

——第十七届“二十一世纪的计算”学术研讨会
图灵奖得主 Michael Stonebraker 的主题演讲
微软亚洲研究院主页君小田热心提示:搭配文中的视频和 PPT 阅读,效果更佳!
观看演讲视频:【2015 年 21 世纪的计算】Michael Stonebraker 的演讲
PPT 下载链接:http://vdisk.weibo.com/s/z7VKRh2itilfs
今天,我要跟大家谈谈大数据。大数据这个词其实是一些做营销的人发明的,大概是几年前的事情。然后我也非常高兴,我终于知道过去四十年自己到底在做什么,我原来是在做大数据。所以我想跟大家谈谈大数据对于我来说意味着什么,以及我认为的大数据中什么是重要的。
关于大数据,很多人说意味着三件事情,这三个单词都是以字母V开头的。

大数据的问题,第一个就是量(volume)很大。第二个是这些数据的产生速度(velocity)太快了,软件跟不上。第三个问题是数据来自许多不同的地方(variety),你需要进行数据整合,但这些数据来源太多了,你想要整合这些数据就非常困难。所以在这三个“V”领域你要解决的问题是完全不一样的,我分别给大家谈谈。
Big Volume 大量数据
在量方面,第一种情况是你要想做一些非常愚蠢的分析,比如说 SQL 分析。第二种情况是,你想要做非常复杂的分析。前者是比较简单的,如果你想做 SQL 分析的话,我知道你可能要在上百个节点,PB 的数据上面运行二十到三十个生产实现,日以继夜地进行分析。在这些数据仓库产品中,有几款已经做得还不错了。所以,这个市场的需求其实已经被一些商业软件很好地解决了,比如说 Vertica,就是这样的一家数据仓库公司。他们最大的用户叫做 Zynga。Zynga 开发了一个名叫 FarmVille 的游戏。Zynga 会实时记录全世界每一个用户在玩他们的游戏时每一次的点击,这样的话就可以利用他们的数据做人工智能研究,看看如何能够让全世界的用户购买更多虚拟商品。所以,我认为这个问题已经得到了解决, 因为现在即使你从用户身上获得大量的数据,他们也不会感到不快。但我要提醒一下大家,在过去十年里,我们已经经历了一个非常巨大的变化。

大约十年以前,如果你去和一些卖数据仓库产品的公司聊的话,他们基本上卖的都是一种叫做“行存储”(row storage)的产品,这是指存储的下一个对象是同条记录的下一个属性。他们在磁盘上用行的方式存储数据。SQL 服务器以前就是这样的。

其他的数据仓库公司都是卖这样的产品。当时我成立的这家公司叫做 Vertica。我们从另外一个角度来看待这件事情,把行转 90 度,变成列,用列的方式存储数据。
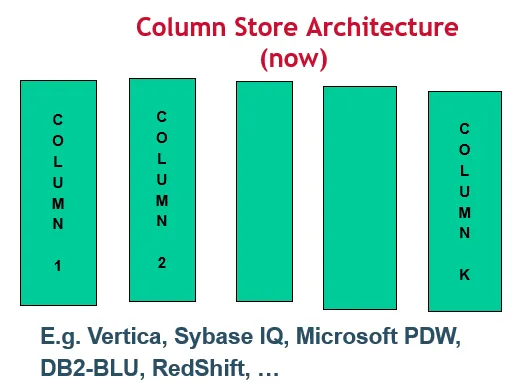
于是存储的下一个对象就从同一条记录的下一个属性,转变为下一条记录的同一属性。这种方式比原来的行存储方式要快很多。Vertica 完全颠覆了这个市场。它的速度比行存储产品要快 50 到 100 倍。这是颠覆性的。

而这是由一家创业公司带来的。所以我认为,在这个市场上实现颠覆的一种常见方式就是成立一家公司,然后去挑战那些大公司,让他们感受到威胁。所以在过去的十年里,整个市场都开始转而采用列存储。其中包括微软的数据仓库产品 PDW,也是用的列存储, 不过是 10 年后才用的。为什么列存储的速度要比行存储快很多呢?当然,这背后有很深层次的技术原因,不过我现在没有时间去详细解释了。厂商要取得成功,他们必须做出转变。于是,基本上除了 Oracle 外,所有其他厂商都开始采用多节点列存储的方式,它的速度非常快。在过去的十年里,正是由于这种颠覆性的转变,数据仓库产品的性能提升了 50 倍。但是在我看来,这已经是明日黄花了,就像 PeterLee 所说的,人们现在感兴趣的是机器学习,机器翻译,数据聚类,预测模型,这些才是接下来要做的重要事情。

借用华尔街的说法,我们已经进入了“股市分析员”的时代。这些分析员其实与火箭科学家无异。如果你是一名从事数据库工作的人员,当你仔细去看他们的算法和他们的工作,你会发现,其实大部分的算法都是采用数组形式的线性代数,而不是表格形式的 SQL。这与现实世界毫无关系。如果你再仔细看这些算法的话,你会发现,其实大部分的算法都是内循环迭代,也就是执行几次诸如矩阵乘法、奇异值分解之类的线性代数运算。为了说明这一点,我来举一个非常简单的例子。

这个例子就是人们为之疯狂的股票市场。股票市场有涨有跌。假设有两只股票——A和B,让我们来看一下它们在过去五年所有交易日的收盘价。如果你想的话,可以假设这两只股票是华为和阿里巴巴的股票。如果你在做电子交易,你可能想知道这两只股票的收盘价是否有关联,它们的时间序列是否有关联。如果有关联,那么如果一只股票涨了,你是否应该购买另一只股票?所以你能做的最简单的事情就是计算一下这两个时间序列之间的协方差。具体的做法我已从我的统计课本那里抄了下来——如果我没有抄错的话——就是幻灯片最下面的红色字。这就是你想要计算的东西。

其实并不难。你在手机上也可以做这种计算。但现在,假设你要对纽约证交所的所有股票进行这样的计算,有差不多四千只股票。五年的数据大约有一千个交易日。假设你有这样一个红色的矩阵,其中你有一只股票的一千个收盘价,然后一共有四千只股票。我要做的就是要计算每一对股票之间的协方差。


理想的大数据用户是当你解决了这个问题后,他马上就会想要更多的训练数据。你为华尔街的股市分析员解决了问题后,他又会想要为全世界所有的股票做这种计算,而不是仅仅纽约证交所上的股票。这就是你想要做的事情,不过不是在 SQL 中做,甚至不是在表格中定义的。所以我认为,对于一个数据科学家来说,他必须要对他的数据进行清理,去粗取精。这是他现在大部分时间所做的事情。


那么应该如何解决这个问题呢?如果你现在要做这样的工作的话,你很可能会成为R、SaaS 或 Matlab 等统计软件的忠实用户。



这是一个很糟糕的解决方案,因为你得学会两种完全不同的系统。而且要在两个系统当中来回拷贝。这样做的结果是让网络销售商大赚了一笔。而且R还无法扩展。所以研究的挑战就在于找出一种更好的方法。很明显这就是人们现在每天所做的,也是数据科学家在实现世界中所面临的挑战。我们应该可以做得更好。我倾向于将它视为数组问题来看待。这并不是表格问题。我们为什么不能用数组型数据库系统呢?所以,跳出你的思维条框,摆脱那些表格,用数组去取代它们。所以几年前我写了一个名叫 SciDB 的系统。它支持在 SQL 上使用数组,内置有分析方法,对于矩阵乘法的计算速度非常快,而且与现在许多其他软件一样,它是基于开源的 Linux 系统开发的。你可以试着去 SciDB.org 寻找一个颠覆性的解决方案,看看结果如何。

之所以说数组是一个理想的解决方案,是因为如果你将一个表格模拟为数组,那么你会得到一个维度为I和J的数组,而且被赋予了值。如果你想得到一个 4x4 的矩阵,那么它的左边就是表格的模拟。
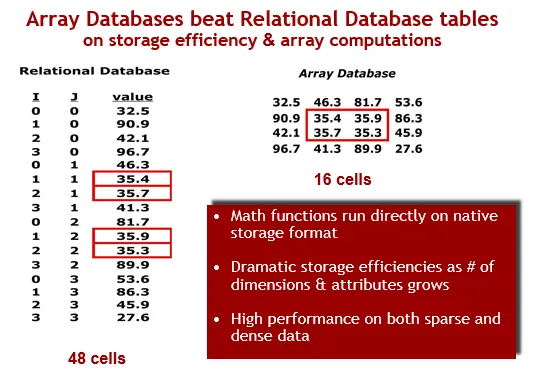
注意刚才已经明确指定了维度。然后有大量的数据。右边是数组表达。你可以完全压缩掉这些维度。很多时候你想要得到该数组的一个子集,例如地理子集。它在右边可以很容易地定位。但在左边就很难做到。所以数组型数据库系统具有一些先天的优势。我认为从长期来说,这种技术将成为最终的赢者。现在我必须向大家坦白,Hadoop 曾经存在很严重的问题。让我们来看看 2012 年前后的 Hadoop。

Hadoop 是一个真正的三层堆栈。位于底层的是文件系统 HDFS。中间层是由谷歌写的 Map-Reduce。雅虎写了一个开源的版本。然后在顶层有各种不同的高级系统——Hive、Pig、Hahout 等等。这就是 Hadoop 在大约三年前出售的堆栈。他们发现,当你试图让实现世界的用户使用该产品时,Map-Reduce 并不是一个特别吸引人的分布式计算平台,这其中有许多技术上的原因。所以它在分布式计算上是失败了。另外,Map-Reduce 也不是一个很好的数据管理平台。将 SQL 放在 Map-Reduce 顶层导致性能惨不忍睹。所以说 Map-Reduce 无论是在数据管理还是在分布式计算上都基本算得上完败。那么是谁放弃了 Map-Reduce 呢?

谷歌在写 Map-Reduce 的时候,是专门针对他们的 Web 搜索数据库写的。他们在大概 2001 年就放弃了 Map-Reduce。而 Map-Reduce 当时设计所针对的应用,谷歌在五年后也将之放弃了。他们后来为其他项目开发了 Dremmel、F1 等不同系统。Map-Reduce 已淡出谷歌的视线,他们对之失去了兴趣,不想进一步去开发了。Cloudera 是 Hadoop 的一个主要供应商,他们也基本上放弃了 Map-Reduce。所以他们的新 SQL 数据库管理系统——Impala 并不是建立在 Map-Reduce 上的。HortonWorks 和 Facebook 也有类似的项目。那么,Hadoop 堆栈的未来究竟在哪里呢?

它可以用作底部的文件系统。但由于 HDFS 存在非常糟糕的性能问题,因此先要将这些问题解决掉才行。未来 SQL 将位于顶层,类似于 Impala 的系统。大家知道,数据仓库形式的数据库系统都要运行在 HDFS 之上。所以 Hadoop 市场内的数据仓库市场将会完全融合。在商业分析上也存在同样的情况。所以 Hadoop 在他们最新的营销演讲上提到了“数据湖”这个概念,待会我就会大概说一下。现在我想说的是,数据仓库市场和 Hadoop 市场基本上是同一个市场。
那么 Spark 表现得怎样呢?Spark 我认为很有意思。

Spark 的存在是为了以快于 Map-Reduce 的速度进行分布式计算。现在大家都不想要 Map-Reduce 了,Spark 的设计初衷是要解决一个没有人愿意解决的问题。所以出售 Spark 的商业公司 Databricks 很快就了解到,人们想要用 SQL。现在,Spark 有 70% 的访问量来自于 SparkSQL。

Spark 就是一个 SQL 市场。但不幸的是,Spark 压根儿不是一个 SQL 引擎。它没有事务,没有持久度,也没有索引。现在所有这些问题都将得到修复。所以 SparkSQL 可能会越来越像 Impala,像商业数据仓库实现。而且他们可能在数据仓库市场上与 Impala 以及现有的一些数据仓库厂商竞争。希望最好的系统能够笑到最后。Spark 的市场有 30% 是分布式计算,它的主要客户是 Scala。而且它的功能比 Map-Reduce 更强大。但是,Spark 数据的 RDD 格式并不是所有人都喜闻乐见的,所以很快 Databricks 就尝试采用一种R形式的数据结构——数据帧。因此 Spark 内部将发生翻天覆地的变化,请系好你的安全带。这是下一代的明星产品。但明年会怎样谁都不知道。Spark 的确有这样的意向。而且几乎可以肯定的是,它一定会进军数据仓库市场。我认为在商业智能领域的分析市场,其实有很多系统都做得非常好。而且 Spark 和 Hadoop 也将会进军这个市场,为它带来更多的产品。但最大的难题在于如何在数据管理的中心进行可扩展的分析。如果你决定要在这方面开展某项工作,你必须先解决好这个大难题。
Big Velocity 很快的处理速度

下面马上就到高速这个话题。现在的商业市场规则不断变化,这是个不错的现象。物联网正在通过传感器记录下所有有意义的东西。例如戴在你腕上的小腕带,它可以记录下你的生命特征。不管是赛跑中的马拉松选手,还是为数众多的野生鸟类和动物,都能一一记录下来。这些人或动物会将他们的状态或其他数据实时传送给我们。这就带来了海量的数据。我们都在使用智能手机作为移动平台,它发送数据的速度也是相当的快。物联网持续冲击着人们原有的基础设施——我们必须提速了。而在人们说要提速的时候,他们会遇到两种不同的问题。第一种问题我将之称为“大模式、小状态”。

当你要做电子交易时,华尔街的工作人员会在海量的数据中寻找一个模式。比如先找一只草莓,然后 0.1 秒后再找一条香蕉。这就是复杂事件处理(CEP)技术。另外也有一些商业系统,他们可以比较好地解决这个市场的需求。所以这并不是一个交易数据库市场,而只是打开一条消防水管,然后从喷出的水中寻找模式。我对第二种有关高速的问题更感兴趣,我将之称为“大状态、小模式”。

假设有一家电子交易公司,他们目前的交易量占纽约证交所总交易量的 10%。他们在纽约、伦敦、东京以及北京这里都设有电子交易专柜。这些电子交易专柜可以进行实时证券交易。这家公司的 CEO 想要确定自己相对于全球任一股票的价位。如果价位相对较高,那么他可以说,我的风险太高了。然后按下应急按钮来降低风险。也就是说,在风险高于一定水平的时候提醒我。注意这一次就不是在消防水管喷出的水中寻找模式了,而是确切地记录下世界各地每一次交易的影响。这是数据库中一个有关我当前全球位置的例子。此时哪怕你只是遗漏了一条消息,你的数据库也会变得毫无价值。所以你不能遗漏任何数据。一定不要遗漏任何数据。而且要非常快速、准确地记录我的状态。这看起来像是一个有关超高性能交易处理的问题。这是一个我非常有兴趣去研究的领域。

要解决这个问题,你可以运行任何一个商业关系型数据库系统,我将之称为老 SQL。所以你可以运行微软的 SQLserver。它就是其中一款老 SQL 大型应用。你也可以运行 NoSQL 系统。目前有 75 到 100 家厂商可以卖给你 NoSQL 系统。而且他们主张放弃 SQL 和 ACID。另外还有第三种解决方案,我将之称为新 SQL,那就是保留 SQL 和 ACID,但放弃老 SQL 厂商遗留下来的实现,以编写体积更小、速度更快的实现。待会我会分别解释这些方案。

现有的大型应用速度很慢。除了慢还是慢。如果你要在一秒内运行 100 万个交易,那么我劝你不必费劲在任何这些遗留实现上去尝试这样做。SQL 是可以的,但它对交易的实现实在是太慢了。我在 2007 年与其他人合作写了一篇名叫"Through the OLTP Looking Glass"的论文,上面明确解释了为什么老 SQL 无法在这样一个市场当中高性能运行。如需更多详情,大家可以看一下这篇文章。所以为什么不使用 NoSQL 系统呢?

关于 NoSQL 我想说两件事情。第一件是,如果你主张放弃 SQL,那么你就是主张使用低级的表示法,因为这是 SQL 编译后的结果。不要将赌注压在编译器上。我虽然白头发很多,但是我还记得我在刚入行的时候那些“白头”前辈对我说,你必须用 IBM 汇编器来写代码。这是因为,除非你能够控制机器上的所有寄存器,否则提速根本是不可能的。现在我们都知道这是多么的可笑。不要将赌注压在编译器上。高级语言是可以的。但低级表示法就不好了。40 年的数据库研究教会大家这个道理。而 NoSQL 那些人还没有完全明白这个道理。我们应该放弃 ACID。遗留厂商的传统交易实现实在是太慢了。真的。一种选择是放弃它们,但我并不是很支持这种做法。这是因为,如果你想将 100 美元从这里挪到那里,你必须要有交易才能做到。例如,比特币就是一个很好的例子,不少人因为 NoSQL 系统受到攻击而损失了很多钱。所以说, 如果你需要交易但又没有好的交易系统,那么你很容易就会被一些非常严重的漏洞陷入危险的境地。你所能做的就是对着用户代码抓狂。

所以我的预测是这样的,SQL 和 NoSQL 系统之后会合并在一起。NoSQL 是指 2012 年版本的 NoSQL。然后 NoSQL 厂商的营销人员就改口说,我们不仅有 SQL,还有 SQL 的替代方案,对于那些需要用 SQL 做的事情,我们还有其他的解决方案。在我看来,现在 NoSQL 就是尚未使用 SQL 的意思。因为 NoSQL 厂商已经了解到高级语言的好处,所以便开始在他们系统的上层编写高级语言。尤其是 Mongodb 和 Cassandra,它们基本上都实现了看起来与 SQL 几乎一样的高级语言。所以说如今 NoSQL 阵营已开始转向 SQL。而 SQL 人员也在他们的引擎中加入 JSON,这是 NoSQL 厂商的其中一项重要功能——JSON 数据类型的灵活性。所以我认为这两个市场将最终融合在一起,不使用 SQL 的引擎不再叫做 NoSQL。它们都是 SQL 的一种实现,只是使用了不同于其他厂商的特性而已。我个人对新 SQL 是非常喜欢的,因为交易对每个人来说都是非常有用的。现在的问题是,老厂商的交易实现存在很多问题,它们的速度实在是太慢了。但这并不表示你无法将速度提起来。

例如,VoltDB 是一款名叫“H-Store”的 MIT 系统的商业化版本,它比 TPC-C 上的老系统要快将近 100 倍。而且它的交易系统非常轻型,线程优化得很好。它是一款速度超快的主内存开源 SQL 引擎。微软的数据库系统——Hekaton 最近作为 SQL Server 14 的一部分捆绑推出,它就是新 SQL 的另一个实现。所以说,提升在目前来看是可能的,只要你不要使用那些三、四十年前的老系统。
接下来我要说的是数据流速快的问题。这个问题要么是流处理问题,要么就是高性能交易问题。对于高性能交易问题,已经开始有速度很快的实现了。但我认为,这里面的关键是如何让交易高速进行。在这方面我们有很多的想法,未来也有很大的改善空间。
Big Variety 数据来源多样性

好了,还有最后 9 分钟,我来谈谈多样性的问题。像联邦快递这样的典型企业一般会有 5000 个运营数据系统。联邦快递现在有一个数据仓库。但其中只有几个系统的数据纳入到了这个数据仓库当中。也就是说,这个典型的数据仓库只从 10 到 20 个系统那里收集数据。那么其余剩下的 4980 个系统该怎么办呢?像 Verizon 这样的大型电信公司拥有 10 万个运营系统。大企业要有许多运营系统,主要是因为他们分成了许多独立的业务部门,以便于业务的开展。而独立的业务部门会产生大量的独立数据。所以在大企业的内部有许多运营系统。当然,这其中还包括电子表格、网页、数据库等等。而且每个人都想从互联网获得天气信息,也要从各种公共数据源获取数据。所以他们需要扩展性,将大量运营数据系统进行整合。那么该怎么做呢?

在过去,市场的传统做法是提取、转换、载入数据,ETF 系统就是这样的。比如 Data Stage 或 Informatics,如果你听说过的话,他们就是做这个的大厂商。那具体怎么做呢?首先是提前创建一个全局模式。让你们当中最聪明的人去研究这个全局模式应该是怎样的。创建完成后,针对每一个你想要纳入到该全局模式的本地化数据源,派一名程序员去咨询数据系统的所有者,了解数据源中包含了什么内容,然后将这些内容映射到全局模式当中,再编写一个数据转换脚本,最后确定如何清理并删除数据源中的重复数据。如果有 20 个数据源的话,应该没问题。但由于这种做法需要提前创建一个全局模式,如果数据源太多的话就不好做了。你也需要一个受训良好的程序员去单独处理每个数据源,其中涉及了太多的人力。如今的 ETL 人员在卖一种叫做“主数据管理”的产品。它其实只是一个新的术语,指的就是上面那种做法。这时候已经无法再扩展了。而且,现在有许多企业不只想整合 20 个数据源这么简单,他们想要整合 1000 个或 3000 个数据源。比如做团购优惠券的网站 Groupon,他们正在建立一个全球小企业数据库,这些企业就是他们的客户。为此他们需要整合 1 万个数据源。所以他们实际上是以 1 万倍的规模去处理这个问题。而 ETL 根本不可能完成这个任务。这就是对系统可扩展性的巨大需求,传统的厂商无法解决这个问题。所以我认为, 在这个关键的领域我们需要有新的想法,需要去做研究,看看怎么去解决这个问题。

我加入过一家名为 Data Tamer 的初创公司,待会我 会在另一张幻灯片里面说明。他们有一种比较好的方式去做这种规模的数据。另外还有许多类似的初创企业,例如由来自 Berkeley 的 Joe Hellerstein 创立的 Trifacta。他们关注于每个数据科学家,注重数据策管问题。他们非常关心非程序员、可视化以及每个数据科学家的需求。但不管怎样,我都认为这是一个亟需创新想法的领域。

那么 Data Tamer 究竟是做什么的呢?他们是做数据策管的,对我来说,数据策管就是要在原处摄取数据,然后将数据转换为某种不同的表示形式,例如欧元转换为美元,或人民币转换为美元等。然后还要进行数据清理。基本上任何数据源都会有 10% 到 20% 的错误率。有些情况下人们会拼错人名或公司名字等等。然后你必须将多个数据源放到一起,对它们的属性进行映射对比。比如说你有一组员工的数据集。我也有一组员工数据集。你称之为薪金。我称之为工资。你填满了一行数据。然后发现有重复的数据,于是你要进行数据整合。数据策管就是这样的概念。在过去,数据策管的成本非常之高,是普通人无法逾越的大山。但如果你想做数据科学,你就必须翻过这座大山,完成所有的数据整理和勘误工作。如果使用传统的技术去做这项工作,所需的费用非常高。而且传统技术无法扩展。所以说这是一个很大的问题。那么 Data Tamer 究竟是做什么的呢?

我借用 Peter Lee 演讲稿里面的一段话。他们在统计学上应用机器学习,让机器找出那些我们无法找到的东西。这类似于将挂在低处的苹果全部摘掉。然后在需要人类帮助时,你必须去找这个领域的专家。你不能去问程序员。因为 ETL 的程序员不知道怎么解答这方面的问题。比如说 Data Tamer 有一个客户是 Novartis,是一家非常大的医药公司。他们对基因数据应用这项技术。ICE50 和 ICU50 是两个基因术语。他们是一样的东西吗?是否其中一个是另一个的笔误?他们是两个不同的基因术语吗?程序员对此一无所知。你必须去问基因领域的专家。Tamer 有一个专家搜索系统。当需要人类回答问题时,比如说创建培训数据,你必须去问这个领域的专家。你不能去问程序员。这样才能获得巨大的投资回报。这种方式比起使用传统技术要省钱。这是解决数据源多样性问题的一个可行方法。但我的建议是,这一点非常重要。如果你想研究这个问题,你必须去找一个真实的用户,例如阿里巴巴或华为。去拜访真实的用户,找出他们的数据策管问题在哪里,然后解决这个问题。因为在现实世界中,很多人都会先写一个算法,然后再想这个算法在现实世界中究竟好不好用。我觉得这个顺序反了。你应该先找出现实世界的数据,然后再修复这些数据。好了,时间不多了。但我刚才说了,我会谈一谈数据湖。

Hadoop 厂商现在的想法是,将所有数据放入一个基于 HDFS 的数据湖中,这样就万事大吉了。也就是说,将所有原始数据放入 HDFS,这就是他们所说的数据湖。注意这只是数据策管所摄取的数据块。其余部分才是难点所在,你还必须解决这些难点。所以,如果你采用 Hadoop 厂商的建议,将所有原始数据放入 HDFS 当中,你并非创建一个数据湖,而只是创建了一个数据沼泽。然后你必须进行数据策管,才能创建出一个可供你使用的数据湖。所以说,数据湖只是一个新的营销术语,它指的是数据策管所摄取的数据块。
总结:工欲善其事,必先利其器

最后总结一下,如果你想做大数据,想做 SQL 分析,你应该采用列存储。如果你想做智能分析,最好不要用过时的产品。我强烈建议你使用数组存储。但可能也会有其他解决方案。如果你遇到数据速度的问题,你需要找一个流处理产品,或高性能的 OLTP 系统,这取决于你手头上有什么资源。NoSQL 人员目前提供了一种不错的上手体验。他们的产品容易使用,而且他们正在转向 SQL。但你的公司现在已经有了大量类似的产品。一些遗留的厂商实现仍将存在,它们不会完全过时,但会逐渐被这些新技术所取代。与此同时,你仍然需要用到这些旧的技术。然后,你将拥有一个或多个数据策管系统,它们能够最大限度地解决数据源多样性方面的可扩展性问题。所以,你公司内部的堆栈中将产生大量的数据。最后我的建议是:“工欲善其事,必先利其器”。谢谢大家!
