
文/余晟
最近的面试中我发现一个很有意思的现象。问“还记得数据库范式吗?”,大多数工作了几年的开发人员都答不上来,但是其中大多数人会补充说“虽然我不记得范式了,但我可以保证自己设计的数据库肯定都是符合范式的”。
身为技术人员,大家都知道逻辑的重要性,那么逻辑的结论就是:范式这东西完全不重要,不记得了也不妨碍使用,而且不会出错。这种结论似乎有点不合逻辑,所以有必要专门谈谈范式。
很多人都知道有“数据库”这种东西,但“数据库”对他们来说只是“存放数据的仓库”而已,这是大错特错的。我们常说的“数据库”,其实是“关系型数据库”的简称,常说的 DBMS(数据库管理系统)其实是 RDBMS(关系型数据管理系统)。其中的“关系”来自关系模型,这是 Edgar F. Codd 教授在 1969 年提出的,使用遵循一阶逻辑的语言和结构来管理数据的模型。在这种模型下,所有的数据首先表现为n元组(tuple,和 Python 中的 tuple 不完全一样),n元组组合起来成为关系(relation)。按照关系模型构建起来的数据库,就叫“关系型数据库”。
如果上面的解释有些抽象,下面给出了 5 个n元组的例子:
小明, 20, 172m, 74kg
小李, 18, 168m, 60kg
小张, 30, 188m, 90kg
小王, 男, 物理系, 大三, 单身
小陈, 女, 中文系, 大一, 非单身
虽然看起来很直白,我们还是应该从关系模型来讨论。前 3 个是 4 元组,后 2 个是 5 元组。在n元组内,每个元素都可以称为“属性”,同类的n元组集合起来,称为“关系”。
如果上面的讨论让你觉得抽象,把这些概念换成具体的实现就容易理解了。“属性”对应“列”,“关系”对应“表”,这就是我们日常要应对的数据库的样子了。但是请记得,列和表只是具体的落地方式,讨论关系模型时我们应该谈的概念是“属性”和“关系”。
基于关系模型,Codd 教授提出了“规范化”的概念,也就是在不丢失数据的前提下,把表拆分为更小、冗余度更少的表,同时可以通过不同表之间的外键引用“组装”出原有表的信息。我们说的“范式”就是“规范化的要求”,其中第 1 范式由 Codd 教授在 1970 年提出,第2、第 3 范式由 Codd 教授在 1971 年提出。范式之间是递进的,也就是说,满足第 2 范式的前提是满足第 1 范式,满足第 3 范式的前提是满足第 2 范式。通常,如果一张表满足了第 3 范式,就认为这张表是“规范化”的,在增删改查操作时不会出现异常。
下面详细看看这 3 个范式。
第 1 范式:属性不能拆分
换句话说,表中间的任何列都应当是承载信息的最小单位,不容许有更小的单位。一个人有身高、体重、性别等等,那么身高、体重、性别都应该对应专门的列,而不能取个名为“基本信息”的列,把这些信息统统塞进去。
实际开发中,把身高体重性别等信息都挤在同一列里的情况当然很少出现,但很多人喜欢把数目不定的属性(尤其是标签)用逗号连起来塞到同一列里。这多半是因为分不清楚数据存储模型和表现形式,看到显示的时候可以用逗号连起来,就想到在数据库里也可以用逗号连起来。谁如果做过这样的事情,还大言不惭地说“我设计的表都符合范式”,真应该拉出去打屁股。
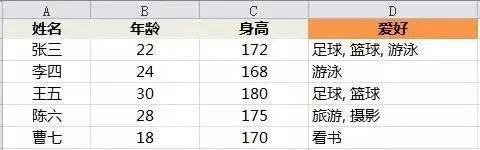
上面的表不符合第一范式,因为“爱好”这个属性可以拆分。
有人可能会不服气“这样有什么坏处呢,这样存储也没有问题,我用 like 来检索就好了呀”。没错,高射炮也可以打蚊子,菜刀也可以用来割草,只是会损失原有的设计功效。数据库也一样,如果列可以拆分为多列,那么 SQL 语句中的很多功能就不能用了——比如大小于判断、索引等等——因为这些功能设计时考虑的最小单位就是“属性”,而不是“属性中的属性”。如果你愿意打破第一范式,就必须舍弃 SQL 本身的若干功能。
要把不符合第 1 范式的表“改造”为符合第一范式,有很多办法。比如把“爱好”单独拿出来创建一张表。当然,这样在查询“有某个爱好的人”时,操作逻辑就没有那么直观了,而且这样的表看起来“增长很快”。
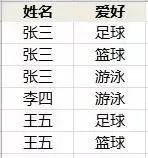
第 2 范式:主键必须最小
主键是这样的属性:对某个关系中所有n元组来说,主键必须是没有重复的,所以依靠它可以唯一定位某个n元组。主键可以是一个属性,也可以是多个属性。如果用列和表的说法,就是“唯一定位表中某行所要用到的列”。
假设有一个电商卖家对接到电商平台,用表来存储订单信息,如果所有订单都来自同一个平台,可以用“平台订单号”作为主键;如果来自不同平台,各平台的订单号可能会重复,所以可以用“平台 订单号”作为主键……以此类推。
第 2 范式的要求是:在满足第 1 范式的基础上,所有非主属性(主键之外的属性)必须完全依赖主键,而不能只依赖主键的某个子集。
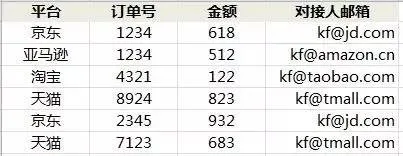
上面的表不符合第二范式,主键是“平台 订单号”,这样才能区分金额,但是“对接人邮箱”只与“平台”有关,而“平台”是“平台 订单号”的子集。
我们经常看到数据库的表会有一个毫无业务意义的自增字段作为主键,这样就保证了第二范式,因为主键只有一个属性,不存在真子集。同时,应当把非主属性和原来它依赖的“主键的子集”单独拿出来建表,比如建立一张“平台 对接人邮箱”的表格。
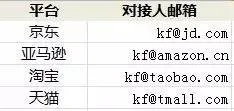
第 3 范式:主键必须直接依赖
要满足第 2 范式,首先必须满足第 1 范式。同样的道理,要满足第 3 范式,首先也必须满足第 2 范式,并符合以下要求:所有非主属性对主键的依赖应当是直接的,不容许是间接的。也就是说,所有非主属性不容许依赖主键之外的属性。
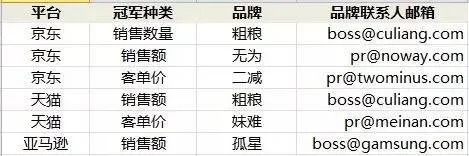
上面的表不符合第三范式。主键是“平台 冠军种类”,但属性“品牌联系人邮箱”依赖于主键之外的属性“品牌”,虽然“品牌”依赖于表的主键,但“品牌联系人邮箱”对主键依赖是传递的。
要让表符合第 3 范式,可以解除传递依赖,把对应的属性拆分出来单独创建表,比如把“品牌”和“品牌联系人邮箱”单独创建表。
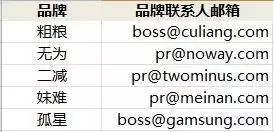
以上就是第1、第2、第 3 范式的简单讲解,如果我们仔细观察就会发现,这些范式背后都体现出“出现重复数据”的目的,一旦出现了重复数据,就要想办法把这些数据单独抽离出来单独建表,再通过外键这种“指针”来构建关系。这样做的好处不只是节省磁盘空间,还保证了数据一致性:数据库系统能够保证 ACID 四个特性,但如果表中存在冗余数据,同一份数据存在多个副本,是很难从逻辑上保证一致性的。如果让应用程序来保证一致性,哎还是算了吧,很多程序员早就被数据库给惯坏了,脑子里根本就没有“一致性”和“临界区”的弦。
但是“规范化”并不是万灵药,去除数据冗余性的反面就是,某些看来简单的操作,经常需要涉及多张表,这无疑会影响效率。如果遇到这种情况,就要适当进行“去规范化”的操作,增加数据冗余性,以提高操作的速度。
比如常见的“订单查询”页面,可能要同时展现订单基本信息、客户购买记录、客户收货地址、最新物流信息等信息,如果严格按照规范化建表,那么涉及的表可能很多,这个操作可能耗时很长,如果这是一个每天要执行很多次的操作,很可能就会成为系统的瓶颈。如果适当增加冗余性,把常用的数据集中存放到少数表里,每次简单查询就可以获得,就可以解决这种问题。
以上说的“去规范化”,是建立在对“规范化”和应用场景的熟悉理解,对数据模型的深入思考的基础之上做出的权衡,绝对不是不懂规范化也可以随意胡来的。但凡复杂一点的系统,都值得花足够的时间来思考基础的数据模型和它们之间的关系,这些东西不但会影响程序的运行,还会影响所有开发人员的认知。因为网页上的很多数据看起来是表格形式,就直接就照看得见的样子去建数据库的表,导致应用系统内部一塌糊涂,开发的时候举步维艰,这样的例子已经见得太多了。
顺道还可以谈谈 OLTP 和 OLAP,在业界经常可以看到 OLTP 和 OLAP 两种应用分类,也对应着完全不同的数据库建表取向。OLTP 是 On-Line Transaction Processing,PLAP 是 On-Line Analysis Processing。前者侧重在“交易”,强调速度,只处理少量数据,所以通常会对规范化有比较高的要求;后者侧重在“分析”,不强调速度,经常要面对海量数据,所以对规范化不会有那么高的要求。这些概念看起来简单,不幸的是在实际开发中,把 OLTP 和 OLAP 搞混的还是大有人在,这多半只能说明“缺乏常识”了。
最后谈谈 NoSQL。
问很多开发人员“什么是 NoSQL”,很多人回答“就是 MongoDB、Redis、Memcache”,再问“为什么要有 NoSQL”,就答不上来了,这多少有点让人惋惜。
之前讲过,现在的 DBMS 其实都是 RDBMS,R表示“关系”。“关系”这种概念,是非常适用于银行记账等等场合的,但是未必适合各种场合。比如之前谈到的一个人可能有很多种爱好,这是很自然的认知,程序处理起来也很容易,但为了符合第 1 范式,就必须新建单独的“爱好”表,如果存在“爱好里面还有细分爱好”的嵌套关系,关系模型处理起来就更加麻烦了。说到底,这根本不是一种“关系型”的模型(我甚至觉得,大段的文章本来都是“不应当”存放在数据库里的)。
而且随着 IT 技术的飞速发展,各种系统要面对的数据量都在飞速增长。之前成熟的 RDBMS 面对的问题规模都比较小,几十几百万,甚至上千万的数据处理能力,对日常记账或者图书管理、仓库管理来说已经非常足够了,但面对互联网上动辄几亿几十亿的数据量(微博、图片等等)就为难了,加上还必须保证以前关系数据模型的各种特性,已经不堪重负了。
从这两个方面来看,NoSQL 的出现也就不足为奇了。它可能只有非常简单的数据类型和特性支持,但换来了对海量数据的支持(有人说某些 NoSQL 也支持“事务”,但这个“事务”和关系数据库的“事务”不是一回事);它可能没有那么严格规范美观,但支持现实中的各种需求,比如各种复杂的数据类型(文档、键值型、列表、集合等等),为开发提供了巨大的便利。
NoSQL 带来了灵活性,也带来了混乱。因为关系型数据库背后是有一整套理论模型存在的,脱离了这套模型,“外面的世界”到底什么样,应当用怎样的模型来解决问题,某种模型适用于哪些问题哪些领域,目前还没有定论,所以 MongoDB 和 Redis 之间的差别,远远超过 MSSQL 和 MySQL 之间的差别。毕竟,破总比立要容易。
归根到底,到底是选择 RDBMS 还是 NoSQL,如何选择 NoSQL,还是取决于开发人员对领域问题的认识,以及对各种工具的理解——如果坦然抱着“我不懂范式但这不妨碍我建表”的超然态度,多半是解决不了这个问题的。
最后推荐《数据库:原理、性能与编程》,高等教育出版社 2001 年出的影印版。我很庆幸自己在大学里遇到了这本教材,从关系代数开始,把关系模型和数据库讲得深入浅出。观念对了,后续的开发就会受益无穷。