
人工智能与AI是科技领域永恒的话题,更是科幻小说作者笔下不朽的题材,在游戏方面,敌人AI或队友AI的智能程度更是与游戏耐玩性息息相关,今天让我们再来开一场关于AI的脑洞。
2016年1月28日,又是人工智能历史上的一个大日子。这天著名国际科技期刊《自然》杂志的封面论文《通过深度神经网络和搜索树精通围棋》如一石激起千层浪,同时在计算机界和围棋界掀起轩然大波: Google DeepMind开发的人工智能程序AlphaGo(顺带一提,围棋是英文就是“Go”,从日语翻译过来的)以5:0吊打了欧洲围棋冠军樊麾。虽然说欧洲作为围棋荒漠,其冠军也不过是职业二段,而且事后中国棋院的职业选手也认为:主要是樊麾久疏战阵下得不好、AlphaGo的实际水平大概相当于职业入门的水平。但这围棋AI的恐怖之处在于,哪怕不升级算法,也能在不断的对弈中提升实力,遇强愈强。类似于人——或者说更类似于玩家们很熟悉的虫族:吞噬,进化。即便人类当前还有抵抗之力,围棋AI从人类身上碾过,不过是时间问题而已。
那么,为什么在围棋上计算机战胜人类会引起这么大的轰动?这项成果又能用到哪些方面?

人类智慧的皇冠
让我们回到19年前,1997年5月11日,随着手持长枪短炮的记者们的一阵骚动,IBM公司研发的超级国际象棋电脑“深蓝”在连续三盘和棋后,终于在第六局取胜,以总分3.5:2.5战胜了当时在国际象棋领域独孤求败的卡斯帕罗夫,宣告计算机在国际象棋项目上完成对人类的超越。
计算机的崭露头角在当年轰动一时,也引起不少人对于AI取代人类的恐慌,甚至在随后的几年衍生出了大批电影和文学作品。尽管在深蓝与卡斯帕罗夫之战后一段时间内还有人类战胜或者打平电脑的事例,但随着计算机性能的快速提升,终于在2006年之后,便再也没有人下得过电脑了。自此,人类在棋类游戏中的堡垒,仅剩围棋一座。
为什么是围棋而不是象棋,也不是陆战棋?围棋到底有何特别之处?
一点是围棋有着极为丰富的下法,随着中国古代围棋在四个角星位放四个棋子限制局面的“座子制”被废除,今日围棋19×19的棋盘上没有任何的限制,不似象棋有着规定的排兵布阵,棋子也不需受到只能在某个特定的方向走特定的步数之类的限制,只要你喜欢(以及对手配合),甚至用棋子拼几个字母打广告照样在规则准许范围之内。
极为自由的下法带来的是恐怖的局面可能性:只从明面上看,就有3的361次方种下法,远超宇宙的原子总数,再加上打劫和提子等技巧,围棋的局面走势可以用“无限”来形容,因此围棋素有“千古无同局”的美誉,这也就让“算出所有的局势并挑选最佳路线”的计算机下棋方式在围棋面前一筹莫展。

当然,电脑下棋也往往不会将所有可能的路径列出来再挑选,这样太浪费机能和时间了。一般会用算法排除掉明显没用的路线,在剩下的可能性中选择最佳方式走棋。这里就体现出围棋的另一个精巧之处:一般的棋类只要干掉对方的国王/将军/司令之类,因而可以轻松排除掉无用的路线,围棋却没有明确的目标和结构,一子之差就能让盘面上的局势天翻地覆:每一步棋都可能是有用的,导致不仅每一步棋都有着数百种下法,而且还无法排除,计算机也就迟迟不能攻占这人类智慧的最后堡垒。
但是,既然人可以下好围棋,也就证明,围棋虽然没什么易于直接总结的规则,但冥冥之中还是有规律可循,只是不容易总结而已。于是研究人员就想到,只要让计算机也学会人类的思考方式,照样可以下得好。DeepMind 的研究人员就祭出了“深度学习”技术,即是让计算机用人类的方式来下棋,在不断下棋中评估局面,抛弃那些送子的自杀式下法,同时估计在未来20步中下在哪里取得优势的概率更高,每局下来都可以积累更多的经验,从而让自身的概率估计更为精准。
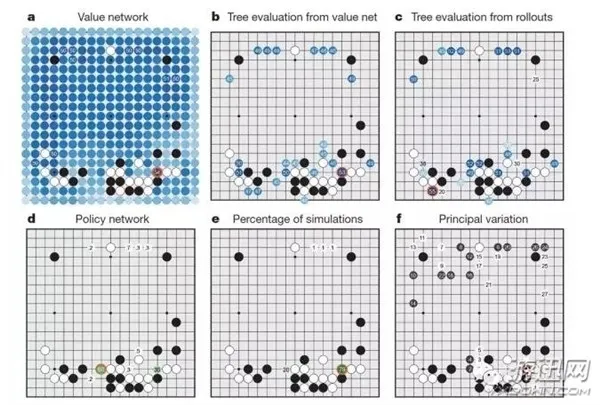
在经过无数高手棋局的训练和自己跟自己对弈500万局之后,AlphaGo 的实力就达到了职业水准,而且还可以进一步提高。
今日的智能
啊,好像是扯得有点远了,我也不是来播报新闻的,既然是游戏网站,那接下来就该说一下这项技术除了用来下围棋以外,还能跟游戏扯上什么关系。
要理解这点,我们就首先要知道现在我们玩的游戏里的AI是什么机制,这样我们才能知道深度神经网络能让AI发生什么改变。今天我们玩的电子游戏,无论是星际2、War3、老滚4、文明5,不管游戏方式再千奇百怪,其AI用的都是同一套行为逻辑——“有限状态机”。
听起来很高大上的样子,不过实际上我们也用不着深入剖析,简单而言,就是让游戏AI对于一定的情况选择一种应对方式。比方说,LOL和Dota的电脑AI会设置为,当其血量低于玩家一套技能伤害时就会自动往后退或者回城,FIFA的AI会自动传球给当前状况下得分成功率最大的球员。如果说一场游戏里可能出现的所有状况就是一张试卷的题库,那么有限状态机就是参考答案库,一旦出现某种“题型”,就挑选出相应的“答案”。虽然实际情况复杂得多,要用上很多层的状态机环环相扣,不过究其本质,都是这个机制。
这套机制的确实用又好用,以至于电子游戏业界数十年如一日地坚持使用,一路欣欣向荣,在这套原理的基础上发展出更多更好更复杂的AI。然而,盛世之下也潜伏着危机,有限状态机始终有几个与生俱来的缺陷并限制了游戏内容的发展。
前面提到,如今的游戏内容跟AI策略就是题库与答案的关系,那么这里就有几个问题:要是题库太大呢?要是答案有错漏呢?都是标准答案的AI怎样才能看起来像真实玩家?
事实上“题库”确实是在不断地扩大。机能的提升、玩家对游戏要求的提高、沙盒游戏的盛行等原因都使游戏世界渐趋宏大,可以与玩家互动的环境与角色数量都在大幅上升,这就导致交互内容、也就是游戏中可能出现的情况越来越多。为了应对更为复杂的游戏环境,游戏AI的制作者必须事无巨细地将任何时间任何情况任何人物所做的任何事情都写入“题库”,并且让AI对这里的所有情况都作出回应,这就致使哪怕是优化得再好的AI,其程序代码也是长得令人头晕目眩,编写和维护的难度极高,开发成本上涨的同时花样繁多的bug也是接踵而至,而复杂的构成使得为游戏AI查缺补漏的周期甚至可能长达数月,对很多游戏而言,几个月便意味着生命周期已步入尾声了,任何的改善都是为时已晚(别看了,育碧,说的就是你)。
任何复杂的AI程序设计,都不足以概括所有的情况,对RPG游戏而言,能维持好剧情里出现的角色不出问题就很好了,路人也就是路过打个招呼的级别,于是在当今的“沙盒游戏”中,大部分的路人完全不像是活物,不过是在街上游荡的空壳,是充实背景的材料。
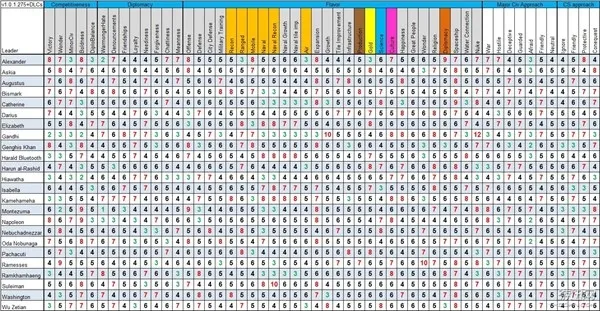
再说到“答案库“的错漏,就不得不提及下面这位:

《文明》系列玩家们都不会对核弹狂魔甘地这个梗感到陌生:《文明》的AI行为倾向是简单地用1-12的数值来代表的,在初代《文明》中,在现实世界一直提倡“非暴力”的甘地的“侵略指数”被设定为最低的1,几乎不会对别的国家发动战争。然而在游戏中采用“民主政体”后“侵略指数”会下降2点,对别的领导人来说没什么问题,只是甘地本来就是1,再下降2点后就变成了-1,数据溢出导致侵略指数变为了数值设置的上限255,圣雄甘地一跃变为战争狂人大炸逼。这反差莫名地产生了喜剧效果,于是开发组为了致敬这一事件,在后来的文明系列中也照样将甘地塑造为一个核弹狂。这虽然是一个个例,却也折射出由简单数值控制的AI很可能会因为小疏忽导致严重的问题。
明日的曙光
如果说别的问题都可以通过投入更多的人力物力还是可以在很大程度上解决的话,那也还有个悬而未决的问题:游戏AI实在是太不像人了。用回前面的比喻,AI解决问题的方式就像是在试卷上每题都用标准答案写就,哪怕有问题也类似于其他每题都全对却有一题直接空白,这很明显不是人类的手笔。AI只能简单地应对状况,要是情况超出设计者的设计,就会莫名其妙地犯蠢:在围棋中是下出一步瞎棋白白送子、在体育游戏中是队友突然挡在玩家的去路上、在MOBA游戏中则是一味遵循逃跑的指令而忽视半途杀出的玩家,这些都是很影响玩家体验的情况。传统AI设计得再好,也模仿不出人类的感情(此处应有BGM:画着你,画不出你的骨骼……)。
有没有可能让AI表现得更像人呢?本文开头说到的围棋程序正是解决这一困境的曙光:AI用人类的方式来学习,从而表现自然更接近人类,其结果同样是相当成功的。可以看看中国围棋等级分排名第一的柯洁对于AlphaGo与樊麾棋局的评价:
“这五盘棋我也仔细地看了一眼,但我没看名字,不知道谁执黑谁执白,完全看不出谁是AI。感觉就像是一个真正的人类下的棋一样。该弃的地方也会弃,该退出的地方也会退出,非常均衡的一个棋风,真是看不出来出自程序之手。因为之前的ZEN那样的程序,经常会莫名其妙的抽风,突然跑到一个无关紧要的地方下棋。它这个不会。它知道哪个地方重要,会在重要的地方下棋,不会突然短路。这一点是非常厉害的。”
既然这种方法能让AI表现如同人类,那有没有可能把这种方式移植到游戏上来呢?答案是:有,而且已经有人试过了。无独有偶,进行这次尝试的不是别人,正是开发AlphaGo的DeepMind公司。

这帮人没有用以往的AI开发方式玩简单的雅达利游戏,而是让他们的AI通过神经网络,跟人类一样“阅读”屏幕上的像素,然后用游戏自带的奖励向AI反馈,简而言之,就是跟人类玩游戏是完全相同的模式。在一段时间的学习之后,他们的AI在7个游戏中有6个取得了比过往的AI更好的成绩。最为惊人的是,玩这7个游戏的是同一个AI,丝毫未改,真的就像是创造出了一个“人”。
受此启发,2014年一名斯坦福大学的博士,也开发出了一个类似的《星际争霸2》AI:它通过接收渲染器正在渲染的数据来分辨单位和建筑等信息,例如渲染器调用了战巡舰的材质,这个AI也就得知那个位置的是个战巡舰,也就是说,这个AI能看到的信息跟人眼看到的信息是完全一致的。
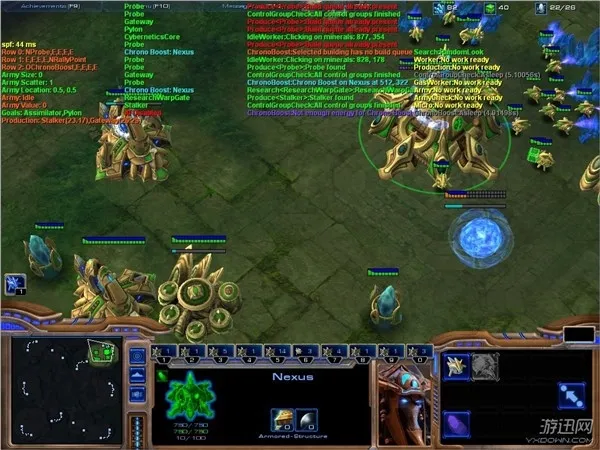
在以“人类的方式”玩游戏的前提下,这款AI做到可以战胜疯狂以下难度的电脑AI的程度,虽然只取得了初步的成就,但也提供了一种RTS游戏AI的新思路。
未来的畅想
神经网络算法虽然在今天只是个雏形,但可以大胆预测,运用神经网络的AI在游戏中超越人类也不过是时间问题,人一年可以打几千把LOL,而AI完全可以打千万把,在相近的学习速度情况下,AI玩得更好是理所当然。然而, 在游戏中引入神经网络可不是为了找到最佳玩法,要是AI能轻松吊打每个玩家,那这款游戏就没必要存在了。新技术的使用,是为了让游戏AI更加“人格化”,减少玩家对AI的隔阂感,增添游戏乐趣;也可以和传统的AI设计相结合,让AI的决策更加聪明,减少“猪队友”现象,也再不用怕玩《文明》的时候别的国家放弃自身利益也要来干你了。
深度学习算法还可用于自然语言的处理,也就是说,在遥远的未来可以让游戏AI像人类一样和你正常交谈,到那时候,玩家们终于可以农奴翻身当主人,不再是电脑滔滔不绝而玩家只有几个固定的选项,而变成玩家滔滔不绝让电脑自己来理解了。

再进一步地想象,深度学习也可用于“人格”的构成,足够多的事件训练有可能让AI如人类一样有着特定的选择偏好,正如人类的“性格”一样。要是AI学会了正常交谈,也有自身的“性格”,真到那时,说不定可以让玩家透过虚拟现实设备,和历史人物谈笑风生,体验一把穿越剧的感觉。