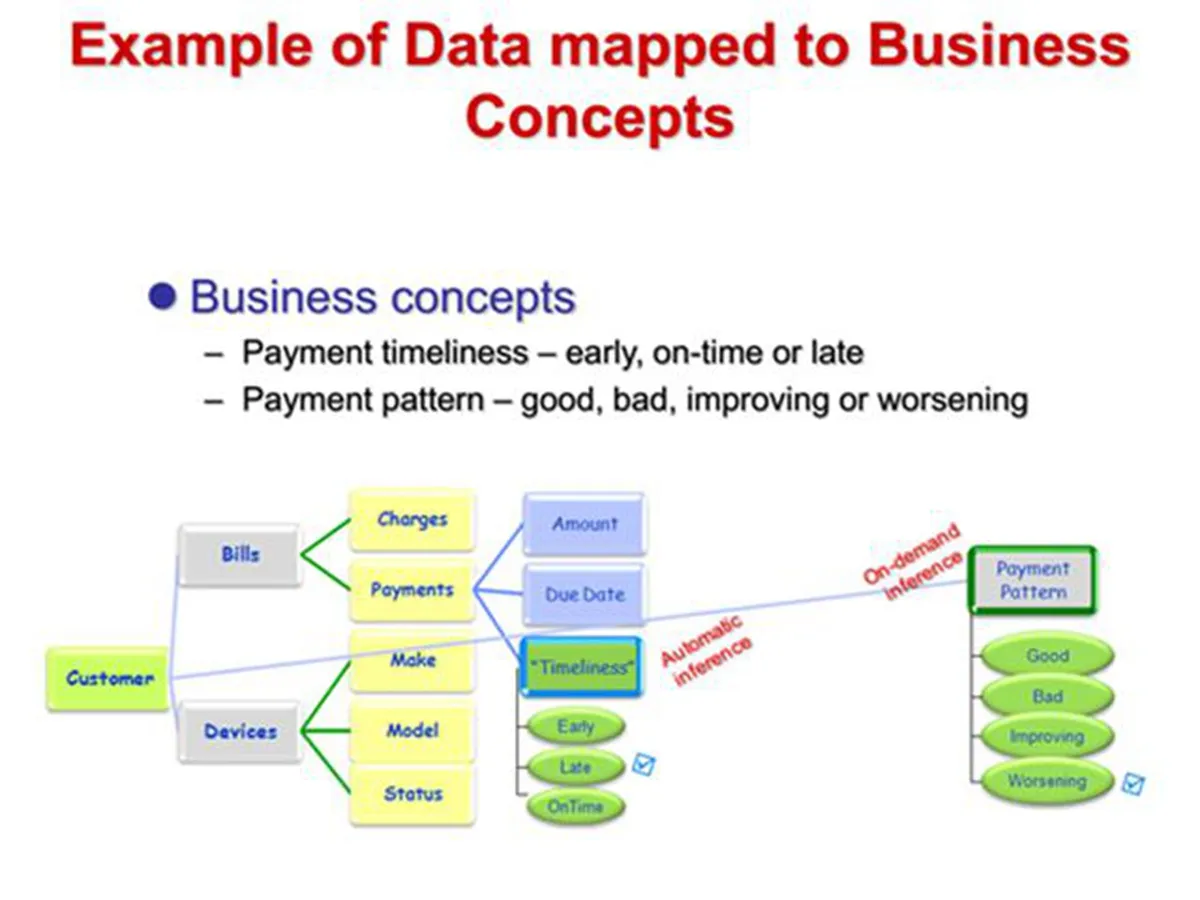
这是一个简单的电信行业使用的数据分类和商业概念归类,包含设备、账单、支付等一系列重要知识。
这个图展示了通过上述概念得到的各种数据包括结构化,也包括流数据进行的各种数据映射和转换,类似的,也是形成统一的图谱进行管理。这个还包括趋势、时间、地理还有消费模式等很多信息。
这是所使用的架构图,从中大家可以看到会通过各种数据源进行数据的整合,形成统一的知识,并配合业务规则和贝叶斯网络来形成决策引擎,从而对用户的信用和各种行为结果预测起到作用。
最终达到的效果就是个性化前瞻性的客户关怀。
知识图谱在媒体发布中的应用
最早使用知识图谱的是英国广播电台,之前传得很火的新闻自动写作机器人也利用了知识图谱。
举个例子,这是针对 2012 年伦敦奥运会的。大家可以看到有很多个圈,每个圈代表一种对象,这些对象的跟踪报道由专人负责,然后通过这样的图谱将各种零散的信息关联在一起,从而形成一个完整页面。

这是通过上述技术得到的一个聚合的页面(一个德国的游泳运动员),不仅呈现比赛新闻信息,也包含这个运动员的方方面面。
知识图谱在金融方面的应用
金融方面是仅次于医疗(知识图谱应用最广泛的领域)。
先介绍一个我之前参与的国外的例子,是针对荷兰的案例。荷兰的法律导致破产是不用负责的,所以很多人钻这个空子来构建团伙进行倒卖,最后将其中的一些公司申请破产导致非法免费获得很多资源。
对此,荷兰政府非常头疼,希望找到幕后组织,从而避免很多损失。
大数据环境下,各个部门和组织的数据非常分散,导致各个部门没有办法得到完整的信息来进行对上述团伙的判断。而传统的数据集成方法需要依赖非常有经验的专家对这些数据库进行手工集成,这大大增加了工作量和处理周期。
所以这里我们又将引入知识图谱,进行有效的去中心化的高效知识融合。
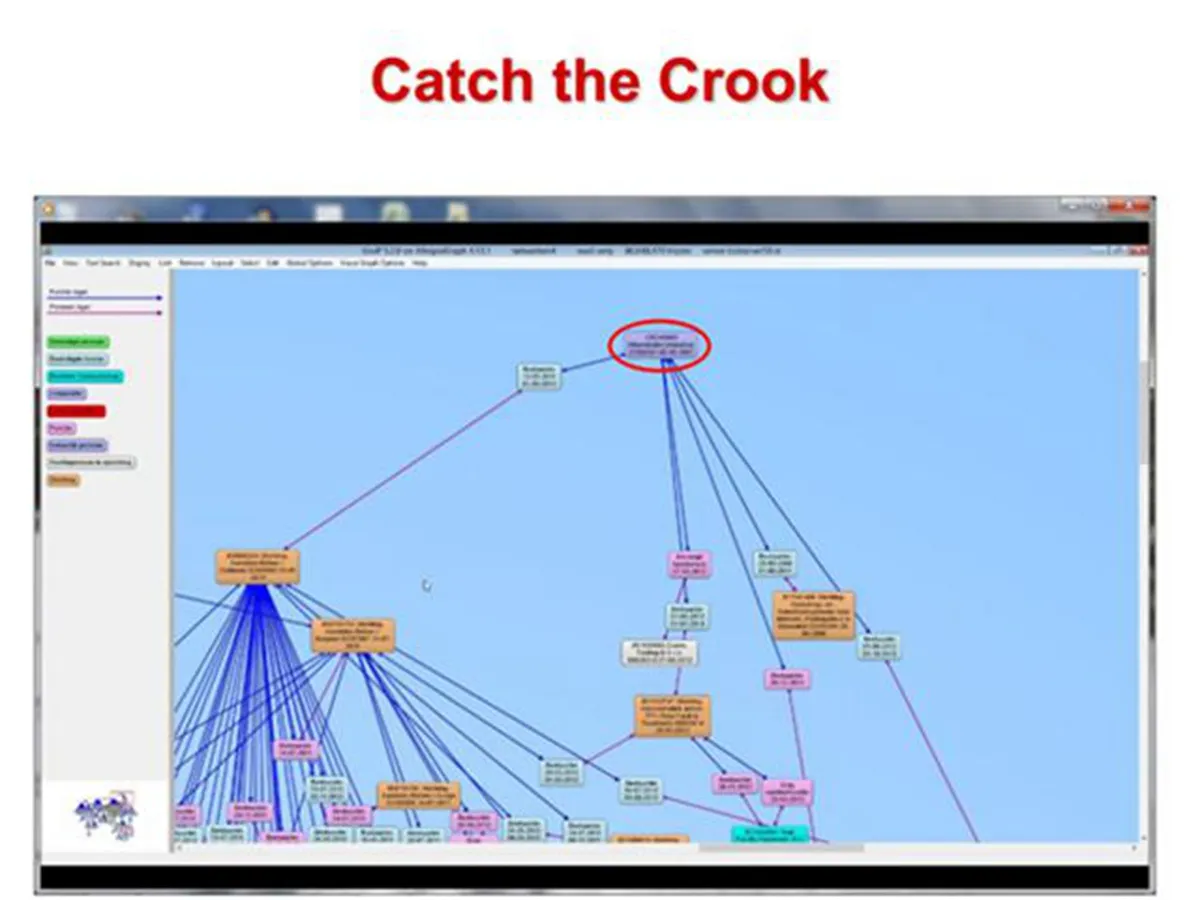
这是一个示例,和农业中的方案类似,不过使用了一个 Hadoop PIG 脚本来控制转换过程,之后我们将通过图可视化来发现这样的团伙。
这个可视化的图中可以看到粉色的公司、橙色的机构和红色的破产的公司。
当我们将这张图进行缩放之后,可以发现这里一些有趣的模式,所有的红色破产企业都关联到图中圈定的公司,那么这个公司就有可能是指使这些破产行为的最终元凶。政府相关部门就可以对其进行深入的调查,这样使得原本大海捞针的搜索变得很有针对性。
还有更多的例子:
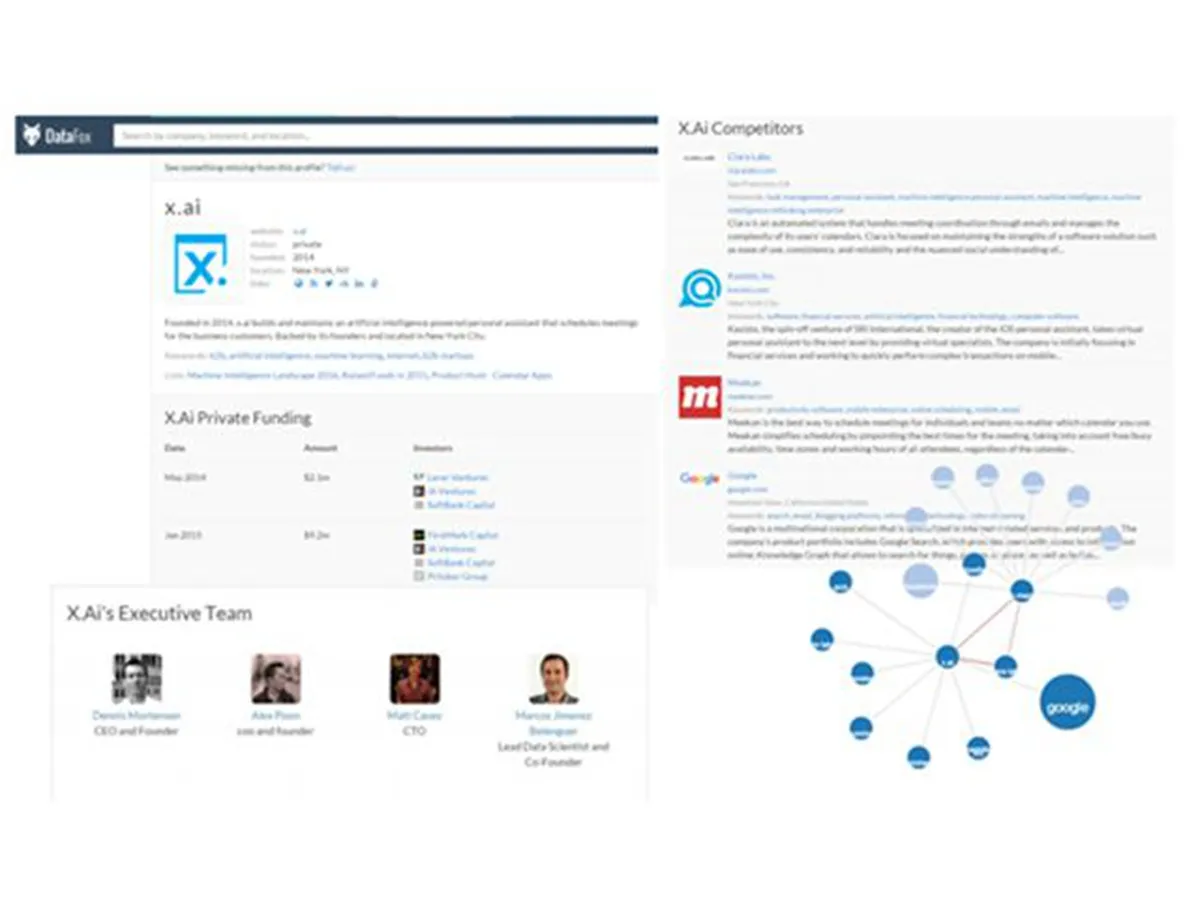
国外有 Datafox 和 Spiderbook,国内有通联数据等。
他们通过从互联网上抽取各种公司(主要是上市公司)的数据,包括产品、高管、公司供应链关系、竞争对手关系等,整合为统一的图谱从而帮助企业或投资机构进行全网数据的关联分析,影响传播和一些预测。
最成功的例子包括福岛爆炸对丰田汽车的股价影响。
知识图谱在政府中的应用
这里就不得不介绍最近非常红火的美国的独角兽 Palantir。
Palantir 应该是美国最早在政府领域使用知识图谱技术的公司,帮助美国政府成功定位到了本拉登的位置等。
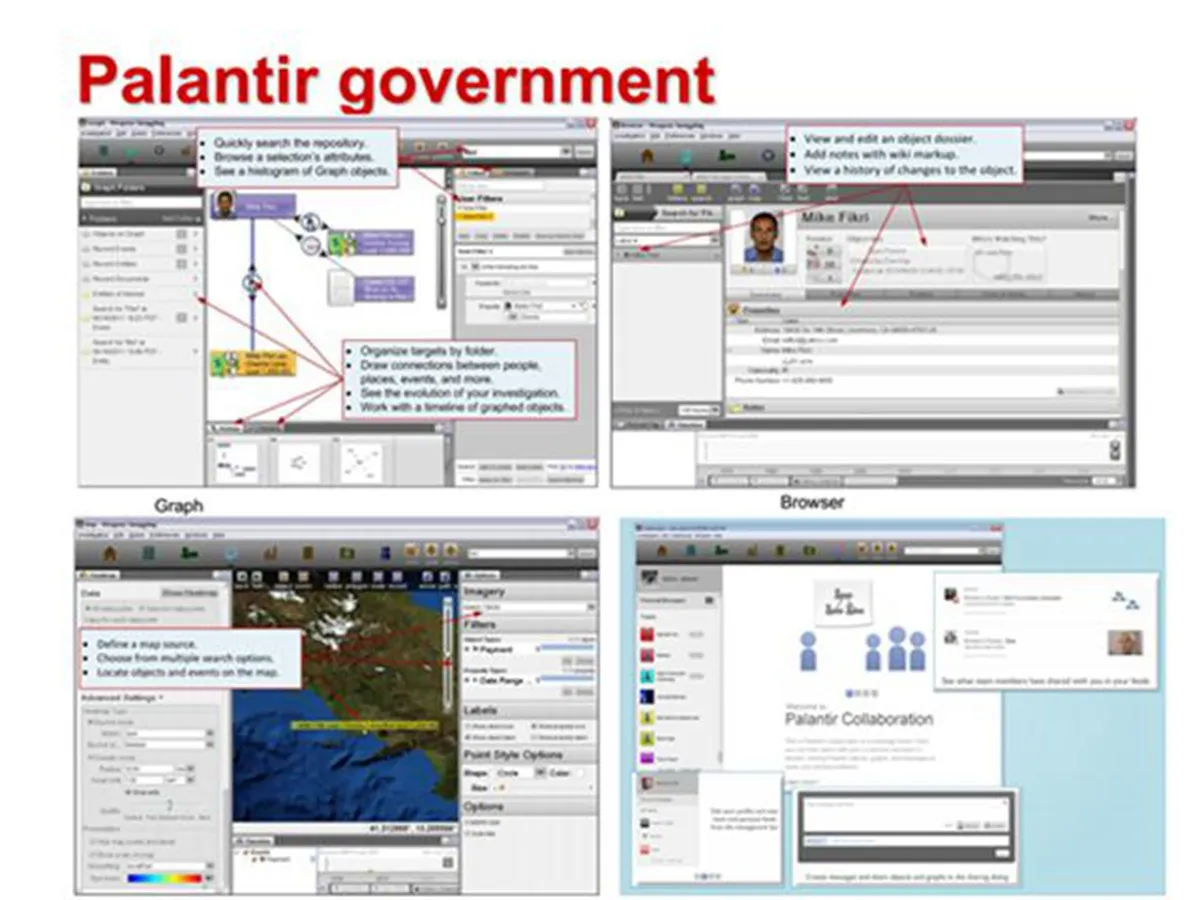
其界面也包含各种图谱浏览、搜索、建模等工具,类似的,将不同来源不同格式的数据进行建模整合,来得到全面分析和挖掘的可能。
总结来说
知识图谱能做到的就是让知识可被用户访问到(搜索),可被查询(问答),可被支持行动(决策)。

题图来源:CSC